Windows 10 安装使用TensorFlow-GPU
Windows 10 安装使用TensorFlow-GPU
当前环境描述:Win10 64位,Python3.6
目标:安装使用TensorFlow1.6-GPU
所需文件:Cuda9.0、Cudnn7.0
注意:安装Cuda9.1 & Cudnn7.1的环境下将不能正常使用TF1.6-GPU
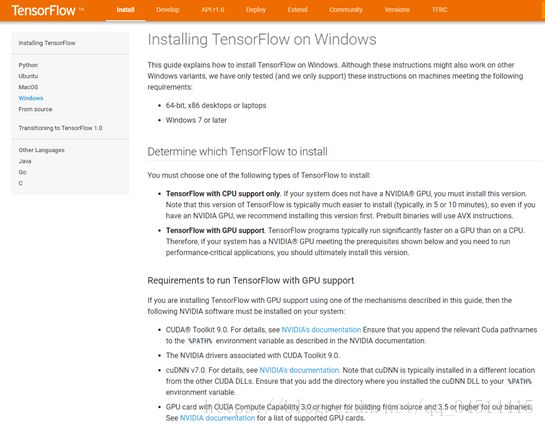
Tensorflow 官网安装描述如下:
网址:https://tensorflow.google.cn/install/install_windows
步骤:
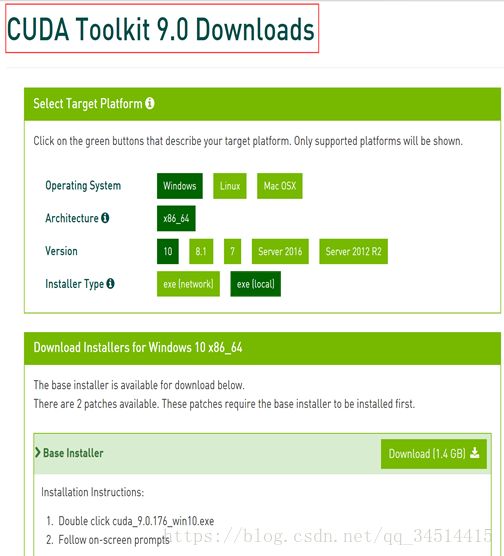
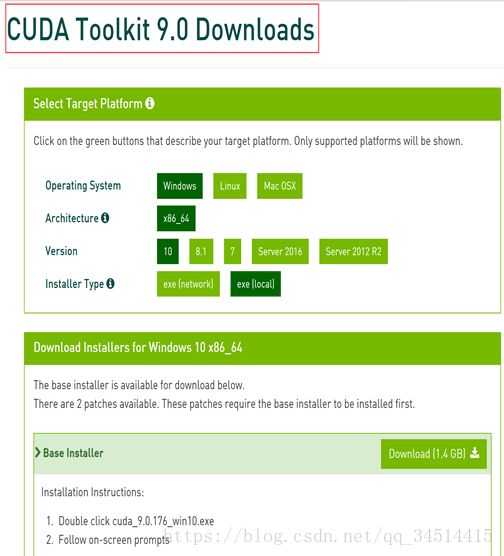
1、下载安装Cuda9.0
网址:https://developer.nvidia.com/cuda-90-download-archive?target_os=Windows&target_arch=x86_64&target_version=10
注意:搜索CUDA进入下载界面默认下载最新的9.1版本,
步骤:搜索cuda9,进入后点击下载,下载完成直接安装即可
2、下载安装Cudnn7.0、添加进path
网址:https://developer.nvidia.com/rdp/cudnn-download
注意:下载Cudnn会需要注册,并且完成问卷调查
步骤:下载完成后为安装包形式,解压后为复制到cuda9.0的路径
Cuda9.0默认路径为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0
3、安装TF1.6-GPU
步骤:直接pip install --upgradetensorflow-gpu

4、验证测试
安装好后打开python,
引用tensorflow,新建一个常量,再打印出来
语句如下:
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
若安装成功则会再运行sess = tf.Session()的时候出现自己的GPU型号等信息
截图如下: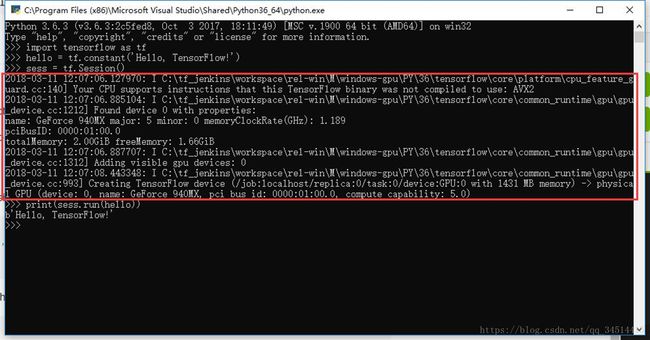
如果不能正常使用:
1、检查所有的版本是否正确,当前版本 win10 64位、python3.6、cuda9.0、cudnn7.0、tensorflow1.6-gpu
2、确认cuda的环境变量已经添加、如果还是不行再将cudnn解压后的cudnn/bin路径添加到环境变量
cuda 9.0 + vs2015 环境搭建




在Windows 10上搭建TensorFlow环境
在Windows 10上搭建TensorFlow环境
- 版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。
了解如何为受支持的GPU测试Windows系统,安装和配置所需的驱动程序,获取最新的TensorFlow每日构建版并确保其正常工作。
在前面的文章中,我展示了如何测试你的Linux系统,看看你是否能够按照带GPU支持的TensorFlow。在本文中,我将介绍如何在Windows 10上搭建TensorFlow环境。
同样,仍然需要Python环境和pip工具。
1、获取Python和pip
在Windows环境安装Python 3.x版本,通常安装包中集成了pip工具,安装会非常简单方便。具体见:https://www.python.org/downloads/windows/
一旦下载并执行,需要确保选择安装的自定义选项。可以看到如下界面: 
【CUDA】CUDA9.0+VS2017+win10详细配置
CUDA9.0是目前最新的Cuda版本,VS2017也是目前最新的Visual Studio版本,当前(2017/09)网上很少有CUDA9.0+VS2017的配置。
为什么非要用CUDA9.0呢?因为CUDA8.0是与VS2017不兼容的,就是说如果想用CUDA8.0,必须使用VS2015以下的VS版本。好消息是CUDA9.0开始兼容VS2017,以后CUDA9.0+VS2017将会成为一种趋势。
在参考以前的成功配置案例后,博主决定写写最新的配置教程,以供大家参考。
CUDA9.0安装:
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员现在可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是就可以在支持CUDA™的处理器上以超高性能运行。
首先是CUDA9.0RC的下载:https://developer.nvidia.com/cuda-release-candidate-download,由于还是测试版,所以需要NVIDIA开发人员计划的成员资格。需登录以获取访问权限并完成此免费加入程序的简短申请(网盘或者贴吧是很好的资源…)。

下载后我们将会得到这个exe文件:

下面是安装过程(按照默认安装):
在安装CUDA9.0之前,本人已经是安装好了VS2017,所以系统检查时显示无误,绿灯通过。
接下来就是同意继续下一步,等待CUDA安装的结束。
PS:如果要卸载旧版本的CUDA,可在控制面板中选择“程序和功能”,选择应用程序后右键卸载。至于注册表问题是否需要变动,博主卸载CUDA8.0后安装CUDA9.0并未发现问题。如果大家在安装过程中遇到问题,可百度或谷歌如何操作。
设置环境变量:
安装结束后,我们在计算机上点右键,打开属性->高级系统设置->环境变量,可以看到系统中多了CUDA_PATH和CUDA_PATH_V9_0两个环境变量。

我们还需要在环境变量中添加如下几个变量:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64 - 1
- 2
- 3
- 4
- 5
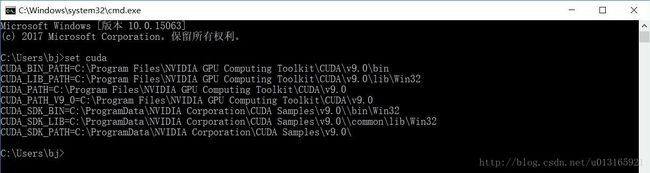
设置完成之后,我们可以打开cmd来查看。
下一步是监测cuda安装成功与否:
在cuda安装文件夹中有deviceQuery.exe 和 bandwidthTest.exe两个程序。首先启动cmd DOS命令窗口,默认进来的是c:\users\Admistrator>路径,输入 cd .. 两次,来到c:目录下输入dir 找到安装的cuda文件夹。
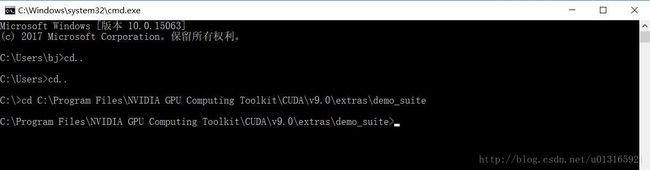
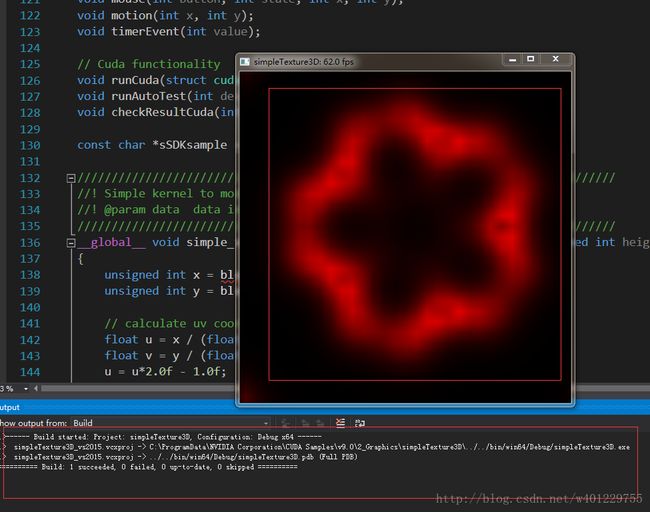
分别输入deviceQuery.exe 和 bandwidthTest.exe,运行结果如图所示。Rsult=PASS则说明通过,反之,Rsult=Fail 则需要重新安装。
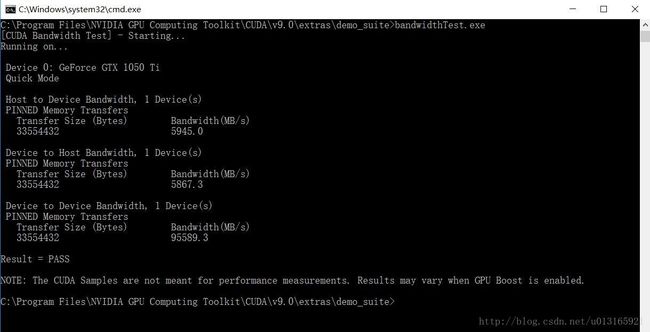
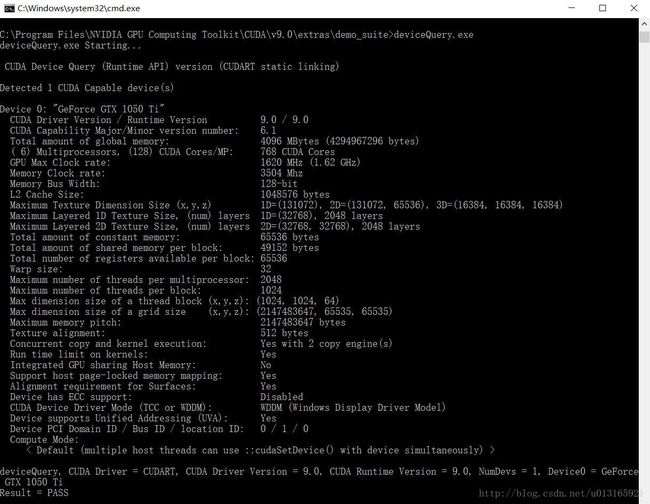
如果以上都没问题,则说明CUDA9.0安装成功。下一步是在VS2017平台上配置CUDA9.0。
VS2017配置:
1.打开vs2017,我们可以观察到,在VS2017模板一栏下方出现了“NVIDIA/CUDA 9.0”。创建一个空win32程序,即cuda_test项目。
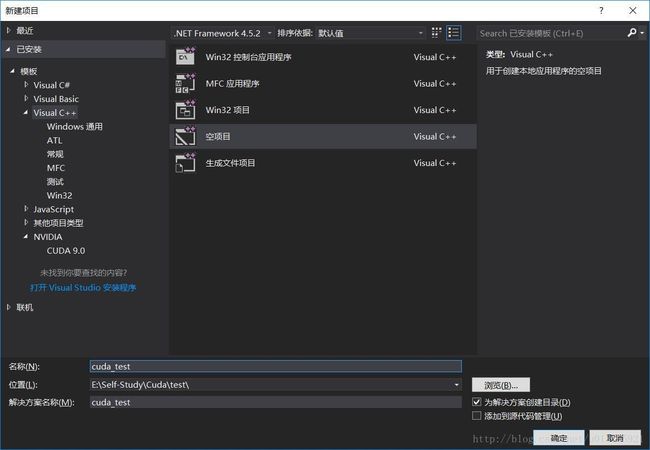
2.右键源文件文件夹->添加->新建项->选择CUDA C/C++File,取名cuda_main。

3.选择cuda_test,点击右键–>项目依赖项–>自定义生成,选择CUDA9.0。
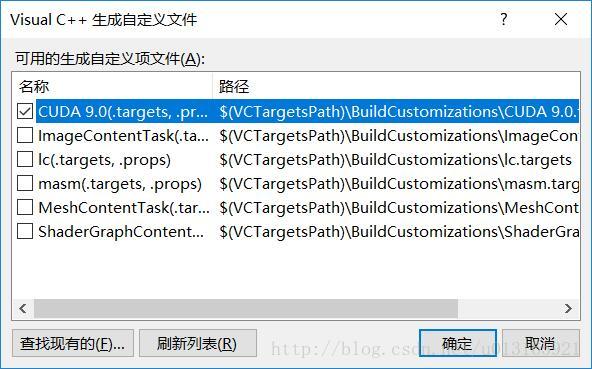
4.点击cuda_main.cu的属性,在配置属性–>常规–>项类型–>选择“CUDA C/C++”。

项目配置:
1.x64
1.1 包含目录配置
1.右键点击项目属性–>属性–>配置属性–>VC++目录–>包含目录
2.添加包含目录:
$(CUDA_PATH)\include
1.2 库目录配置
1.VC++目录–>库目录
2.添加库目录:
$(CUDA_PATH)\lib\x64
1.3 依赖项
配置属性–>链接器–>输入–>附加依赖项
添加库文件:
cublas.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
nvcuvid.lib
OpenCL.lib
注意:添加nvcuvenc.lib库文件,编译时,报找不到该文件的错误。去掉后,程序也能运行
2.x86(win32)
2.1 包含目录配置
右键点击项目属性–>属性–>配置属性–>VC++目录–>包含目录
添加包含目录:
$(CUDA_PATH)\include
2.2 库目录配置
1.VC++目录–>库目录
2.添加库目录:
$(CUDA_PATH)\lib\Win32
2.3 依赖项
配置属性–>连接器–>输入–>附加依赖项
添加库文件:
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
nvcuvid.lib
OpenCL.lib
备注: win32和x64位的lib库有差别,配置时需注意,除了上述添加的lib文件外,x64还有其他的lib库文件,如cublas.lib,如运行1.6的样例时,要添加这个库,不然会编译失败。
测试
// CUDA runtime 库 + CUBLAS 库
#include "cuda_runtime.h"
#include "cublas_v2.h"
#include
#include
using namespace std;
// 定义测试矩阵的维度
int const M = 5;
int const N = 10;
int main()
{
// 定义状态变量
cublasStatus_t status;
// 在 内存 中为将要计算的矩阵开辟空间
float *h_A = (float*)malloc (N*M*sizeof(float));
float *h_B = (float*)malloc (N*M*sizeof(float));
// 在 内存 中为将要存放运算结果的矩阵开辟空间
float *h_C = (float*)malloc (M*M*sizeof(float));
// 为待运算矩阵的元素赋予 0-10 范围内的随机数
for (int i=0; ifloat)(rand()%10+1);
h_B[i] = (float)(rand()%10+1);
}
// 打印待测试的矩阵
cout << "矩阵 A :" << endl;
for (int i=0; icout << h_A[i] << " ";
if ((i+1)%N == 0) cout << endl;
}
cout << endl;
cout << "矩阵 B :" << endl;
for (int i=0; icout << h_B[i] << " ";
if ((i+1)%M == 0) cout << endl;
}
cout << endl;
/*
** GPU 计算矩阵相乘
*/
// 创建并初始化 CUBLAS 库对象
cublasHandle_t handle;
status = cublasCreate(&handle);
if (status != CUBLAS_STATUS_SUCCESS)
{
if (status == CUBLAS_STATUS_NOT_INITIALIZED) {
cout << "CUBLAS 对象实例化出错" << endl;
}
getchar ();
return EXIT_FAILURE;
}
float *d_A, *d_B, *d_C;
// 在 显存 中为将要计算的矩阵开辟空间
cudaMalloc (
(void**)&d_A, // 指向开辟的空间的指针
N*M * sizeof(float) // 需要开辟空间的字节数
);
cudaMalloc (
(void**)&d_B,
N*M * sizeof(float)
);
// 在 显存 中为将要存放运算结果的矩阵开辟空间
cudaMalloc (
(void**)&d_C,
M*M * sizeof(float)
);
// 将矩阵数据传递进 显存 中已经开辟好了的空间
cublasSetVector (
N*M, // 要存入显存的元素个数
sizeof(float), // 每个元素大小
h_A, // 主机端起始地址
1, // 连续元素之间的存储间隔
d_A, // GPU 端起始地址
1 // 连续元素之间的存储间隔
);
cublasSetVector (
N*M,
sizeof(float),
h_B,
1,
d_B,
1
);
// 同步函数
cudaThreadSynchronize();
// 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。
float a=1; float b=0;
// 矩阵相乘。该函数必然将数组解析成列优先数组
cublasSgemm (
handle, // blas 库对象
CUBLAS_OP_T, // 矩阵 A 属性参数
CUBLAS_OP_T, // 矩阵 B 属性参数
M, // A, C 的行数
M, // B, C 的列数
N, // A 的列数和 B 的行数
&a, // 运算式的 α 值
d_A, // A 在显存中的地址
N, // lda
d_B, // B 在显存中的地址
M, // ldb
&b, // 运算式的 β 值
d_C, // C 在显存中的地址(结果矩阵)
M // ldc
);
// 同步函数
cudaThreadSynchronize();
// 从 显存 中取出运算结果至 内存中去
cublasGetVector (
M*M, // 要取出元素的个数
sizeof(float), // 每个元素大小
d_C, // GPU 端起始地址
1, // 连续元素之间的存储间隔
h_C, // 主机端起始地址
1 // 连续元素之间的存储间隔
);
// 打印运算结果
cout << "计算结果的转置 ( (A*B)的转置 ):" << endl;
for (int i=0;icout << h_C[i] << " ";
if ((i+1)%M == 0) cout << endl;
}
// 清理掉使用过的内存
free (h_A);
free (h_B);
free (h_C);
cudaFree (d_A);
cudaFree (d_B);
cudaFree (d_C);
// 释放 CUBLAS 库对象
cublasDestroy (handle);
getchar();
return 0;
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
运行结果如图所示,说明配置已经完成且能正常运行程序。

完成安装后,可以打开命令提示符并键入python,以查看您正在使用的版本。这里可以看到,我下载了3.6.4版: 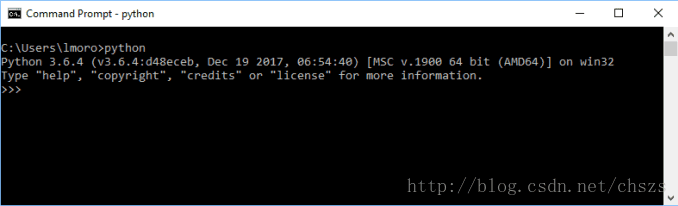
然后可以退出Python解释器环境:
exit()
- 1
- 2
然后测试pip工具安装的情况:
pip -V
- 1
- 2
可以看到这样: 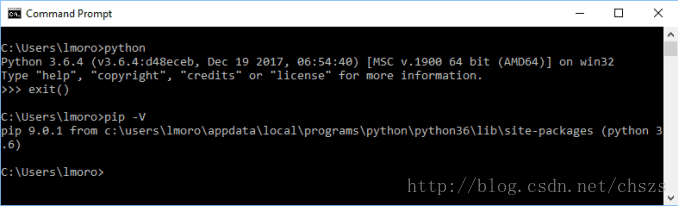
接下来,在安装TensorFlow之前,需要先检查主机的GPU是否支持,在命令提示符下,执行命令:
control /name Microsoft.DeviceManager
- 1
- 2
然后查看“显示适配器”设置,将其打开,然后阅读显示适配器的名称,如下: 
正如你所看到的,主机系统有一个GTX 980 Ti。然后去NVIDIA官网查看信息,具体见:https://developer.nvidia.com/cuda-gpus,就可以知道是否可以使用带GPU支持的TensorFlow。这里已经确定是支持的。但是在安装和运行TensorFlow之前,需要为你的机器安装CUDA驱动。
2、安装CUDA驱动程序
要说明一点,目前TensorFlow的每日构建版提供了对CUDA 9.0的支持,而Release版则只能支持CUDA 8.0版。如果访问CUDA的下载网站,见:https://developer.nvidia.com/cuda-toolkit,可以看到CUDA目前的最新版本是9.1版,因此请确保通过选择下面的“Legacy Releases”链接来下载正确版本的驱动程序。
在运行TensorFlow之前,还需要一个与主机的CUDA版本相匹配的CuDNN版本。
3、安装TensorFlow
安装TensorFlow的Nightly Build版。从命令提示符下安装它,只需输入:
pip install tf-nightly-gpu
- 1
- 2
一旦安装完成,在命令提示符窗口中输入:
python
- 1
- 2
打开Python编辑器,在其中输入:
import tensorflow as tf
- 1
- 2
如果CUDA驱动程序有错误,就可能会显示 cudart64_XX.dll 失败,其中XX是版本号。
如果CUDA驱动程序正确,但CuDNN驱动程序有错误,就可能会显示说 cudnn64_X.dll 缺少什么东西,其中X是一个版本号。
4、安装CuDNN库
CuDNN库是CUDA针对深度神经网络的更新包,TensorFlow会使用它用于加速NVidia GPU上的深度学习。可以从这里下载,见:https://developer.nvidia.com/cudnn。
但必须首先要注册一个NVidia开发者帐号,它是免费的。登录后,您会看到各种CuDNN下载。然后选择匹配的版本。由于之前使用了CUDA 9.0,所以确定为CUDA 9.0选择了cuDNN v7.0.5。 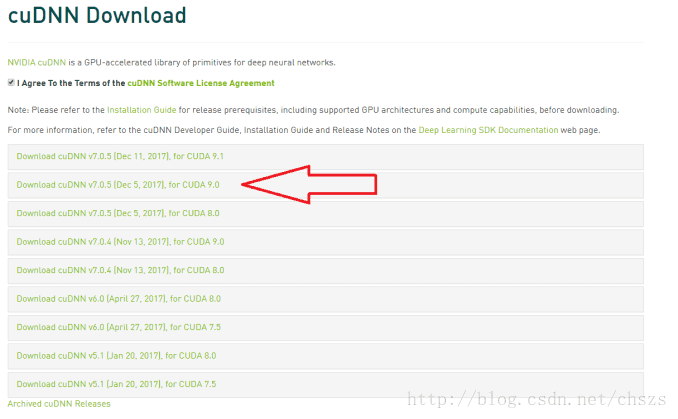
下载下来的是一个包含了几个文件夹的ZIP文件,每个文件夹包含CuDNN文件(一个DLL,一个头文件和一个库文件)。找到你的CUDA安装目录,这里应该是这样的:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0
- 1
- 2
可以看到从ZIP文件的目录也在这个目录,即有一个bin、一个include,一个lib等。将文件从ZIP复制到相关的目录。
比如把cudnn64_7.dll文件拖拽到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin目录,其它相似。
完成后,重新打开命令提示符窗口并再次测试TensorFlow!
import tensorflow as tf
- 1
- 2
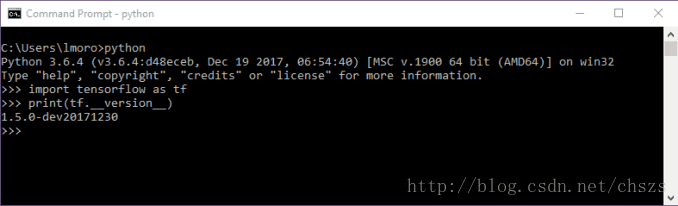
然后,可以输入以下内容来检查TensorFlow版本:
print(tf.__version__)
- 1
- 2
可以看到TensorFlow的版本得以正确显示: