TensorFlow2.0 实现FM
一、数据集
Criteo : 2014年kaggle 广告点击率预估比赛数据集
- 该数据集包含约4500万条记录。有13个数值特征和26个类别特征。
- 这些列以制表符分隔,并带有以下格式:
... ... - 该数据集可从http://labs.criteo.com/2014/02/download-kaggle-display-advertising-challenge-dataset/获得。
- 将下载的“ train.txt”文件放在“ data / Criteo /”文件夹中。
二、数据预处理
dataPreprocess_TensorFlow.py
26个类别特征,每个类别拥有多个特征值,这里只保留特征值个数大于10个的特征。
得到训练集 feat_dict 的格式为:
train_idx :特征索引;train_value:特征值;train_label:标签。
对连续特征,把列号作为键,得到最终索引。
feat_dict = {}
tc = 1
# Continuous features
for idx in continuous_range_:
feat_dict[idx] = tc
tc += 1
对离散特征,具体到某个特征值,给予索引。
features = line.rstrip('\n').split('\t')
#for idx in categorical_range_:
if features[idx] == '' or features[idx] not in dis_feat_set:
continue
if features[idx] not in cnt_feat_set:
cnt_feat_set.add(features[idx])
feat_dict[features[idx]] = tc
tc += 1输出为三个文件
label 样本label
value 数值特征就是该列的数值,类别特征则赋值1 。
index 即特征值对应的索引。
对于数值特征 一个value ,index对为(23,3);对于类别特征 一个value,index对为(1,233)
三、FM层构造

class FM_layer(tf.keras.Model):
def __init__(self, num_feat, num_field, reg_l1=0.01, reg_l2=0.01, embedding_size=10):
super().__init__()
self.reg_l1 = reg_l1
self.reg_l2 = reg_l2 # L1/L2正则化并没有去使用
self.num_feat = num_feat # denote as M
self.num_field = num_field # denote as F
self.embedding_size = embedding_size # denote as K
# first order term parameters embedding
self.first_weights = tf.keras.layers.Embedding(num_feat, 1, embeddings_initializer='uniform')
self.bias = tf.Variable([0.0])
self.feat_embeddings = tf.keras.layers.Embedding(num_feat, embedding_size, embeddings_initializer='uniform')
def call(self, feat_index, feat_value):
# Step1: 先计算得到线性的那一部分
feat_value = tf.expand_dims(feat_value, axis=-1)
first_weights = self.first_weights(feat_index)
first_weight_value = tf.math.multiply(first_weights, feat_value)
first_weight_value = tf.squeeze(first_weight_value, axis=-1)
y_first_order = tf.math.reduce_sum(first_weight_value, axis=1)
# Step2: 再计算二阶部分
secd_feat_emb = self.feat_embeddings(feat_index) # None * F * K
feat_emd_value = tf.math.multiply(secd_feat_emb, feat_value) # None * F * K(广播)
# sum_square part
summed_feat_emb = tf.math.reduce_sum(feat_emd_value, axis=1) # None * K
interaction_part1 = tf.math.pow(summed_feat_emb, 2) # None * K
# squared_sum part
squared_feat_emd_value = tf.math.pow(feat_emd_value, 2) # None * K
interaction_part2 = tf.math.reduce_sum(squared_feat_emd_value, axis=1) # None * K
y_secd_order = 0.5 * tf.subtract(interaction_part1, interaction_part2)
y_secd_order = tf.math.reduce_sum(y_secd_order, axis=1)
output = y_first_order + y_secd_order + self.bias
output = tf.expand_dims(output, axis=1)
return outputnum_teature = 115475。即一共有115475个特征(数值特征+类别特征)。
feat_value = (2048,39),expand_dims之后(2048,39,1); 每个batch2048个样本,样本维度为39。
feat_index = (2048,39), self.frist_weights(feat_index)之后(2048,39,1)
first_weight_value = tf.math.multiply(first_weights, feat_value) 为wi*xifirst_weight_value = tf.squeeze(first_weight_value, axis=-1) squeeze 删除-1维度;即之后(2048, 39)y_first_order = tf.math.reduce_sum(first_weight_value, axis=1) 对axis=1进行求和,结果为(2048,),得到线性组合结果。2、计算二阶特征部分
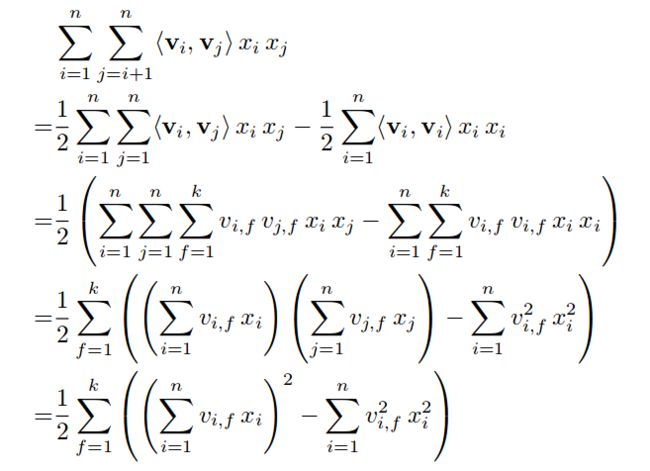
secd_feat_emb = self.feat_embeddings(feat_index) (2048,39,10)
feat_emd_value = tf.math.multiply(secd_feat_emb, feat_value) (2048,39,10) 得到 vi * xi
# 计算第一项
summed_feat_emb = tf.math.reduce_sum(feat_emd_value, axis=1) (2048,10)
interaction_part1 = tf.math.pow(summed_feat_emb, 2) (2048,10)
# 计算第二项
squared_feat_emd_value = tf.math.pow(feat_emd_value, 2) (2048,10)
interaction_part2 = tf.math.reduce_sum(squared_feat_emd_value, axis=1) (2048,10)
y_secd_order = 0.5 * tf.subtract(interaction_part1, interaction_part2)
y_secd_order = tf.math.reduce_sum(y_secd_order, axis=1) (2048,)四、损失函数优化
train_batch_dataset = get_batch_dataset(train_label_path, train_idx_path, train_value_path)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
output = model(idx, value)
loss = cross_entropy_loss(y_true=label, y_pred=output)
reg_loss = []
for p in model.trainable_variables:
reg_loss.append(tf.nn.l2_loss(p))
reg_loss = tf.reduce_sum(tf.stack(reg_loss))
loss = loss + model.reg_l2 * reg_loss
五、进行训练,对每个batch的训练集数据,调用一次train_one_step
@tf.function
def train_one_step(model, optimizer, idx, value, label):
with tf.GradientTape() as tape:
output = model(idx, value)
loss = cross_entropy_loss(y_true=label, y_pred=output)
reg_loss = []
for p in model.trainable_variables:
reg_loss.append(tf.nn.l2_loss(p))
reg_loss = tf.reduce_sum(tf.stack(reg_loss))
loss = loss + model.reg_l2 * reg_loss
grads = tape.gradient(loss, model.trainable_variables)
grads = [tf.clip_by_norm(g, 100) for g in grads]
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
return loss参考文献:
1、Kaggle实战——点击率预估
2、TensorFlow1.0 实现FM