Apache Griffin 安装与简介
目录
一、Griffin简介
二、安装部署
2.1 依赖准备
1、初始化
2、Hadoop和Hive
3、Scala 安装
4、 ES的安装与启动
2.2 源码打包部署
一、Griffin简介
数据质量模块是大数据平台中必不可少的一个功能组件,Apache Griffin(以下简称Griffin)是一个开源的大数据数据质量解决方案,
它支持批处理和流模式两种数据质量检测方式,可以从不同维度(比如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)
度量数据资产,从而提升数据的准确度、可信度。
在Griffin的架构中,主要分为Define、Measure和Analyze三个部分,如下图所示:

各部分的职责如下:
- :主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
- :主要负责执行统计任务,生成统计结果
- :主要负责保存与展示统计结果
基于以上功能,大数据平台计划引入Griffin作为数据质量解决方案,实现数据一致性检查、空值统计等功能。以下是安装步骤总结:中文版Quick Start
二、安装部署
2.1 依赖准备
- JDK (1.8 or later versions)
- MySQL(version 5.6及以上)
- Hadoop (2.6.0 or later)
- Hive (version 2.x)
- Spark (version 2.2.1)
- Livy(livy-0.5.0-incubating)
- ElasticSearch (5.0 or later versions)
- Scala(2.x or later versions)
依赖于 Ambari 安装 Griffin ,所以目前来说只需要安装ES,Scala,初始化Griffin元数据库即可。
1、初始化
初始化操作具体请参考Apache Griffin Deployment Guide,Hadoop集群、Hive安装步骤省略。
在MySQL中创建数据库quartz,然后执行Init_quartz_mysql_innodb.sql脚本初始化表信息。
| create database quartz character set utf8; CREATE USER 'quartz'@'%' IDENTIFIED BY 'L1234567'; GRANT ALL PRIVILEGES ON . TO 'quartz'@'%'; FLUSH PRIVILEGES; use quartz; |
|---|
2、Hadoop和Hive
在Hadoop服务器上创建/home/spark_conf目录,并将Hive的配置文件hive-site.xml上传到该目录下:

3、Scala 安装
下载安装包:https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
| ## 解压到 /usr/scala/ 目录下 export SCALA_HOME=/usr/scala/scala-2.11.8 export CLASSPATH=$SCALA_HOME/lib/ export PATH=$PATH:$SCALA_HOME/bin ## 设置环境变量 export SPARK_HOME=/usr/hdp/3.1.4.0-315/spark2 export LIVY_HOME=/usr/hdp/3.1.4.0-315/livy2/bin export HADOOP_CONF_DIR=/usr/hdp/3.1.4.0-315/hadoop/conf |
|---|
4、 ES的安装与启动
tar包下载链接:ElasticSearch5.5.2.tar
1.两台创建一个es专门的用户(必须)
| useradd es passwd es 密码 es |
|---|
2.两台机器使用root用户执行visudo命令然后为es用户添加权限
| root ALL=(ALL) ALL es ALL=(ALL) ALL |
|---|
3.解压 es到 /usr/ 目录下
| scp -r /usr/elasticsearch-5.5.2/ hdp02:/usr/ chown -R es /usr/elasticsearch-5.5.2/ 断开连接linux的工具,然后重新使用es用户连接上两台linux服务器 |
|---|
4、修改配置文件
| cd /usr/elasticsearch-5.5.2 mkdir data mkdir log rm -rf elasticsearch.yml vim elasticsearch.yml
vim elasticsearch.yml cluster.name: hdp_es node.name: hdp01 path.data: /usr/elasticsearch-5.5.2/data path.logs: /usr/elasticsearch-5.5.2/log network.host: 10.168.138.188 http.port: 9200 discovery.zen.ping.unicast.hosts: ["hdp01", "hdp02"] bootstrap.system_call_filter: false bootstrap.memory_lock: false http.cors.enabled: true http.cors.allow-origin: "*"
hdp02 cluster.name: hdp_es node.name: hdp02 path.data: /usr/elasticsearch-5.5.2/data path.logs: /usr/elasticsearch-5.5.2/log network.host: 10.174.96.212 http.port: 9200 discovery.zen.ping.unicast.hosts: ["hdp01", "hdp02"] bootstrap.system_call_filter: false bootstrap.memory_lock: false http.cors.enabled: true http.cors.allow-origin: "*" |
|---|
后台启动, 也可以先 在前台 启动看看报错信息。
| nohup /usr/elasticsearch-5.5.2/bin/elasticsearch 2>&1 & |
|---|
- 报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]

两台机器执行以下命令,注意每次启动ES之前都要执行
| sudo sysctl -w vm.max_map_count=262144 [es@hdp01 bin]$ sudo sysctl -w vm.max_map_count=262144 vm.max_map_count = 262144 [es@hdp01 bin]$ nohup /usr/elasticsearch-5.5.2/bin/elasticsearch 2>&1 & |
|---|
访问两台机器的 9200 出现以下面的信息则安装成功。
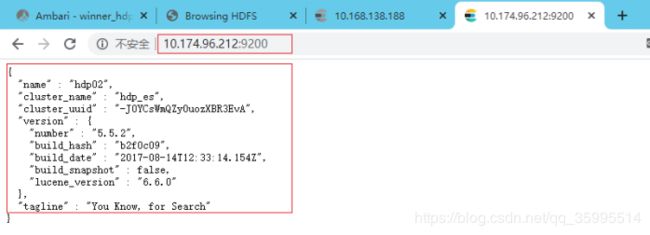
5.在ES里创建griffin索引
| curl -H "Content-Type: application/json" -XPUT http://10.168.138.188:9200/griffin? -d ' { "aliases": {}, "mappings": { "accuracy": { "properties": { "name": { "fields": { "keyword": { "ignore_above": 256, "type": "keyword" } }, "type": "text" }, "tmst": { "type": "date" } } } }, "settings": { "index": { "number_of_replicas": "2", "number_of_shards": "5" } } }' |
|---|
出现下面红色框框的信息则安装成功。

2.2 源码打包部署
在这里我使用源码编译打包的方式来部署Griffin,Griffin的源码地址是:https://github.com/apache/griffin.git,这里我使用的源码tag是griffin-0.6.0,
下载完成在idea中导入并展开源码的结构图如下:
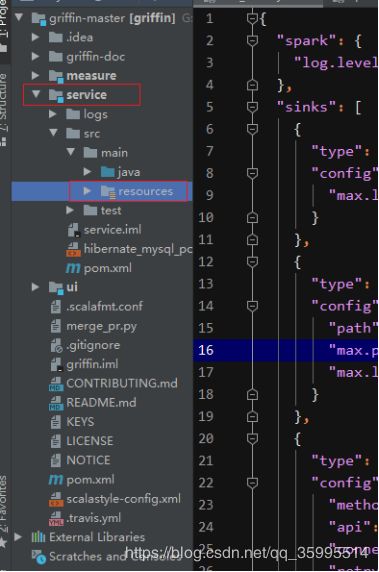
Griffin的源码结构很清晰,主要包括griffin-doc、measure、service和ui四个模块,其中griffin-doc负责存放Griffin的文档,measure负责与spark交互,执行统计任务,service使用spring boot作为服务实现,负责给ui模块提供交互所需的restful api,保存统计任务,展示统计结果。
1、service/src/main/resources/application.properties
- 说明 applicatoin.properties 将 SpringBoot 默认的 8080 设置为 8090,因为 我们的Ambari 使用的也是 8080 端口
|
|---|
因为 我们将 数据库的驱动,修改 service/pom.xml 将此处的注释放开(140行左右)
|
|
|---|
2、service/src/main/resources/quartz.properties
|
|---|
3、service/src/main/resources/sparkProperties.json
|
|---|
4、service/src/main/resources/env/env_batch.json
|
|---|
配置文件修改好后,在idea里的terminal里执行如下maven命令进行编译打包:
|
|---|
- 问题:此处有常见的 Jar 包下载不下来的 依赖包错误
- Griffin编译失败,kafka-schema-registry-client-3.2.0.jar下载地址
下载地址:https://github.com/Xiwu1994/griffin-kafka-schema-registry-client
| mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=3.2.0 -Dpackaging=jar -Dfile=kafka-schema-registry-client-3.2.0.jar |
|---|
SparkSQL2.2.1 依赖下载问题,下载tar包手动导入
| https://archive.apache.org/dist/spark/ mvn install:install-file -DartifactId=spark-sql_2.11 -Dversion=2.2.1 -Dpackaging=jar -DfileG:\software\Ambari安装包\spark2.21\spark-2.2.1-bin-hadoop2.7\jars\spark-sql_2.11-2.2.1.jar |
|---|
- 说明:下载不到的Jar 包可以按照这种方式处理。
5、修改 Jar包名称 将measure-0.6.0.jar这个jar上传到HDFS的/griffin文件目录里
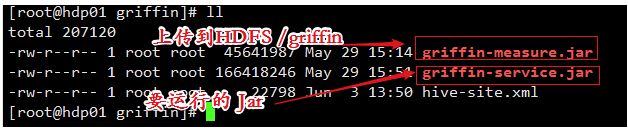
| # Hadoop需要的路径 hadoop fs -mkdir -p /griffin/persist hadoop fs -mkdir /griffin/checkpoint |
|---|
6、运行griffin-service.jar,启动Griffin管理后台
| sysctl -w vm.max_map_count=262144 nohup java -jar griffin-service.jar>service.out 2>&1 & |
|---|
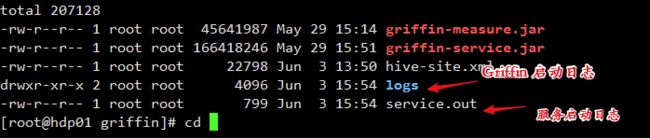
查看日志报错信息
访问Apache Griffin的默认UI(默认情况下,spring boot的端口是8080),我们之前改为了 8090 ,能访问则表示安装成功。
参考文档:
Apache Griffin 入门指南:http://griffin.apache.org/docs/quickstart-cn.html
Apache Griffin入门指南:https://www.jianshu.com/p/9e4067b3e2dd
Apache Griffin 5.0 编译安装和使用:https://blog.csdn.net/github_39577257/article/details/90607081