go爬虫实现,基于beego实现爬取豆瓣 第一篇 入门篇
这两天用go写了一个爬虫,爬取了豆瓣网,在此特地分享一下,希望对大家学习有帮助。
本爬虫基于beego实现
没有用过beego的同学怎么办

后面会附上不基于beego实现方法。
第一次写博客,没什么经验请大家多多包涵

一、爬虫作用
我们需要一些网站的数据,不可能自己一个一个手动去收集,所以爬虫就诞生了.......emmmmmm,爬虫通过一个入口,也就是一个起始的url网址,然后通过爬取这个url网址的html代码,获取html网页的所有标签(链接),然后在进入爬过取过来的链接的页面,再循环上一步操作,然后在这个过程中我们可以把网页中其他数据收集过来,占为己用。
二、需要知识
1.golang基础(废话)
2.beego的基础使用
3.Redis 基础使用(后面会讲到很简单)
4.正则表达式
开始我们今天的学习吧

我使用的是sublime_text编辑器![]() 打开sbulime 然后新建一个名为 pachong 我beego项目
打开sbulime 然后新建一个名为 pachong 我beego项目

然后在Grabdata.go 里
type GrabdataDisat struct {
beego.Controller
}
func (this *GrabdataDisat) Getgradbta() {
//关闭模板渲染
this.EnableRender = false
}
并且配置路由
beego.Router("/getgradbta", &controllers.GrabdataDisat{}, "Get:Getgradbta")
在创建models.go![]() 之后的网页解析,数据获取存储都写在这里面,好到此基本的项目结构就是这样啦,现在开始着手写爬虫吧,先去分析一个我们要爬取的豆瓣的网站
之后的网页解析,数据获取存储都写在这里面,好到此基本的项目结构就是这样啦,现在开始着手写爬虫吧,先去分析一个我们要爬取的豆瓣的网站
戳这里 然后按F12进入查看源码模式,然后我们把鼠标放到片名上面
然后按F12进入查看源码模式,然后我们把鼠标放到片名上面
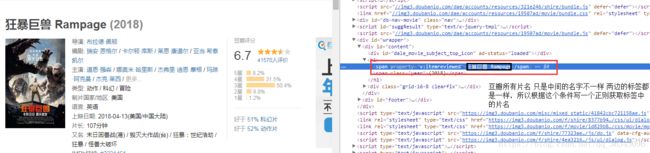
那么我们在models.go里面就可以写一个方法 用正则来匹配 这个片名
//匹配电影名
func GetPianNmae(htmls string) string {
if htmls == "" {
return ""
}
//regexp是正则的包,我们先写好正则的规则
reg := regexp.MustCompile(`(.*)`)
//然后进行匹配 -1 表示全部返回 如果写一个1 他就返回匹配到的第一个 返回是一个[][]string
result := reg.FindAllStringSubmatch(htmls, -1)
//如果没有匹配到内容返回空
if len(result) == 0 {
return ""
}
return string(result[0][1])
} 有同学可能会有疑问了?为什么返回的 result[0][1] 而不是 result[0][0]

等写完下面的代码 跑程序的时候打印一下result就知道了
现在我们正则也有了 就差把网页数据抓取过来了 所以返回到Getgradbta方法
func (this *GrabdataDisat) Getgradbta() {
//关闭模板渲染
this.EnableRender = false
//爬虫入口url
urls := "https://movie.douban.com/subject/26430636/?from=showing"
//爬取
resps := httplib.Get(urls)
//得到内容
htmls, err := resps.String()
if err != nil {
panic(err)
}
this.Ctx.WriteString(models.GetPianNmae(htmls))
}这是访问一下
http://localhost:8080/getgradbta
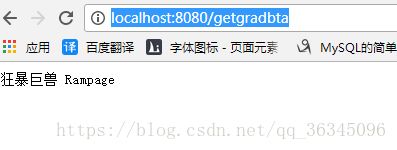
这个时候就已经实现了从
https://movie.douban.com/subject/26430636/?from=showing抓取到片名了。会正则的同学还可以自己试着抓一下其他的数据,下一章节在 带领大家 学习一下正则表达式,并抓取到其他的数据存入数据库(五一的时候把剩下的全部更新出来)
贴一下全部的代码
package controllers
import (
"pachong/models"
"github.com/astaxie/beego"
"github.com/astaxie/beego/httplib"
)
type GrabdataDisat struct {
beego.Controller
}
func (this *GrabdataDisat) Getgradbta() {
//关闭模板渲染
this.EnableRender = false
//爬虫入口url
urls := "https://movie.douban.com/subject/26430636/?from=showing"
//爬取
resps := httplib.Get(urls)
//得到内容
htmls, err := resps.String()
if err != nil {
panic(err)
}
this.Ctx.WriteString(models.GetPianNmae(htmls))
}
package models
import (
"regexp"
)
//匹配电影名
func GetPianNmae(htmls string) string {
if htmls == "" {
return ""
}
//regexp是正则的包,我们先写好正则的规则
reg := regexp.MustCompile(`(.*)`)
//然后进行匹配 -1 表示全部返回 如果写一个1 他就返回匹配到的第一个 返回是一个[][]string
result := reg.FindAllStringSubmatch(htmls, -1)
//如果没有匹配到内容返回空
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
