论文阅读笔记《End-to-End Learning of Geometry and Context for Deep Stereo Regression》
本文使用了3D卷积的概念去获得更多的上下文信息,并采用回归的方法去预测视差值,不再使用传统的成本聚合,视差计算,视差优化的方法,利用一个端到端的网络直接生成最终的视差图。这一思路无疑比传统的图块匹配的方法更加先进,而且不用再给图块设置标签,直接将预测结果与真实视差图进行比对,再将误差反向传播即可,后来的许多网络都采用了这一思路。该算法当时也在KITTI 排行榜中排名第一,2018年5月11日,KITTI2015排名为16。
摘要
本文提出一种新型的深度学习网络用于从一对矫正过的立体图像回归得到其对应的视差图。我们利用问题(对象)的几何知识,形成一个使用深度特征表示的匹配代价卷。我们通过对这一匹配代价卷应用3D卷积来结合环境(上下文)信息。利用本文提出的一种可微分的柔性argmin操作可以对匹配代价卷回归得到视差值,这使得我们可以直接端到端地训练我们的网络达到亚像素级别的精度,而不需要任何后处理和规则化的操作。
1.介绍
在这篇论文中,我们主要关注通过一对矫正过的立体图像计算每一个像素的视差值。实现这一目标,立体匹配算法的核心任务是计算两幅图像中每个像素之间的对应性。在真实世界中鲁棒地实现这一任务是极具挑战的。当前最好的立体匹配算法通常在处理弱纹理区域,反光表面,细长结构和重复纹理区域时存在很大困难。许多立体匹配算法想利用池化操作或基于规则化的梯度方法来减轻这个问题。然而这通常会要求在平滑表面和检测细节结构之间做一定的妥协(表面越平滑则细节信息损失就越多)。
深度学习模型成功地直接从原始数据(物体分类,目标检测和语义分割)中学习有效的表征信息。这些例子表明深度卷积神经网络可以有效的理解语义信息。在大量数据集的监督训练下可以极好地完成分类任务。我们观察到立体匹配算法所面临的一系列挑战都可以通过获取全局的语义信息来改善,而不是仅仅依靠局部的几何信息。举个例子,对于一个汽车挡风玻璃这样的反光表面,如果立体匹配算法只依靠这一反光表面的局部表现来计算几何特征很可能会出错。然而,如果理解了这一表面的语义信息(这是属于汽车的一部分),再去推断局部的几何特征就很有优势了。在这篇论文中,我们演示了如何学习一个可以进行端到端训练的立体回归模型,该模型能够理解更宽广的环境信息。
利用深度学习表征的立体匹配算法至今仍在关注使用它们来获得一元项(unary terms)。对深度的一元表征应用代价匹配来估算像素的视差值效果很差。传统的规则化和后处理步骤依然在使用,如半全局匹配和左右一致性检测。这些规则化步骤作用是很有限的,因为它们是人工设计的,浅层的函数,并且对于前面提及的问题十分敏感。
这篇论文解答了这一问题——我们能否利用我们对于立体几何的理解,借助深度学习的方法来将立体视觉问题规范化?这篇论文的主要贡献是提出了一个端到端的深度学习方法来从一对矫正过的图像来估算每个像素的视差值。我们的结构如图1所示。它通过构建匹配代价卷明确地表达了几何特征,同时还利用深度卷积网络表达了语义信息。我们实现这一方法主要遵循以下两个想法:
- 我们直接从数据中结合上下文信息,使用3D卷积来规则化匹配代价卷(包含高度、宽度、视差三个维度)
- 我们使用完全可微分的柔性argmin函数,允许我们从视差匹配代价卷中回归得到亚像素的视差值
第三节介绍了这个模型并从更多的细节方面介绍了模型的内容。第四节,我们在合成的SceneFlow数据集上评估了我们的模型,并在KITTI2012和KITTI2015数据集上排名第一。最后在4.3节,我们展示了我们的模型能够学习语义和上下文信息的证据。
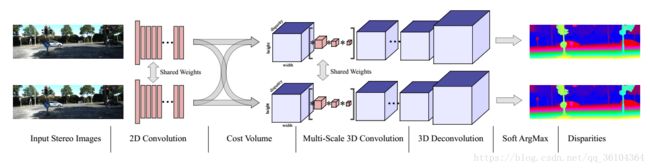
图1.端到端的深度立体匹配回归模型,GC-Net(Geometry and Context Network)
2.相关工作
介绍了传统立体匹配的步骤和几个算法,在给出训练数据集和标准视差图之后机器学习的方法被引入进来,如Zhang和Seitz提出的交替优化视差值和马尔科夫随机场正则化参数的方法,还有Scharstein和Pal研究的条件随机场(CRF)方法。
深度卷积神经网络可以用一对9*9的匹配图块来训练,随后再使用非学习的代价聚合和规则化方法,就如Zbontar和LeCun提出的算法。Luo等人提出一种更快的网络来计算局部的匹配成本,通过Siamese网络将其转换为一个视差值的多标签分类问题。Chen等人提出的多尺度模型得到了很好的局部匹配代价结果。值得注意的是Flynn等人的DeepStereo网络,它研究结合分离颜色模型的匹配代价卷,预言了一种多视角立体环境下的全新的观点。
Mayer等人创造了一个巨大的合成的数据集来训练视差估算网络。该网络的一个变种提出视差线(disparity line)上的一维的相关性非常接近于立体匹配代价卷。此外,这个代价卷还将单一图像的卷积特征级联起来,在进行一系列的卷积。与此相反,我们的方法在计算匹配代价卷的时候不会破坏特征维度,而是使用3D卷积来结合上下文信息。
在本文中,我们没有采用后处理和规则化操作。我们的网络可以通过构建一个完全可微匹配代价卷来明确的表达几何特征。我们的网络通过3D卷积结构来结合上下文信息。我们并没有研究概率分布,代价函数或者分类结果。而是直接从一对立体图像中回归得到亚像素级别的视差估计值。
3.学习端到端的视差回归
相比与手动设计立体匹配算法的每个步骤,我们更喜欢使用深度学习来构建从一对图片到视差图的端到端的结构。我们希望直接从数据中获得更好优化函数。此外,这一方法减少了工程设计的复杂性。我们并不是简单的建立一个如同黑箱的机器学习结构来进行立体匹配。而是提倡利用几十年来几何研究的深入见解来指导网络结构的设计。所以,我们的网络是通过微分层来表示传统立体匹配流程中的各个主要内容的。这使得我们可以端到端的训练整个网络,同时还能利用立体匹配问题中的几何知识。
我们的结构,GC-Net(几何和上下文网络)如图1所示,关于每一层的更多细节如表1所示。

表1.端到端深度立体匹配回归模型GC-Net的摘要信息。每个2-D或3-D卷积层代表一个由卷积层,批量规则化层和ReLU非线性层组成的组。
3.1 一元特征
首先我们学习到一个深度特征用于计算立体匹配成本。而不是使用原始的像素强度值来计算匹配成本。这种特征提取器在光照条件复杂的区域更具鲁棒性并且能够结合局部的上下文信息。
在我们的模型中,我通过二维卷积操作来学习深度特征。每个卷积层后面都跟随一个批量规则化层和一个修正的非线性层。为了减少计算要求,我们首先使用55的卷积核,以2为步长对输入进行下采样。这一层之后,我们加了8个残差组,每个残差组是由两个33的卷积层链接而成。我们最终的模型结构如表1所示。我们将左右两幅立体图像穿过这些层,得到了一元特征。我们在左右两个分路中共享参数以更加高效的学习到一致性特征。
3.2 匹配代价卷
我们使用一元特征计算匹配代价来构架匹配代价卷。虽然采用的方法是简单地将左右特征图级联起来,但构成的匹配代价卷使得我们能够按照保留立体匹配几何信息的方式建模。对于每一幅立体图像,我们都构建了一个四维的匹配代价卷(高度、宽度、最大视差+1(0~maxdisp)、特征图数目)。我们将左图的每一个一元特征和右图每一个视差下的特征图级联起来,并封装成一个四维的代价卷。(对于某一个特征,匹配代价卷就是一个三维的方块,第一层是视差为0时的特征图,第二层是视差为1时的特征图,以此类推共有最大视差+1层,长和宽分别是特征图的尺寸,假设一共提取了10个特征,则有10个这样的三维方块)
至关重要的是,我们在这步操作中保留了特征的维度,不像先前许多方法使用点乘方式来降低特征维度。这使得我们可以结合上下文信息并作用于一元特征上。我们发现通过级联特征图构成匹配代价卷效果要优于削减特征或者使用距离度量函数的方法。我们的直觉是通过保持一元特征,网络能够学习到一个绝对的表征(因为不是去度量距离这种间接的方式)并把它带入到匹配代价卷中。这赋予了该结构学习语义信息的能力。相反,使用距离度量方法限制了网络只能学习特征之间的相关性表征,而不能将绝对的特征表征带入到匹配代价卷中。
3.3 学习上下文信息
得到视差匹配代价卷,我们希望学习到一个规则化函数,其能够包含上下文信息并能优化我们的视差估计结果。各个一元元素之间的匹配代价不可能是完美的,即使是用深度特征表征的方式。例如在像素强度均一的区域(如天空),任何基于固定的局部环境的特征匹配代价曲线都会是平坦的。我们发现像这样的区域将导致在视差维度上出现多种模式的匹配代价曲线。因此我们希望去规则或并改善匹配代价卷。
我们打算使用三维卷积操作来进行滤波和改善表征。3D卷积能够从高度、宽度和视差三个维度提取特征表征。因为我们对每个一元特征都记算了代价曲线,所以我们可以从这些表征中训练卷积核。在4.1节中,我们展示了3D卷积核对于学习上下文信息和有效改善立体匹配效果的重要性。
使用3D卷积的困难在于增加的维度使得训练和测试的计算时间增加。设计用于解决稠密预测任务的深度的编码解码方法通过对下采样的特征图进行编码,并在解码器中进行上采样解决了计算时间的问题。我们把这一思路拓展到了三维中。通过以2为步长对输入进行下采样,我们也将3D匹配代价卷的尺寸缩小了8倍。我们用4个下采样层构建了3D规则化网络。每个一元特征图都缩小了一倍,整个特征图缩小了32倍。这使得我们可以利用较大的视野来获得上下文信息。我们对每个编码层都使用了两个连续的333卷积。为了以输入的分辨率得到稠密的预测图,我们在解码器中使用了3D反卷积对匹配代价卷进行上采样。
下采样能够有效的扩大每个特征的感受野并减少计算量。然而,他也减少了损失的分辨率上的空间精确性和细节信息。由于这个原因,我们在上采样之前都加上了高分辨率的特征图。这种残差层能够保持更高频率的信息,进而上采样得到的特征可以提供视野宽阔且信息完整的特征图。
最后,我们应用了一个单独的3D反卷积,步长为2,输出为单一特征图。这对于得到与输入维度相同的稠密预测图是至关重要的,因为一元特征图被下采样缩小了一倍。最终的结果是得到了一个规则化的尺寸为HWD的匹配代价卷。
3.4 可微分的Argmin
经典的立体匹配算法从每个匹配代价元中获得最终的匹配代价卷。对于这种匹配代价卷,我们可以通过在视差维度上采用Argmin操作来估算视差值。然而,这种操作存在两个问题:
- 他是离散的并且不能生成亚像素级别的视差估计
- 他不能微分因此无法通过反向传播的方法进行训练
为了解决这些限制,我们定义了一种柔性Argmin方法,它既是完全可微的,又能回归得到一个光滑的视差估计值。首先,我们通过将匹配代价值 c d c_d cd(对于每个视差d)取负数,把匹配代价卷转换为可能性卷(匹配代价越高,可能性越低),我们利用softmax操作 σ ( ⋅ ) \sigma \left ( \cdot \right) σ(⋅)对可能性卷在视差维度上进行正则化。然后对每个视差值 d d d进行加权求和,权重就是他对应的可能性。图形显示如图2,数学定义如下:
s o f t a r g m i n = ∑ d = 0 D m a x d × σ ( − c d ) soft argmin = \sum_{d=0}^{D_{max}}d\times \sigma \left (-c_d \right) softargmin=d=0∑Dmaxd×σ(−cd)
这一操作是完全可微的,并允许我们训练,回归得到视差估计值。我们注意到这一相似的函数最初是用作一种柔性注意机制。在这里,我们展示了如何将它应用到立体匹配的回归问题上。
然而,相比于argmin操作,他的输出受到所有值的影响。这使他对于多状态分布(multi-modal distribution)很敏感,因为输出没有取得最大可能性。他会估算一个各个状态的加权平均值。为了克服这一问题,我们依赖网络规则化来生成单峰的视差可能性分布图。网络也可以对匹配代价进行预分频来控制规则化的post-softmax可能性的峰值度(图2)。我们明确地在最后一个卷积层中放弃了批量规则化,使得网络能够从数据中学到这些。
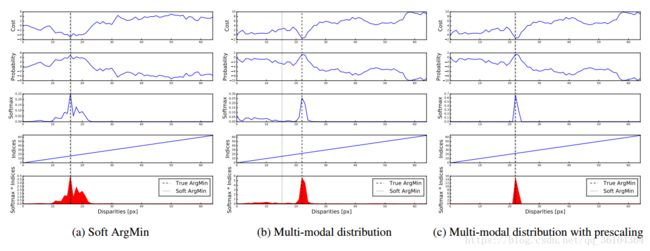
图2. 柔性argmin操作的图像描述。按照视差值画出代价曲线并输出一个argmin的估计值,通过对每个视差的softmax可能性与视差值乘积求和。(a)说明当曲线是单峰的时候,可以精确的捕捉到真实的argmin;(b)说明当数据是双峰的并且一个尖锐一个平坦时,估计值出错;©说明如果网络对代价曲线进行预分频(pre-scale),这种错误可以避免,因为softmax的可能性趋向于更加极端,以产生一个单峰的结果
3.5 损失函数
我们从随机的初始化参数开始端到端地训练整个网络。我们利用真实的深度数据进行有监督的学习。由于雷达标记的真实值可能是稀疏的。所以,我们对每个标记像素的损失值取了平均值。我们用每个像素 n n n真实视差值 d n d_n dn和模型预测视差值 d ^ n \hat d_n d^n之间的绝对值差来训练网络。这个有监督的回归损失函数定义如下:
L o s s = 1 N ∑ n = 1 N ∥ d n − d ^ n ∥ 1 Loss = \frac {1}{N}\sum_{n=1}^{N} \left\| d_n-\hat d_n \right\|_1 Loss=N1n=1∑N∥∥∥dn−d^n∥∥∥1
在后面的章节里,我们将展示把我们的模型规范化为回归问题使得我们能够以亚像素级别的精度进行回归,并且要优于分类的方式。除此之外,规范化为回归问题使得他有可能采用基于光度二次投影误差(photometric reprojection error)的无监督学习。
4. 实验
我们使用TensorFlow架构搭建我们的网络,所有模型采用RMSProp的优化方式和恒定的学习率0.001。我们训练的批尺寸为1张随机切割为256*512大小的图像。在训练之前我们对所有图像进行了归一化处理,使每个像素的强度值在-1到1之间。我们在SceneFlow数据集上训练大约15万个周期,使用一个NVIDIA Titan-X 显卡大概需要两天时间。对于KITTI 数据集,我们对先前在SceneFlow上训练得到的网络进行优化训练5万次。在SceneFlow数据集上我们采用F=32,H=540,W=960,D=192,在KITTI数据集上,采用F=32,H=388,W=1240,D=192。
4.1 模型设计分析
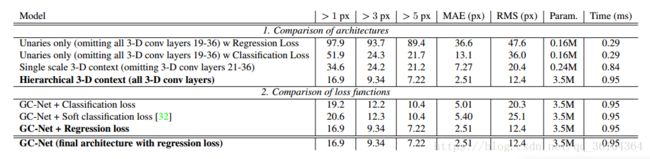
表2.SceneFlow数据集上的试验结果
在表2中,我们采用消融学习来比较几种不同模型变种来确定我们的设计选择。我们希望评估这篇文章中核心思想的重要性;使用回归损失代替分类损失和利用3D卷积来规则化匹配代价卷。
表2中的第一个实验表明3D滤波器的表现明显比只学习一元特征要好。我们比较了完整网络(如表1中所展示的)与只使用一元特征的模型(丢弃所有的3D卷积层,19-36层)和丢弃分层3D卷积的模型(丢弃21-36层)。我们观察到3D滤波器能够很好的规则化和平滑输出,同时保持输出视差图的清晰度和准确性。我们发现分层3D模型要比普通的通过聚合一个较大环境信息的3D卷积模型表现要好,并且没有明显增加计算要求。
表2中的第二个实验比较了回归损失函数与基础的硬性或柔性分类函数。硬性分类函数训练网络对匹配代价卷中的视差进行分类,根据采用“one-hot”编码的交叉熵损失函数计算的可能性结果。柔性分类函数按照以正确视差值为中心的高斯分布来平滑编码。在表2中,我们发现回归的方式优于硬性和柔性分类方法。尤其引人注目的是在像素准确性度量上和一个像素误差范围内误匹配率上,因为回归损失函数使得网络可以按照亚像素级别的精度预测视差值。
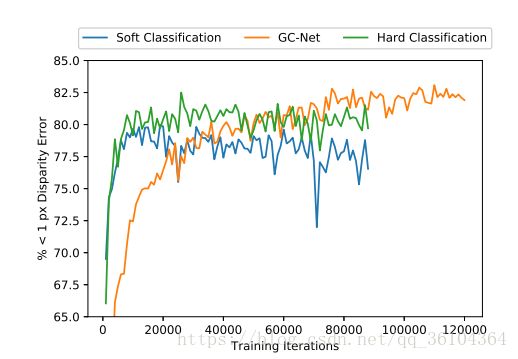
图3. 在SceneFlow数据集上训练时的真实误差
从图3中我们可以观察到分类损失函数收敛的更快,但回归损失函数表现最好。
4.2 KITTI排行榜
表3展示了我们的模型在KITTI2012和KITTI2015数据集上的表现。
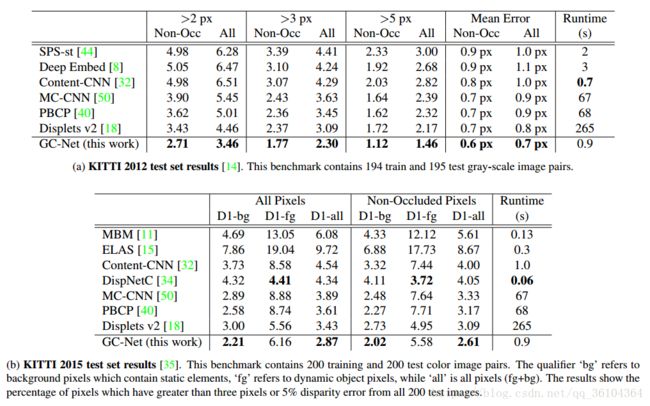
表3. 与KITTI2012和KITTI2015数据集上的其他立体匹配算法进行比较。我们的方法在两个有竞争力的排行榜中排名第一,优于其他所有方法
4.3 模型特点
这一节我们展示了我们模型能够使用更宽阔的上下文信息来推断局部几何信息的能力。在图4中,我们展示了一些有关预测像素视差模型特点的例子。图c显示了每个输入像素与输出之间的敏感性。
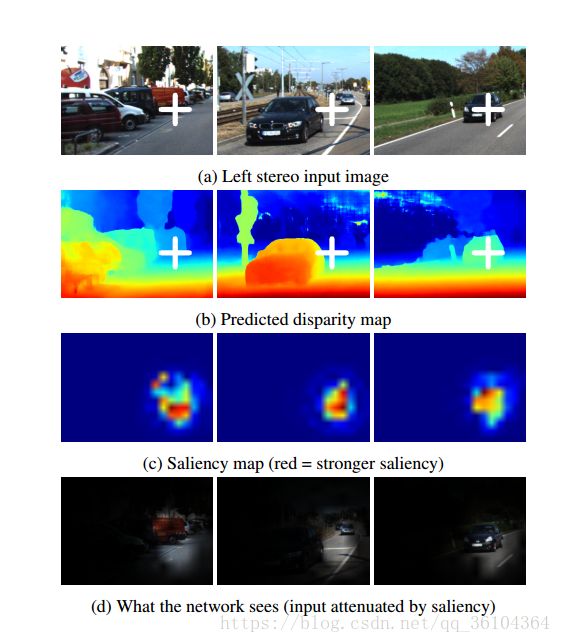
图4. 可视化凸显图,展示了模型对于所选择的输出像素点(白色十字处)的有效感受野。这表明我们的网络能够利用较大的视野和场景中重要的上下文信息来回归视差值,而不是利用局部的几何和表面信息。例如,在右边的例子中,模型考虑了车辆和周围路面的环境信息来估算视差值。
这些结果显示对于一个给定点的视差预测依赖于一个宽阔的上下文视野。例如,汽车前部的视差值取决于汽车和路面的上像素点。这说明我们的模型能够利用更宽广的上下文信息,而不是像先前其他立体匹配算法采用的中9*9的局部图块。
原文链接:https://arxiv.org/pdf/1703.04309v1.pdf
代码链接:https://github.com/LinHungShi/GCNetwork