Python数据分析与挖掘实战学习笔记(一)
数据预处理
1. 数据清洗
(1)缺失值处理
三种方法:删除记录、数据插补、不处理
常见插补方法:均值/中位数/众数插补、使用固定值/期望值、回归方法(根据已有数据和其他与其有关变量等建立拟合模型来预测)、插值法(利用已知点建立合适的插值函数,如拉格朗日函数)
我们以餐厅销量数据为例,使用拉格朗日插值法进行缺失值处理 ,使用缺失值前后各5个未缺失数据参与建模,得出结果如下。

应用拉格朗日插值法代码如下:
#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = '../data/catering_sale.xls' #销量数据路径
outputfile = '../data/sales.xls' #输出数据路径
data = pd.read_excel(inputfile) #读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #输出结果,写入文件(2)异常值处理
在处理时,有些异常值可能蕴含有用信息,需视情况而定。四种方法:删除含有异常值的记录、视为缺失值、平均值修正、不处理。
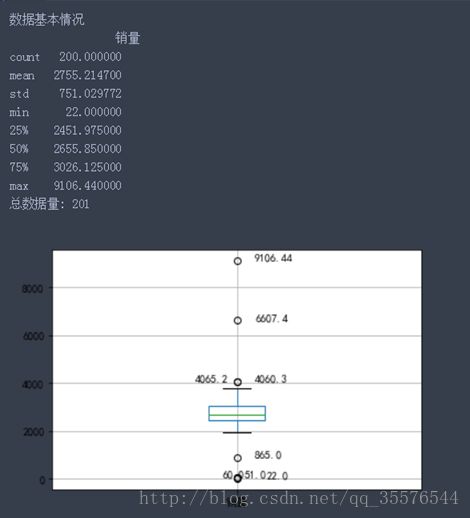
在数据量较多的时候我们不可能人工分辨,这里受用describe函数查看数据基本情况,并借助箱线图进行监测。代码如下:
import pandas as pd
catering_sale = '../data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
sums = data.describe()#查看数据的基本情况
print("数据基本情况\n",sums)
print("总数据量:",len(data))
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
#用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图最终可以得出数据基本结果:
2. 数据集成
(1) 实体识别:同名异义、异名同义、单位不同意
(2) 冗余属性识别,可利用相关性分析对属性进行检测
相关性分析实例如下:我们以餐品销量数据为例,以判定系数作为衡量标准,检验任何两种餐品销量之间的相关系数。
代码如下:
#餐饮销量数据相关性分析
from __future__ import print_function
import pandas as pd
catering_sale = 'F:/fenxiyuwajue/dataandcode/chapter3/chapter3/demo/data/catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data.corr() #相关系数矩阵,即给出了任意两款菜式之间的相关系数
data.corr()[u'百合酱蒸凤爪'] #只显示“百合酱蒸凤爪”与其他菜式的相关系数
data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺'])#计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数结果如下
 :
:
3. 数据变换
(1) 简单函数变换:平方、开放、取对数、差分运算
(2) 规范化:最小-最大规范化、零-均值规范化、小数定标规范化
代码示例:
#数据规范化
import pandas as pd
import numpy as np
datafile = '../data/normalization_data.xls' #参数初始化
data = pd.read_excel(datafile, header = None) #读取数据(data - data.min())/(data.max() - data.min()) #最小-最大规范化
(data - data.mean())/data.std() #零-均值规范化
data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
(3) 连续属性离散化
在数据的取值范围内设定若干个离散的划分点,将取值范围划分为若干个离散点,将取值范围划分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。即确定分类数及将连续属性值映射到这些分类值。
等宽法:类似于制作频率分布表
等频法:将相同数量的记录放进每个区间
基于聚类分析方法:首先将连续属性的值用聚类算法进行聚类,然后将得到的蔟进行处理,合并到一个蔟的连续属性值并做同一标记。需用户指定蔟个数,决定产生的区间数。
此处我们选择“医学中中医证型的相关数”进行连续属性离散化的对比。
代码示例:
#数据规范化
import pandas as pd
import matplotlib.pyplot as plt
datafile = 'F:/fenxiyuwajue/dataandcode/chapter4/chapter4/demo/data/discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) #读取数据
data = data[u'肝气郁结证型系数'].copy()
k = 4
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
#等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1] #使用describe函数自动计算分位数
w[0] = w[0]*(1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
from sklearn.cluster import KMeans #引入KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4) #建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.reshape((len(data), 1))) #训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort_index() #输出聚类中心,并且排序(默认是随机序的)
#这里注意,c是生成的series类型数据,自带索引,sort是排序列表,这里要用sort_index
w = pd.rolling_mean(c, 2).iloc[1:] #相邻两项求中点,作为边界点
w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k): #自定义作图函数来显示聚类结果
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()结果如下:



今日的数据预处理部分结束,明天补充数据规约。