kettle根据时间戳增量的将数据从MySQL同步SQLServer(linux部署脚本启动作业、config.properties 配置数据库)
目录
一、设计思路与方案
1、思路
2、方案
3、总体流程
二、实现步骤
2.1、创建作业和DB连接
2.2、创建时间戳表
2.3、获取时间戳并设为变量
2.4、插入更新
2.5、更新时间戳
2.6、配置数据源加载外部文件
一、设计思路与方案
1、思路
我的需求:从MySQL 按时间增量同步到 SQLServer,MySQL中的数据会源源不断的写入,不会删除数据, SQLServer根据 MySQL表中的 modifytime 做增量同步就好,三台阿里云机器做数据的接入、计算、同步。
下面是网友的设计思路:
假定在源数据表中有一个字段会记录数据的新增或修改时间(modifytime),可以通过它对数据在时间维度上进行排序。通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后的增量数据。这是时间戳增量同步。
但是时间戳增量同步不能对源数据库中历史数据的删除操作进行同步,我们可以通过在每次同步时,把时间戳往前回滚一段时间,从而同步一定时间段内的删除操作。这就是时间戳增量回滚同步,这个名字是我自己给取得,意会即可,就是在时间戳增量同步的同时回滚一定的时间段(参考的https://blog.csdn.net/dora_310/article/details/80511793 )。
说明:
- 源数据表 需要被同步的数据表
- 目标数据表 同步至的数据表
- 中间表 存储时间戳的表
2、方案
1、刚开始接触到这个需求,我就抱着学习的态度,因为kettle没怎么用过,觉得应该不难,解决方案的话就是如下的操作,别人的:
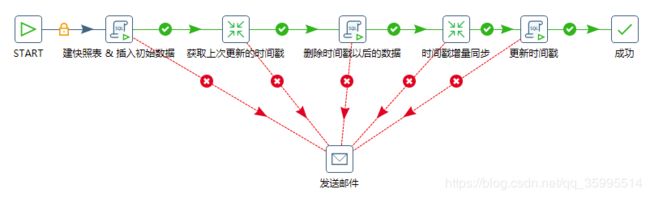
2、后面的话我参考了同事的一种设计方式
下面这种方式是 源数据库 与目标数据库 保持一致,有源数据库表记录删除,这个是整张表数据的同步,两张表的数据是一致的。

3、从需求的实际出发,我选择博客上网友的设计,但是我没有删除时间戳及其以后的数据,意会我的设计即可
说明:Kettle根据时间戳增量同步两张表的数据从MySQL到SQLServer,时间戳表 etl_last_jobtime 字段last_timestamp记录每次作业开始时的当前时间(数据同步) ,作业完成后根据ID 更新相应表的 last_timestamp 字段,增量获取数据时 modifytime字段 大于等于上次记录的 last_timestamp 字段, 作业开始记录当前时间防止 作业执行的时间长而丢失数据。

3、总体流程
- 开始组建
- 设置config_path
- 建时间戳表
- 获取中间表的时间戳,并设置为全局变量
- 数据的插入或更新
- 更新时间戳
其实,这里的设计和上面网友的设计基本思路是一样的, 区别有两点:
- 我的临时表 时间戳没有把表中的 modifyTime字段 排序 取最新值,因为排序取值性能这块不好,我们的需求也不需要这样做,因为源数据表中的数据是不断写入的,记录当前时间就可以(now()),然后 表中数据的 modifytime 又会不断的更新,下次取数据的时候,我只需要 (modifytime >= last_timestamp) ,我的设计如此,数据重复与丢失考虑的不是很多。
- 考虑到作业的执行也需要时间,这个 当前时间(now()),在作业一开始就给了,作业执行完后,更新这个 last_timestamp ,设计可能存在问题,时间戳回滚也考虑过,但是没想好回滚多长时间合适,数据丢失或重复的可能也存在,数据不能丢失就好,项目搭建测试中
二、实现步骤
2.1、创建作业和DB连接
打开Spoon工具(java环境),新建作业,然后在左侧主对象树DB连接中新建DB连接。创建连接并测试通过后可以在左侧DB连接下右键共享出来。因为在单个作业或者转换中新建的DB连接都是局域数据源,在其他转换和作业中是不能使用的,即使属于同一个作业下的不同转换,所以需要把他们共享,这样DB连接就会成为全局数据源,不用多次编辑,提醒添加相应数据库的驱动。


2.2、创建时间戳表
这张表的话,一开始就是建好的,这个表一定存在的,没有使用 SQL 脚本在作业中创建 ,考虑到 SQLServer 不熟,我将中间表建在 源数据库中 etl_last_jobtime,不同的表根据 ID 取时间戳,为了表信息易维护增加了 table_info字段。
CREATE TABLE IF NOT EXISTS
etl_last_jobtime(
id int(11) NOT NULL PRIMARY KEY,
table_info varchar(32) NOT NULL,
last_timestamp TIMESTAMP NOT NULL comment '最近一次同步数据时间'
);
-- 插入初始的时间
INSERT IGNORE etl_last_jobtime(id ,table_info,last_timestamp) VALUES(1,'表1信息', '1998-07-02 15:30:00');
INSERT IGNORE etl_last_jobtime(id ,table_info,last_timestamp) VALUES(2,'表2信息', '1998-07-02 15:30:00');
2.3、获取时间戳并设为变量
这一步使用到了 表输入和 设置标量, nowTime 就是作业刚开始运行的时间,估计存在偏差还在测试中,想法是这样的,因为作业的执行需要时间,每次数据同步的时间可能不等,所以作业开始执行或者没有开始执行时就获取 这个时间戳,然后作业开始执行,这就好比是回滚时间,只不过是根据每次同步作业的执行时间决定的,这块考虑到这块数据一定不能丢失,所以使用了 大于等于 取数据。

2.4、插入更新
这一步是真正的同步增量同步,完成数据的更新和插入


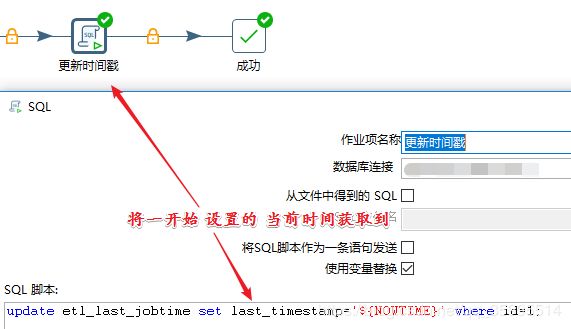
2.5、更新时间戳
将 etl_last_jobtime 中 last_timestamp 字段的更新放在最后一步。
update etl_last_jobtime set last_timestamp='${NOWTIME}' where id=1;id =1 的时候更新 last_timestamp 等于 前面作业开始是 获取的 nowTime
2.6、配置数据源加载外部文件
具体可以参考Kettle配置数据源时加载外部properties配置文件:https://www.jianshu.com/p/ac7c0566d782
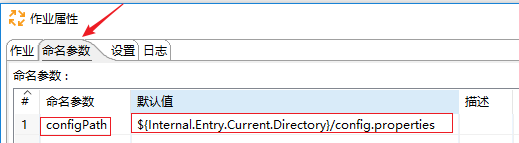
1、配置config.properties 文件,设置变量


2、作业空表处双击,设置作业参数,设置变量就是为了将 配置的命名参数获取到,从而获取到 配置文件 config.properties
config.properties文件配置

3、使用配置文件连接数据库

4、linux 中运行 作业的脚本
这里我们使用真实环境的测试运行,使用脚本执行作业,后面也可以定时调度。
#!/bin/bash
###############################
#
#
#
#
###############################
set -x
date=`date +%Y-%m-%d`
jobPath=`cd $(dirname $0);pwd`
cd /hadoop/software/kettle/data-integration/
./kitchen.sh -file=${jobPath}/data_sync.kjb -param:"config_path=${jobPath}/config.properties"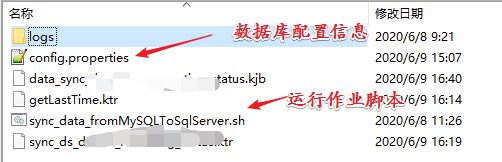
说明:作业没有运行,configPath 的配置信息是没有加载进内存的,在左侧 DB 连接 测试数据库连接是会报错的,可以先运行作业,作业执行完 start->设置configPath 后会将配置信息加载进内存中,这样配置文件的信息就可以获取到了。
C:\Users\yangxu\.kettle\shared.xml.backup 这块可以看到配置的数据库信息。

将以上的作业、数据库配置文件、作业运行的脚本在本地测试没问题后打包(zip unzip)上传到 linux 测试机,运行脚本即可。

以上就是数据同步的个人记录,后期测试结果,会继续分享。
最后说一下:尽量将转换抽离,不要放在一个转换中,尤其是有多个 SQL脚本需要执行的转换 执行的顺序 可能不是串行,可以参考:https://mp.csdn.net/console/editor/html/106633806,这样做也方便测试。
kettle转换里面sql脚本的执行顺序:https://blog.csdn.net/u012848709/article/details/65626634
参考博客:使用Kettle实现数据实时增量同步https://blog.csdn.net/dora_310/article/details/80511793
kettle转换里面sql脚本的执行顺序:https://blog.csdn.net/u012848709/article/details/65626634
kettle的转换里面sql脚本执行顺序以执行次数:https://blog.csdn.net/u012848709/article/details/67679366