mysql 整体优化
mysql优化,近期突击了一下mysql数据库优化,做自己的一个浅谈和收集。有不足之处希望大家指正。
mysql数据库该怎么优化?
我们会经常回答添加索引,查询慢sql。添加缓存。这样的回答,这样的回答并不是错误的,太笼统不够具体,没有细节
下面我做了一个mysql的一个优化流程,要想去做数据库的优化。需要宏观的去观察我们的程序数据库的峰值瓶颈到底在那里。
大概优化流程图:http://on-img.com/chart_image/5a66ab56e4b0332f15428b7e.png
利用脚本去监控mysql的数据库状态,分析周期性卡顿、瓶颈。还是不规则性卡顿瓶颈
mysql 监控脚本 https://blog.csdn.net/qq_35809876/article/details/79782130
周期性:
1、监控时间点,排查缓存失效时间,定时任务。
非周期性:
1、开启慢sql查询(服务器端,也可以利用阿里druid),找出慢sql,并对语句进行explain 分析,索引是否命中。编写是否合理
2、查看表关联是否设计合理。
3、合理使用缓存减轻数据库压力,把不常变动且不重要的 sql 加入缓存中。注意:缓存穿透问题
以上优化的优化思路
=========================================================================================
下面是主要的数据库的规则。
索引生效原则
B-tree索引 可以理解为排好序的索引(详情算法实现,请查询其他贴子,这方面资料很多)
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。我们可以简单理解为:快速查找排好序的一种数据结构。Mysql索引主要有两种结构:B+Tree索引和Hash索引。我们平常所说的索引,如果没有特别指明,一般都是指B树结构组织的索引(B+Tree索引)。索引如图所示 :
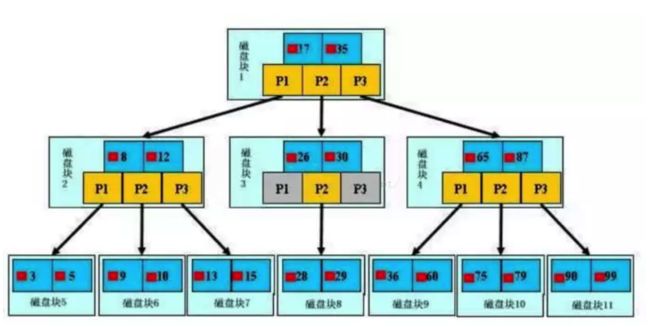
最外层浅蓝色磁盘块1里有数据17、35(深蓝色)和指针P1、P2、P3(黄色)。P1指针表示小于17的磁盘块,P2是在17-35之间,P3指向大于35的磁盘块。真实数据存在于子叶节点也就是最底下的一层3、5、9、10、13......非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35。
查找过程:例如搜索28数据项,首先加载磁盘块1到内存中,发生一次I/O,用二分查找确定在P2指针。接着发现28在26和30之间,通过P2指针的地址加载磁盘块3到内存,发生第二次I/O。用同样的方式找到磁盘块8,发生第三次I/O。
真实的情况是,上面3层的B+Tree可以表示上百万的数据,上百万的数据只发生了三次I/O而不是上百万次I/O,时间提升是巨大的。
误区:
已index(a、b、c)为例
| where语句 | 索引是否生效 |
| where a = 3 | Y |
| where a=3 and b=2 | Y |
| where a=3 and b=2 and c=3 | Y |
| where a=3 and b>2 and c=3 | N(a\b 能利用索引C不能利用) |
| where b=2 and c=3 | N |
| where a=1 and b like '%xxxx%' and c=3 | N(a\b能利用索引,c不能) |
| where a =1 and c=23 | N(a能利用索引) |
总结:联合索引 1、必须按照索引顺序使用 2、范围查询,后面索引无法在生效
hash索引 可以直接在表中快速找到单个结果
特性:
1、hash索引计算出的结果是随机的,会在磁盘上随机放置数据
2、无法进行范围查询
3、无法利用前缀索引
4、无法优化排序
5、必须回行(回到表中拿出对应行的数据),意思就是说通过索引拿到数据位置,必须回到表中去取数据
重复索引:
一个字段多个索引,数据库允许这样操作,但是这样的索引无效。只会影响表的更新速度
冗余索引:
是被允许的,这种情况很常见
例:1、index(x.y) index(y.x)
2、index(x) index(x,y)
索引碎片
索引碎片的概念,经常改动数据内容,索引文件和数据文件会产生空洞。从而形成碎片,这样会让表的索引效率 和查询效率降低
解决方案:optimize table 表名 注意:修复表数据和索引碎片重新整理,如果表内容很大,这是一个非常耗资源的过程,请在夜间业务访问量最低的时候进行或者停服务时进行。如果修改操作比较频繁,安周期进行整理操作
索引总结:尽量让查询sql命中索引,也尽量让我们查询字段被索引覆盖 避免或减少数据库回行操作
in 子查询陷阱
create table student id、age ;index(age)
create table person id、name ;index( id)
p.id = s.id
select p.name form persion where id in (select id from student where age >13);
我们正常理解先查询出学生表年龄大于13的ID 在和person表中的 id 比较查询出名字
其实不然,可以用explain sql \G 去分析一下 sql 发现persion 表进行了一次全表扫描查询,student表命中索引
这个sql 执行过程应该是 person进行全表扫描去挨个匹配in 中的内容。
针对上述sql 优化用left join 表关联查询
select p.name form student s left join person p on s.id = p.id where s.age>13;
explain 分析 sql 语句
exists 和 group by 比较
exists 要比表关联 在group by 速度快一些,表关联 在group by 需要创建一个临时表在去分组。
而exists 并不需要创建临时表
count 优化查询小技巧
select count(*) form table ;非常快因为表的总数已经被数据库缓存起来
select count(*) from student where age>9;相对会慢一些
select count(*) from student where age <= 9; 先查询出较少的数量
select (select count(*) form table ) - (select count(*) from student where age <= 9) as count;
group by 尽量使用在统计 最大数 平均数上。不要使用group by 做数据筛选。
排序
尽量按照某个索引规则执行,排序分为俩种情况
1、查出来的数据本身就是顺序性的。直接在索引上查询出来的结果就是一个有序的
2、先查出来数据,在根据排序规则重新排序。
知道这俩种情况,我们就知道该如何去做排序优化,争取让每次排序都是在索引上查询出来的结果少一次在排序过程
大数据量分页优化
select * from pro_order limit 100 ,10;
(等后续添加)
表设计字段类型数据库查找最快排序 整型、dataTime、varchar