logstash使用grok收集java日志
原文地址,转载请注明出处: https://blog.csdn.net/qq_34021712/article/details/79754356 ©王赛超
前言
上一篇介绍了Logstash filter Grok插件的基础语法 这次来介绍如何使用Grok来收集日志,为了方便我们学习Grok,本篇采用grok收集java日志。
入门使用
以下是一条完整的日志:
2018-03-23 23:59:50.023 com.ruubypay.miss.usercenter.config.SpringAOP [2ce52319-c66b-4886-8c75-3b693ce1f0eb] INFO =====>@AfterReturning:响应参数为:ModelsReturn{resData=null, resCode='A143', resMessage='用户未注册'}这些日志可以分为以下几部分组成:
日期 + java类全路径 + UUID + 日志主要内容
我们可以直接使用logstash附带的模式,Logstash附带约120个模式。你可以在这里找到它们https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
其中最基本的定义是在grok-patterns中,收集tomcat日志定义在java中,但是某些正则可能不适合我们字段,此时就需要我们来自定义,然后grok通过patterns_dir来调用即可。
对于上面的日志我们可以从java中可以找到我们想要的正则,对应正则如下:
20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) %{JAVACLASS} %{MYSELF} %{LOGLEVEL} %{MYSELF} 其中的 MYSELF [\s\S]* 是我们自定义的一个正则,使用%{MYSELF}调用,[\s\S]*表示匹配任意字符。
这是两个测试我们的正则是否正确的网址
http://grokconstructor.appspot.com/do/match(需要使用)
http://grokdebug.herokuapp.com/ 我们可以测试一下,看自己写的对不对,如下图:

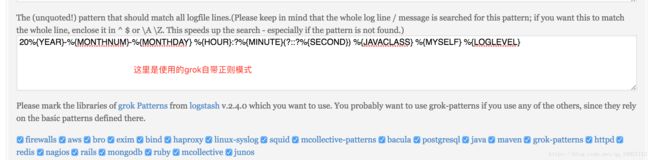
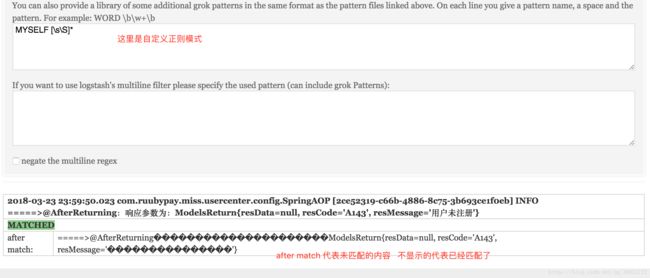
上面的图片中,为了讲解每个位置是干什么的,所以匹配模式 并没有写全,最后一段主要日志内容没有 匹配上。正则表达式学习:http://tools.jb51.net/regex/create_reg
全部匹配应该是如下情况:

在Logstash中使用grok
①在logstash中定义正则目录,并创建正则表达式文件
#创建文件夹
mkdir /usr/local/elk/logstash/patterns
#创建正则表达式文件
vim /usr/local/elk/logstash/patterns/tomcat
#粘贴一下内容到文件
MYSELF [\s\S]*
MYSELFTIMESTAMP 20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND})
GROKLOG %{MYSELFTIMESTAMP:timestamp} %{JAVACLASS:class} %{MYSELF:uuid} %{LOGLEVEL} %{MYSELF:message}注释:
MYSELF: 匹配任意字符串,包含空字符
MYSELFTIMESTAMP:自定义时间格式模式
GROKLOG: 收集log的完整模式,其中又调用了上面的 MYSELF模式 和MYSELFTIMESTAMP模式。
②配置logstash.conf
input {
file {
# 收集 elasticsearch 也就是java日志
path => "/usr/local/elk/elasticsearch/logs/es6.2.log"
type => "es-log"
# 从文件的尾部开始收集,如果从文件开始使用 beginning
start_position => "beginning"
}
}
filter {
grok {
patterns_dir => "/usr/local/elk/logstash/patterns"
#定义多个模式,其中一个不匹配,可以走另一个
match => {"message" => ["%{GROKLOG}","%{MYSELF:message}"]}
#将完整的日志message替换成 MYSELF匹配的message
overwrite => ["message"]
}
}
output {
elasticsearch {
hosts => ["http://172.20.1.187:9200"]
index => "es-log-%{+YYYY.MM.dd}"
#我这里安装了x-pack插件,所以需要用户名和密码,没安装x-pack的不需要
user => "elastic"
password => "123456"
}
}配置多模式
还有一些异常日志的结构如下:
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'ruubypayusercenter.user_ext_info' doesn't exist对于上面的这个异常,就和刚才我们的普通日志有所不一样,再使用上面的那个模式匹配.就无法匹配,所以我们需要配置多个模式,在第一个模式不匹配的情况下,执行第二个匹配,为了方便,第二个直接使用%{MYSELF} 我们通过配置为match属性配置了多个模式,来过滤不同的日志。
③重启logstash
④在es日志的末尾,手动添加以下日志,执行命令如下:
echo "2018-03-23 23:59:50.023 com.ruubypay.miss.usercenter.config.SpringAOP [2ce52319-c66b-4886-8c75-3b693ce1f0eb] INFO =====>@AfterReturning:响应参数为:ModelsReturn{resData=null, resCode='A143', resMessage='用户未注册'}" >> /usr/local/elk/elasticsearch/logs/es6.2.log⑤在head插件中,查看到的内容如下:
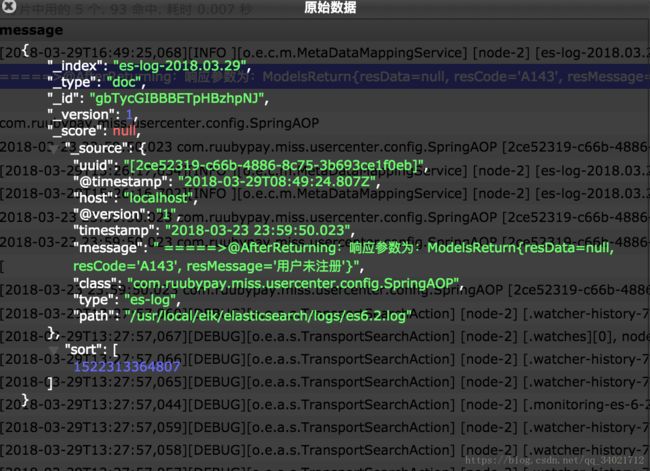
其中@timestamp 是默认的,timestamp 是自己定义的。
⑥输入一次纯错误的日志,测试多模式匹配
echo "### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'ruubypayusercenter.user_ext_info' doesn't exist" >> /usr/local/elk/elasticsearch/logs/es6.2.log⑦在head中插件查看

总结
以上就是使用grok收集java日志,丰富的过滤器插件的存在是 logstash 威力如此强大的重要因素。名为过滤器,其实提供的不单单是过滤的功能,它们扩展了进入过滤器的原始数据,进行复杂的逻辑处理,甚至可以无中生有的添加新的 logstash 事件到后续的流程中去!下面就可以在项目中使用了。