Python 删除列表中的'\n'和空格
要爬取的span标签下的价格730
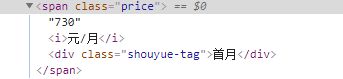
用的是xpath获取内容
![]()
但爬取的结果为
![]()
把 i 标签以及后面的div也爬取下来了,导致这部分为 \n 和空格,很显然,这不是我要的结果
想过先用xpath,再用正则表达式匹配数字,但一直提示类型不一致,因为xpath得到的是列表,而正则表达式是对字符串提取,希望有知道的大神在评论解答下
加入这一句,问题就解决了
price = [x.strip() for x in pricelist if x.strip() != '']把 \n和空格都删除了
![]()
参考了https://blog.csdn.net/thindi/article/details/83963267