Tensorflow2.0之dataset读取csv及tfrecord文件(第四节)
本章节的主要内容是csv文件的读入(写入直接用pandas即可),tfrecords文件的写入及读取(读入是解析成可以训练的数组形式)
- csv文件读入
list_files = ['a.csv','b.csv','c.csv']
csv_dataset = tf.data.Dataset.list_files(list_files)
csv_dataset = csv_dataset.interleave(
lambda filename: tf.data.TextLineDataset(filename).skip(1),
cycle_length = 2
)
def parse_csv_line(line):
fields = tf.io.decode_csv(line, record_defaults=[1]*2 )
return tf.stack(fields)
csv_dataset = csv_dataset.map(parse_csv_line)
for line in csv_dataset:
print(line.numpy())
- 写入tfrecords
example = tf.train.Example(
features = tf.train.Features(
feature = {
'input_feature': tf.train.Feature(float_list = tf.train.FloatList(value=[-1.2, 0, 1.3])),
'label': tf.train.Feature(int64_list = tf.train.Int64List(value=[0, 0, 1]))
}
)
)
serialized = example.SerializeToString()
with tf.io.TFRecordWriter('train.tfrecords') as w: w.write(serialized)
- 批量读取tfrecords
list_files = ['train.tfrecords'] * 3
tfrecords_dataset = tf.data.Dataset.list_files(list_files)
tfrecords_dataset = tfrecords_dataset.interleave(
lambda filename: tf.data.TFRecordDataset(filename),
cycle_length = 2
)
def parse_tfrecords(serialized_example):
features = {
'input_feature':tf.io.FixedLenFeature([3], dtype=tf.float32),
'label': tf.io.FixedLenFeature([3], dtype=tf.int64) }
example = tf.io.parse_single_example(serialized_example, features=features)
return example['input_feature'], example['label']
tfrecords_dataset = tfrecords_dataset.map(parse_tfrecords)
for feature, label in tfrecords_dataset:
print(feature.numpy(), label.numpy())

-----------------------以下是具体例子-------------------------
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import os
import sys
import time
import sklearn
from tensorflow import keras
import tensorflow as tf
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
2.0.0
sys.version_info(major=3, minor=7, micro=3, releaselevel=‘final’, serial=0)
matplotlib 3.0.3
numpy 1.16.2
pandas 0.24.2
sklearn 0.20.3
tensorflow 2.0.0
tensorflow_core.keras 2.2.4-tf
4.1 data_API的引入
4.11 from_tensor_slices的三种接收方.
- 接收向量
# from_tensor_slices 读取向量 变成datase,dataset:包含了Tensor的set集合
dataset = tf.data.Dataset.from_tensor_slices(np.arange(3))
for item in dataset:
print(item)

2. 接收元祖
x = np.array([[1,2], [3,4], [5,6]])
y = np.array(['cat', 'dog', 'fix'])
dataset3 = tf.data.Dataset.from_tensor_slices((x, y))
for item_x, item_y in dataset3:
print(item_x.numpy(), item_y.numpy())
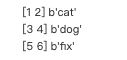
3. 接收字典
dataset4 = tf.data.Dataset.from_tensor_slices({'feature':x, 'label':y})
for item in dataset4:
print(item['feature'].numpy(), item['label'].numpy())

ps
# 如果x为元祖,那么输出item_x仍然为元祖,并且1,3,'cat' 作为一行输出,与当下面的x为字典时一样,注意与上面第二种输出比较
x = ([1,2], [3,4])
y = ['cat', 'dog']
for item_x, item_y in tf.data.Dataset.from_tensor_slices( (x , y) ):
print(item_x, item_y )

x ={'a':[1,2], 'b':[3,4]}
y = ['cat', 'dog']
for item_x, item_y in tf.data.Dataset.from_tensor_slices( (x , y) ):
print(item_x, item_y )
![]()
4.12 dataset.interleave接口
dataset = tf.data.Dataset.from_tensor_slices(np.arange(5))
dataset = dataset.repeat(3).batch(7)
for item in dataset:
print(item)

dataset2 = dataset.interleave(
lambda v: tf.data.Dataset.from_tensor_slices(v), #,map_fn
cycle_length = 2, # cycle_length #
block_length = 3, # block_length 每个block的长度
)
for item in dataset2:
print(item)

**interleave接口备注
interleave( map_func,cycle_length=AUTOTUNE, block_length=1, num_parallel_calls=None)
- 从dataset中取出cycle_length个元素
- 对这些element apply map_func,得到cycle_length个新的Dataset对象。
- 从这些新生成的Dataset对象中取数据 ( 轮流从每个对象里面取数据,每次取block_length个数据)
- 当这些新生成的某个Dataset的对象取尽时,从原Dataset中再取cycle_length个element,,然后apply map_func,
以此类推,最终整合成一个新的dataset**
4-4 tf.io.decode_csv读取csv文件
train_filenames[:2]
解析csv文件共3个步骤
train_filenames[:2]
![]()
- 1.文件名 -> dataset (以便用interleave的map方法)
filename_dataset = tf.data.Dataset.list_files(train_filenames)
for filename in filename_dataset:
print(filename)
break
![]()
- 2.使用interleave和TextLineDataset批量读取文件
# 选出5个文件用TextLineDataset读取,每次从五个文件读取一行拼接直至所有文件读完
dataset = filename_dataset.interleave(
lambda filename: tf.data.TextLineDataset(filename).skip(1), # 读取文件,每行为一个Tensor组成dataset
cycle_length = 5
)
for line in dataset.take(2):
print(line)

- 3.解析csv,将字符串解析成tensor数组
def parse_csv_line(line, n_fields=9):
defs = [tf.constant(np.nan)] * n_fields # np.nan 使得解析的值为浮点型
parsed_fields = tf.io.decode_csv(line, record_defaults=defs) # 将line中的内容以逗号为分隔符变成每一个Tensor组合成列表,元素类型为defs
x = tf.stack(parsed_fields[:-1]) # 将列表中每一个Tensor合并成一个新的Tensor(numpy为array),
y = tf.stack(parsed_fields[-1:])
return x,y
– 示例
import pprint
a = tf.io.decode_csv(tf.Variable('1,2,3,4'), record_defaults=[tf.constant(np.nan)]*4 )
pprint.pprint(a)
pprint.pprint(tf.stack(a))

----------------------接下来写个函数封装下与tf.keras结合-----------------
# 写一个函数批量读取csv文件合并为一个dataset,并转换为Tensor格式
def csv_reader_dataset(filenames, n_readers = 5, batch_size=32, n_parse_thread=5, shuffle_buffer_size=10000):
dataset = tf.data.Dataset.list_files(filenames)
dataset = dataset.repeat()
dataset = dataset.interleave(
lambda filename: tf.data.TextLineDataset(filename).skip(1),
cycle_length=n_readers
)
dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(parse_csv_line, num_parallel_calls=n_parse_thread)
return dataset.batch(batch_size)
batch_size = 32
train_set = csv_reader_dataset(train_filenames, batch_size=batch_size)
valid_set = csv_reader_dataset(valid_filenames, batch_size=batch_size)
test_set = csv_reader_dataset(test_filenames, batch_size=batch_size)
# 与tf.keras结合
model = keras.models.Sequential([
keras.layers.Dense(30, activation = 'relu',
input_shape = [8]),
keras.layers.Dense(1),
])
model.compile(loss='mean_squared_error', optimizer='sgd')
callbacks = [keras.callbacks.EarlyStopping(patience=3, min_delta=1e-2)]
model.fit(train_set,
validation_data = valid_set,
steps_per_epoch = len(train_data) // batch_size,
validation_steps = len(valid_data) // batch_size,
epochs = 100,
callbacks = callbacks)
# model.evaluate(test_set, steps=len(test_data)//batch_size)

4-6 tfrecord基础API的使用¶
- 1.构建一个tfrecord文件
# tfrecord 文件格式
# -> tf.train.Example(features = tf.train.Features)
# -> tf.train.Features(feature = {'key': tf.train.Feature})
# -> tf.train.Feature(bytes_list = tf.train.ByteList) /FloatList/Int64List
favourite_books_bytelist = tf.train.BytesList(value = [name.encode('utf-8') for name in ['ML', 'DL']])
hours_floatlist = tf.train.FloatList(value= [1.2, 1.6, 3.5])
age_intlist = tf.train.Int64List(value = [32])
example = tf.train.Example(
features = tf.train.Features(
feature = {
'favourite_books' : tf.train.Feature( bytes_list = favourite_books_bytelist),
'hours' : tf.train.Feature(float_list = hours_floatlist),
'age' : tf.train.Feature(int64_list = age_intlist)
}
)
)
print(example)

- 2.序列化 减小size
serialized_example = example.SerializeToString()
print(serialized_example)
![]()
- 3.TFRecordWriter存入example
filename_fullpath = './tfrecord_basic/test.tfrecords'
with tf.io.TFRecordWriter(filename_fullpath) as w:
for i in range(3):
w.write(serialized_example)
-4.TFRecordDataset读取tfrecord文件
dataset = tf.data.TFRecordDataset([filename_fullpath])
for serialized_example_tensor in dataset:
print(serialized_example)

-5. tf.io.parse_single_example 解析序列化的example
expected_features = {
'favourite_books': tf.io.VarLenFeature(dtype = tf.string), # VarLenFeature 变长
'hours': tf.io.FixedLenFeature([3], dtype = tf.float32),
'age': tf.io.FixedLenFeature([], dtype = tf.int64), # 固定长度
}
dataset = tf.data.TFRecordDataset([filename_fullpath])
for serialized_example_tensor in dataset:
example = tf.io.parse_single_example(serialized_example_tensor, expected_features)
print(example) # favourite_books和hours是sparseTenser,存储稀疏矩阵效率比较高,需要再做解析
books = tf.sparse.to_dense(example['favourite_books'], default_value=b"") # 因为是VarLenFeature
for book in books: print(book.numpy().decode('utf-8'))

-6. 存储和读取压缩的tfrecord文件(只要加compression_type,其余一样)
# 存储为压缩文件
filename_fullpath_zip = filename_fullpath + '.zip'
options = tf.io.TFRecordOptions(compression_type = "GZIP")
with tf.io.TFRecordWriter(filename_fullpath_zip, options) as writer:
for i in range(3): writer.write(serialized_example)
# 读取压缩文件
dataset_zip = tf.data.TFRecordDataset([filename_fullpath_zip], compression_type='GZIP')
for serialized_example_tensor in dataset_zip:
example = tf.io.parse_single_example(serialized_example_tensor, expected_features)
books = tf.sparse.to_dense(example['favourite_books'], default_value=b"")
for book in books: print(book.numpy().decode('utf-8')) # hours同理
4.7生成 tfrecords文件(根据4.6内容的实战)
def serialize_example(x, y):
# convert x,y to tf.train.Example and serialize 转换特征值x和标签y为example
input_features = tf.train.FloatList(value = x)
label = tf.train.FloatList(value = [y])
example = tf.train.Example(
features = tf.train.Features(
feature = {
'input_features' : tf.train.Feature(float_list = input_features),
'label' : tf.train.Feature(float_list = label)
}
)
)
return example.SerializeToString()
def csv_dataset_to_tfrecords(base_filename, dataset, n_shards, steps_per_shard, compression_type=None):
# 将dataset存入到tfrecords文件中
options = tf.io.TFRecordOptions(compression_type=compression_type)
all_filenames = []
count = 0
for shard_id in range(n_shards):
filename_fullpath = '{}_{:05d}-of-{:05d}'.format(base_filename, shard_id, n_shards)
with tf.io.TFRecordWriter(filename_fullpath, options) as w:
for x_batch, y_batch in dataset.take( steps_per_shard):
for x_example, y_example in zip(x_batch, y_batch):
w.write(serialize_example(x_example, y_example))
count+=1
all_filenames.append(filename_fullpath)
print(count)
return all_filenames
batch_size = 32
train_set = tf.data.Dataset.from_tensor_slices((x_train_scaled,y_train)).batch(batch_size)
valid_set = tf.data.Dataset.from_tensor_slices((x_valid_scaled,y_valid)).batch(batch_size)
test_set = tf.data.Dataset.from_tensor_slices((x_test_scaled,y_test)).batch(batch_size)
n_shards = 20 # 需要生成多少个文件
train_steps_per_shard = len(x_train) // batch_size // n_shards # 每个文件读取的dataset的batch数量
valid_steps_per_shard = len(x_valid) // batch_size // n_shards
test_steps_per_shard = len(x_test) // batch_size // n_shards
output_dir = 'generate_tfrecords'
if not os.path.exists(output_dir):
os.mkdir(output_dir)
train_basename = os.path.join(output_dir, 'train')
valid_basename = os.path.join(output_dir, 'valid')
test_basename = os.path.join(output_dir, 'test')
train_tfrecord_filenames = csv_dataset_to_tfrecords( train_basename, train_set, n_shards, train_steps_per_shard, None)
valid_tfrecord_filenames = csv_dataset_to_tfrecords( valid_basename, valid_set, n_shards, valid_steps_per_shard, None)
test_tfrecord_filenames = csv_dataset_to_tfrecords( test_basename, test_set, n_shards, test_steps_per_shard, None)
4-7 tf_data读取tfrecord和tf.keras结合
def parse_example(serialized_example):
expected_features = {
'input_features': tf.io.FixedLenFeature([8], dtype=tf.float32),
'label': tf.io.FixedLenFeature([1], dtype=tf.float32)
}
serialized_example = tf.io.parse_single_example(serialized_example, expected_features)
return serialized_example['input_features'], serialized_example['label']
def tfrecords_reader_dataset(filenames, n_readers=5, batch_size=32, n_parse_threads=5, shuffle_buffer_size=10000):
# 批量读取tf_records文件合并后调用parse_example解析
dataset = tf.data.Dataset.list_files(filenames)
dataset = dataset.repeat()
dataset = dataset.interleave(
lambda filename : tf.data.TFRecordDataset(filename, compression_type='GZIP'),
cycle_length=n_readers
)
dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(parse_example)
return dataset.batch(batch_size)
input_dir = './generate_tfrecords_gzip/'
train_filenames = [input_dir + x for x in os.listdir(input_dir) if x.startswith('train')]
valid_filenames = [input_dir + x for x in os.listdir(input_dir) if x.startswith('valid')]
test_filenames = [input_dir + x for x in os.listdir(input_dir) if x.startswith('test')]
# 生成dataset
batch_size = 32
tfrecords_train_set = tfrecords_reader_dataset(train_filenames, batch_size=batch_size)
tfrecords_valid_set = tfrecords_reader_dataset(valid_filenames, batch_size=batch_size)
tfrecords_test_set = tfrecords_reader_dataset(test_filenames, batch_size=batch_size)
model = keras.models.Sequential([
keras.layers.Dense(30, activation='relu', input_shape=[8]),
keras.layers.Dense(1)
])
model.compile(loss='mse', optimizer = 'sgd')
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]
model.fit(tfrecords_train_set,
validation_data = tfrecords_valid_set,
steps_per_epoch = len(x_train) // batch_size,
validation_steps = len(x_valid) // batch_size,
epochs = 100,
callbacks = callbacks
)