Multi-task中的多任务loss平衡问题
Multi-task learning MTL 中的多任务loss平衡问题
- 背景
- 7 Nov 2017 - GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
- 19 May 2017 - Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
- 10 Oct 2018 - Multi-Task Learning as Multi-Objective Optimization
- 该文的方法
背景
multi-task的损失函数:
L ( t ) = ∑ w i ( t ) L i ( t , θ ) L(t)=\sum{w_i(t)L_i(t,\theta)} L(t)=∑wi(t)Li(t,θ)
在multi-task训练中存在着:
- 如何平衡各个任务损失的权重,
- 对于不同的任务的loss梯度之间的大小关系如果平衡,
- 各任务学习率如何控制.
这些问题影响mult-task训练的最终效果. 处理不当, 很有可能一个task学的很好, 其他task学的很差.
三个问题是相通的.
7 Nov 2017 - GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
论文地址
GradNorm的解决方法, 将 w i w_i wi作为可学习的参数.
目标是:
- 在不考虑学习率的情况下, 尽量使得各个task的 w i ( t ) L i ( t , θ ) w_i(t)L_i(t,\theta) wi(t)Li(t,θ)对于参数 θ \theta θ的gradient都与平均值接近.
- 学习不充分的task, 给与比其他task更大的学习率.
t t t时间task i i i的 θ \theta θ梯度:
G θ ( i ) ( t ) = ∥ ▽ θ w i ( t ) L i ( t , θ ) ∥ 2 G_\theta^{(i)}(t)=\Vert \bigtriangledown_{\theta}w_i(t)L_i(t,\theta)\Vert_2 Gθ(i)(t)=∥▽θwi(t)Li(t,θ)∥2
所有task对 θ \theta θ的平均梯度:
G ‾ θ ( t ) = E t a s k [ G θ ( i ) ( t ) ] \overline{G}_\theta(t)=E_{task}[G_\theta^{(i)}(t)] Gθ(t)=Etask[Gθ(i)(t)]
对于学习率, 定义若干个变量:
定义一个loss相对于初始化时的占比, 优化程度.
L ~ i ( t ) = L i ( t ) / L i ( 0 ) \widetilde{L}_i(t)=L_i(t)/L_i(0) L i(t)=Li(t)/Li(0)
定义一个比率值, 衡量task i i i相对于所有task的优化程度. 值越大, 表明优化程度相对于其他task 优化程度不够.
r i ( t ) = L ~ i ( t ) / E t a s k [ L ~ i ( t ) ] r_i(t)=\widetilde{L}_i(t)/E_{task}[\widetilde{L}_i(t)] ri(t)=L i(t)/Etask[L i(t)]
最后定义一个损失函数, 用来作为 w i w_i wi的优化目标函数:
L g r a d ( t ; w i ( t ) ) = ∑ i ∣ G θ ( i ) ( t ) − G ‾ θ ( t ) × [ r i ( t ) ] α ∣ 1 L_{grad}(t; w_i(t)) = \sum_{i}\vert G_\theta^{(i)}(t)-\overline{G}_\theta(t)\times [r_i(t)]^\alpha \vert_1 Lgrad(t;wi(t))=i∑∣Gθ(i)(t)−Gθ(t)×[ri(t)]α∣1
每次求上式对 w i w_i wi的导数时, 固定 G ‾ θ ( t ) × [ r i ( t ) ] α \overline{G}_\theta(t)\times [r_i(t)]^\alpha Gθ(t)×[ri(t)]α的值, 所求的对 w i w_i wi的梯度用来更新 w i w_i wi的值.在每次更新之后. 需要对 w i w_i wi进行normalization, 使得:
∑ i w i ( t ) = T \sum_i w_i(t) = T i∑wi(t)=T
w i w_i wi初始化时赋值为1, 即 w i ( 0 ) = 1 w_i(0) = 1 wi(0)=1
19 May 2017 - Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
论文地址
方法比较简单, 假设也很合理:
如果是回归问题, f w ( x ) f^w(x) fw(x)为模型输出:
则假设label 似然概率 y y y符合高斯分布:
p ( y ∣ f w ( x ) ) = N ( f w ( x ) , σ 2 ) p(y|f^w(x))=\mathcal{N}(f^w(x), \sigma^2) p(y∣fw(x))=N(fw(x),σ2)
如果是分类问题, 最终class y y y的概率为:
p ( y ∣ f w ( x ) ) = s o f t m a x ( f w ( x ) ) p(y|f^w(x))=softmax(f^w(x)) p(y∣fw(x))=softmax(fw(x))
这里面的 y y y可以为一个向量. 比如序列问题中.
多个task( K K K个), 希望整体概率最大.
p ( y 1 , . . . , y K ∣ f w ( x ) ) = p ( y 1 ∣ f w ( x ) ) × . . . × p ( y K ∣ f w ( x ) ) p(y_1, ...,y_K|f^w(x))=p(y_1|f^w(x))\times...\times p(y_K|f^w(x)) p(y1,...,yK∣fw(x))=p(y1∣fw(x))×...×p(yK∣fw(x))
又:
如果是回归问题:
log p ( y ∣ f w ( x ) ∝ − 1 2 σ 2 ∥ y − f w ( x ) ∥ 2 − log σ \log p(y|f^w(x) ∝ −\frac{1}{2\sigma^2}\|y − f^w(x)\|^2 − \log ^\sigma logp(y∣fw(x)∝−2σ21∥y−fw(x)∥2−logσ
如果是分类问题, c ∈ C c\in C c∈C, 假设 c ^ \hat{c} c^为正确分类:
log p ( y = c ^ ∣ f W ( x ) , σ ) = 1 σ 2 f c ^ W ( x ) − log ∑ c e x p ( 1 σ 2 f c W ( x ) ) \log p(y = \hat{c}|f^W(x), \sigma) =\frac{1}{\sigma^2}f^W_{\hat{c}}(x) − \log \sum_{c}{exp({\frac{1}{\sigma^2}f^W_c(x)})} logp(y=c^∣fW(x),σ)=σ21fc^W(x)−logc∑exp(σ21fcW(x))
分类问题时, 还有一个用来简化优化目标的的近似替换, 具体见论文.
因此最终的log似然损失函数可以将分类和回归问题通过一个公式表达:
log p ( y 1 ∣ f w ( x ) ) + . . . + log p ( y K ∣ f w ( x ) ) \log p(y_1|f^w(x)) +...+\log p(y_K|f^w(x)) logp(y1∣fw(x))+...+logp(yK∣fw(x))
10 Oct 2018 - Multi-Task Learning as Multi-Objective Optimization
论文地址
这篇文章的效果声称能够赛过前两篇:
第三个是文中第二个方法.

基本的想法是, 寻找多目标优化的帕累托最优解.

帕累托最优的定义:

帕累托最优解不止一个:
如下图: 由 C → A C\rightarrow A C→A 或者由 C → B C\rightarrow B C→B都是一个pareto optimize, 但A与B互相不是.


多任务的帕累托最优求解方法:
MGDA (multiple-gradient descent algorithm) 算法.
- 第一个条件是对 θ s h \theta^{sh} θsh求导.
- 第二个条件是对 θ t \theta^{t} θt求导.

这个算法参见论文:
Multiple-gradient descent algorithm (MGDA) for multiobjective optimization
但这边论文提出MGDA算法在面对神经网络的庞大参数时存在两个问题:
- 对高纬度梯度不是很试用(not scale gracefully)
- 需要对每个task计算梯度
所以本文提出了一种使用Frank-Wolfe-based optimizer的算法来处理这两个问题. 只需要一次backward explicit task-specific gradients 能计算出MGDA的一个上界, 使用这个上界, 能够得出帕累托最优的结果.
该文的方法
对于公式3, 如果是两个task:
![]()
有解析解为:
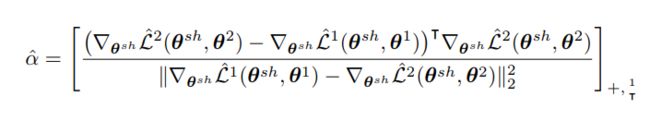
更一般的解法, 使用Frank wolfe 算法:

这个算法看的不是很懂, 可能需要看一下MGDA算法才能明白.
- e t ^ \mathcal{e}_{\hat{t}} et^ 是什么.
- 第10步和11步是怎么来的.
- M矩阵从哪里冒出来的.
参考:
- 原始frank wolfe算法