字典树(trie树)实现词频查找
碎碎念:
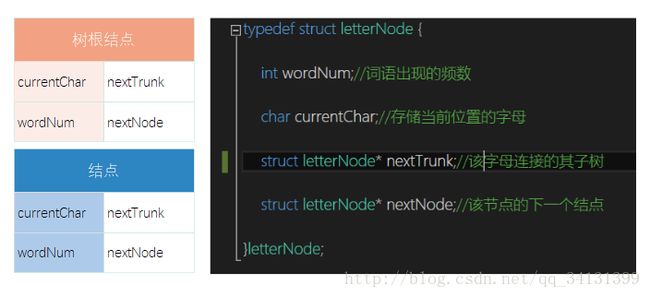
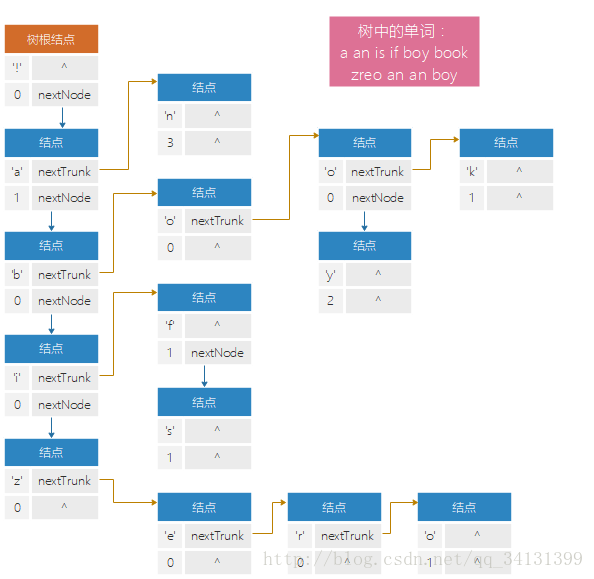
(注:树结构示例)
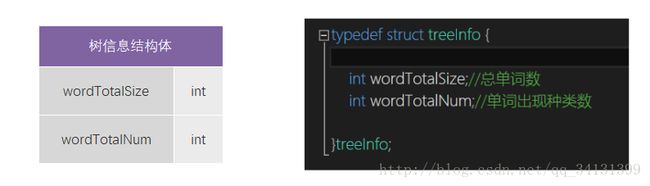
(树结点信息结构体 记录树的信息)
2.关键算法流程图

(主要方法一:分析文件)
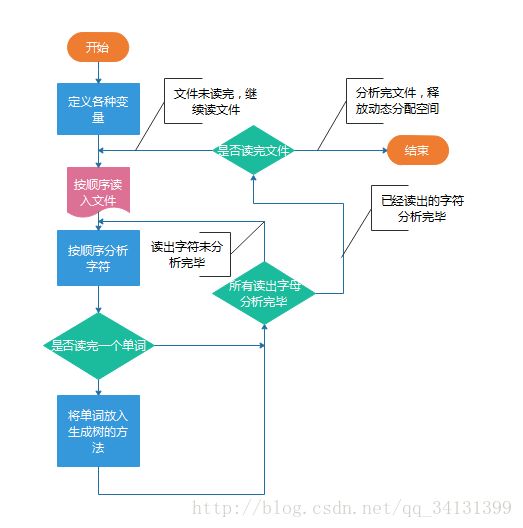
程序的大致流程

(主要方法二:将单词传入树)
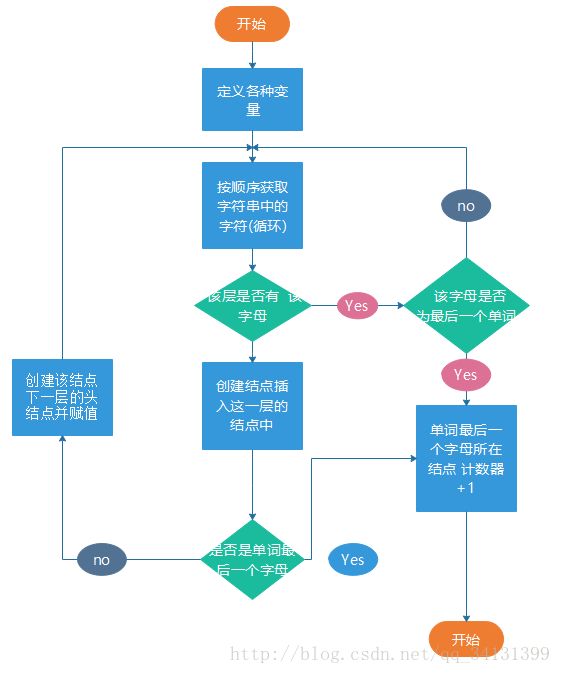
(主要方法二:将单词传入树)
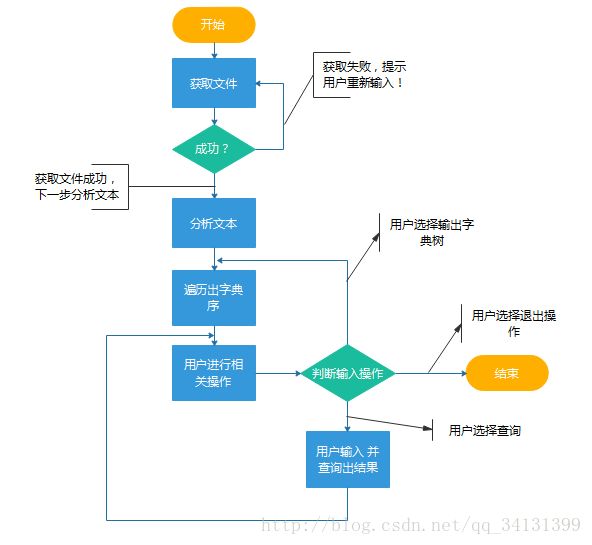
(注:主函数逻辑)
整体描述:
我们采用链、树、以及堆栈来完成题目要求,采用的树在理论上深度是可以无限加深的,所以单词长度是无限的。
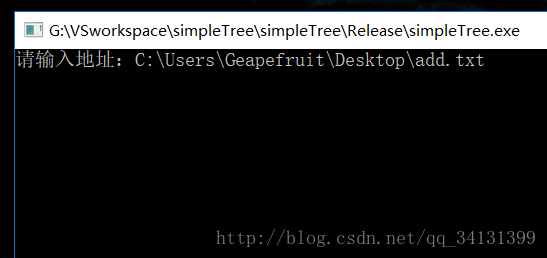
在操作上,先获取文件,用户输入文件路径,打开文件。
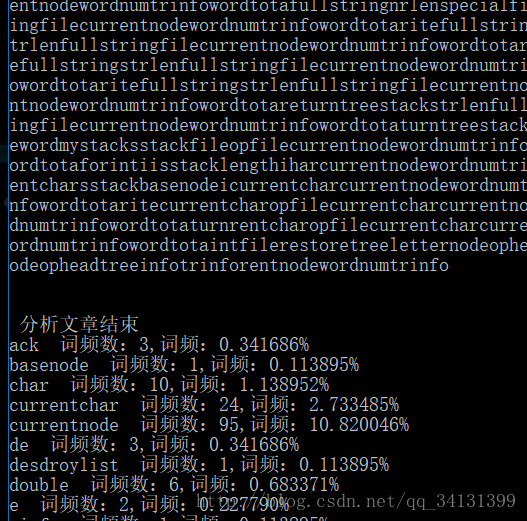
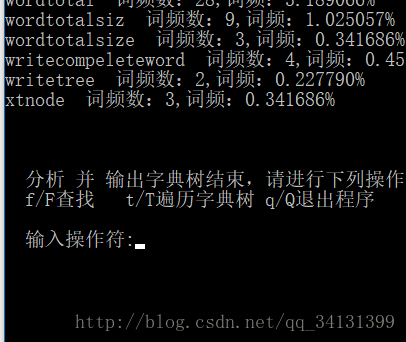
输入成功,打开文本进行分析,分析完毕进行树的遍历,按照字典序输出。
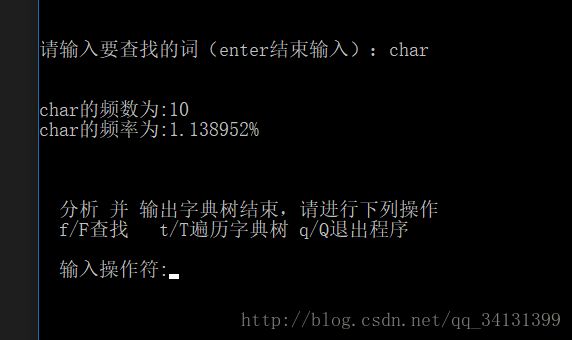
完成以上操作用户可以选择重新遍历树,也可以查找树中的某个单词,查询词频和词频数。
这里最关键的就是对树的构建,因为插入时会有bug下面贴一下我的代码,(因为我初学可能代码风格不是很好)
主要方法一:
//传入树以及字符串检测有就加数 没有就加结点
int magicFindWord(letterNode*opNode,char*opString, treeInfo*infoConter) {
//初始化变量
int max_string_length =MAX_STRING_LENGTH;
letterNode *currentNode=opNode;//记录当前操作的结点
letterNode *currentHeadNode = currentNode;//记录每一层的第一个结点
letterNode *trunkNode=NULL;
letterNode addNode;//需要添加的结点
int getWordNum = 0;
int areYouFind = 0;//记录查找的状态
for (int i =0;i
{
areYouFind= 0;
currentHeadNode= currentNode;//记录头结点
for (;currentNode;)//寻找插入位子 或者寻找单词完结点
{
if (currentNode->currentChar==opString[i])//在树中找到字母
{
areYouFind= 1;
if ((i+1 == strlen(opString)) || (i+1 == max_string_length))//找到并且是最后一个字母
{
currentNode->wordNum++;
infoConter->wordTotalSize++;
if (currentNode->wordNum==1)//找到后计数器加一
{
infoConter->wordTotalNum++;
}
getWordNum = currentNode->wordNum;
areYouFind = 100;
break;
}
break;
}
currentNode = currentNode->nextNode;
}
if (areYouFind==0)//没找到创建新结点
{
addNode.wordNum = 0;
if (i+1>=strlen(opString)||i+1>= max_string_length)//该字母为单词最后一个单词,计数器加一
{
addNode.wordNum= 1;
infoConter->wordTotalNum++;
infoConter->wordTotalSize++;
getWordNum= addNode.wordNum;
addNode.nextNode= NULL;
addNode.nextTrunk= NULL;
}
else//字母不是单词最后一个,创建下一层的头结点
{
trunkNode= (letterNode*)malloc(sizeof(letterNode));
trunkNode->currentChar=opString[i + 1];
trunkNode->wordNum= 0;
trunkNode->nextNode= NULL;
trunkNode->nextTrunk= NULL;
addNode.nextTrunk= trunkNode;
}
addNode.currentChar = opString[i];
insertNode(currentHeadNode, addNode);//在树(下一层的链中)中插入结点
currentNode = trunkNode;
}
if(areYouFind==1&&!currentNode->nextTrunk)//找到该单词并且下一层无结点
{
trunkNode = (letterNode*)malloc(sizeof(letterNode));//创建下一层的头结点
trunkNode->currentChar = opString[i + 1];
trunkNode->wordNum = 0;
trunkNode->nextNode = NULL;
trunkNode->nextTrunk = NULL;
currentNode->nextTrunk= trunkNode;
currentNode = currentNode->nextTrunk;
}elseif(areYouFind == 1)//找到该单词并且下一层有结点
{
currentNode = currentNode->nextTrunk;
}
if (areYouFind==100)
{
break;
}
}
return getWordNum ;
}
主要方法二:
//分析文件中的文本
int analysisText(letterNode*opNode,FILE*opFile, treeInfo*infoConter){
char toolCharArray[100];//用来读取文件中的字符
int letterNum=0;
int max_string_length =MAX_STRING_LENGTH;
char *opString;
opString = (char *)malloc((max_string_length+1)*sizeof(char));
opString[0] = 0;
opString[max_string_length] = 0;
int hh=0;
while (fgets(toolCharArray, 100,opFile) != NULL)//逐行读取opFile所指向文件中的内容到toolCharArray中
{
for (int i = 0; i < 100-1; i++)
{
if ((toolCharArray[i]>='a'&&toolCharArray[i]<='z')|| (toolCharArray[i] >= 'A'&&toolCharArray[i] <='Z'))//检测是否为字母
{
if (letterNum
{
if (toolCharArray[i]<97)//大写转小写字母
{
toolCharArray[i]+= 32;
}
opString[letterNum] = toolCharArray[i];
}
letterNum++;
}
else
{
if (letterNum>0)//检测到一个单词记录结束存入树中
{
if (letterNum
{
opString[letterNum]='\0';
}
printf("%s", opString);
magicFindWord(opNode,opString,infoConter);//放入树中
letterNum = 0;
}
}
}
}
free(opString);
opString = NULL;
return 0;
}
主方法:
int main() {
FILE* file = getAFile();//获取用户文件
//初始化结点信息树和信息记录
letterNode opNode;
treeInfo infoConter;
initTree(&opNode);
initTreeInfo(&infoConter);
//分析文件
analysisText(&opNode,file,&infoConter);
printf("\n\n\n分析文章结束\n");
//遍历产生字典树
traverseTree(&opNode, infoConter);
//获取用户想要的搜索结果*/
char useOpChar[100] = {'!'};
while (useOpChar[0]!='q'&& useOpChar[0] !='Q')
{
printf("\n\n\n 分析并 输出字典树结束,请进行下列操作");
printf("\n f/F查找 t/T遍历字典树 q/Q退出程序");
printf("\n\n 输入操作符:");
scanf_s("%s", &useOpChar, 10);
system("cls");
printf("\n\n");
switch (useOpChar[0])
{
case't':;
case'T': {traverseTree(&opNode, infoConter);break; }
case'f':;
case'F': {
char sss[100] ="you";
printf("请输入要查找的词(enter结束输入):");
scanf_s("%s", &sss, 100);
printf("\n\n%s的频数为:%d\n", sss,getWordNum(&opNode, sss));
double freque = (double)getWordNum(&opNode, sss) * 100 / infoConter.wordTotalSize;
printf("%s的频率为:%f%c \n", sss, freque, 37);
break; }
default: {break; }
}
}
destroyTree(&opNode, &infoConter);
return 0;
}
以下是运行结果截图(我把扫描到的字母也打印出来了,看起来可能会比较乱):