SHELL04 - 字符串处理 扩展的脚本技巧 正则表达式
一、字符串处理
${变量:开始位置:长度}
${变量/旧/新}
${变量##*:}
${变量%%:*}
${变量:-111}
1.字符串截取及切割
1)子串截取
子串截取的三种用法:
应用:隐藏身份证后6位;做验证码a=’0123456789‘ 随机截取四位数字;给电脑配随机密码,每次取四位,用for循环;
(1)${phone:起始位置:长度} (从0开始计位数)
#phone='15170016044' 要求提取7001
#echo${phone:0:4} = echo${phone::4} / 起始位置为0可以省略
# echo${#phone} 显示11 /加#号统计这个变量有多少位
#echo${phone:3:4} 显示 7001 /从第几位开始截几位
(2)expr substr "$phone" 起始位置 长度 (从1开始计位数)
#expr substr "$phone" 4 4 显示7001 /双引号
(3)echo $phone | cut -b 起始位置-结束位置 (从1开始计位数)
# echo $phone | cut -b 4-7 显示7001
# echo $phone | cut -b 4,5,6,7 显示7001
########################################
随机提取1位字符
#!/bin/bash
ID='0123456789qwertyuioplkjhgfdsazxcvbnmQWERTYUIOPLKJHGFDSAZXCVBNM'
(echo ${#ID} 62)
num=$[RANDOM%62] 0-61 /取的值不能超过ID最高位数,取余数里余数永远小于除数。
echo ${ID:$num:1} /
num=$[RANDOM%62+1] 1-62
echo $ID | cut -b $num
expr substr “$ID” $num 1
2) 子串替换
( vim :s/老/新/g
vim末行模式常用操作:
:s/old/new ,替换当前行第一个“old” :s/old/new/g ,替换当前行所有的“old”
:n,m s/old/new/g ,替换第n-m行所有的“old” :% s/old/new/g ,替换文件内所有的“old”
:w /root/newfile ,另存为其它文件 :r /etc/filesystems ,读入其他文件内容 :set nu|nonu ,显示/不显示行号 :set ai|noai ,启用/关闭自动缩进 )
echo ${phone/老/新}
echo ${phone/6034/****}
echo ${phone/1/*} /单斜线只替换第一个匹配值
echo ${phone//1/9} /双斜线替换所有匹配值
########################################
编写脚本:批量修改扩展名txt 改成 doc 提示:循环,掐头去尾
前奏准备:mkdir /test touch /test/{a.txt,b.txt,c.txt,d.txt}
for I in $(ls /test/*.txt)
do
echo ${i/.txt/.doc} / 从左往右,要确保只有一个.txt
done
或
for I in $(ls /test/*.txt) /可以把.txt改成$1,.doc改成$2,把常量换成变量
do
xx=${i%.*} /删除从右往左第一个点后所有
mv $i $xx.doc
done
########################################
3)按条件掐头去尾
#掐头:从左向右删; %去尾 从右向左删
head -1 /etc/passwd A='root:x:0:0:root:/root:/bin/bash'
echo ${A#*:} /把第一个冒号前面的任意删除
echo ${A##*:} /把所有冒号前面的任意删除
echo ${A%:*} /从右往左算第一个冒号后的所有
echo ${A%%:*} /把所有冒号后面的任意删除
字符串的匹配删除
basename /a/c/b.txt 掐头 = ${A##*/}
dirname /a/c/b.txt 去尾 = ${A%/*}
2.变量初始值处理
1)只取值,${var:-word}
若变量var已存在且非Null,则返回 $var 的值;否则返回字串“word”,原变量var的值不受影响。
2)取值+赋值,${var:=word}
若变量var已存在且非Null,则返回 $var 的值,原变量值不变;否则返回字串“word”,并将此字串赋值给变量 var。
#echo ${TT:-hehe}
########################################
例:密码为空,自动给初始密码
read -p “请输入用户名:” user
read -p “请输入密码:” pass
[ -z $user ] && exit
p=${pass:-123456}
useradd $user &>/dev/null
echo “$p“ | passwd --stdin $user &>/dev/null
或echo “${pass:-123456}“ | passwd --stdin $user &>/dev/null
########################################
求和 1+2+3+4...+100 (5050)
sum=0
for I in {1..100}
do
sum=$[sum+i]
echo $sum
done
########################################
求1到x的和,x为用户输入的数
read -p “请输入数:” num
num=${num:-100}
sum=0
for I in `seq $num`
do
sum=$[sum+i]
done
二、扩展的脚本技巧
1.使用shell数组
建立数组的方法:
格式1,整体赋值:数组名=(值1 值2 .. .. 值n)
格式2,单个元素赋值:数组名[下标]=值
查看数组元素的方法:
获取单个数组元素:${数组名[下标]}
获取所有数组元素:${数组名[@]} (@或* 都表示所有)
获取数组元素个数:${#数组名[@]}
获取连续的多个数组元素:${数组名[@]:起始下标:元素个数}
获取某个数组元素的长度:${#数组名[下标]}
截取数组元素值的一部分:${数组名[下标]:起始下标:字符数}
a=(11 22 33) echo ${a[0] } echo ${a[1] } echo ${a[2] } /获取单个
${a[*] } ${a[@] } /获取所有
b[0]='ss' b[1]='bb' b[2]='cc' echo ${b[*]}
2.expect预期交互
expect可以为交互式过程(比如FTP、SSH等登录过程)自动输送预先准备的文本或指令,而无需人工干预。触发的依据是预期会出现的特征提示文本。
常见的expect指令:
定义环境变量:set 变量名 变量值
创建交互式进程:spawn 交互式命令行
触发预期交互:expect "预期会出现的文本关键词:" { send "发送的文本\r" }
在spawn建立的进程中允许交互指令:interact
########################################
脚本帮我自动输入密码,远程传送数据,预期交互
# yum -y install expect
# rpm -qa | grep expect
#!/bin/bash
for I in {1..254}
do
expect << EOF
set timeout 30
spawn ssh -o StrictHostKeyChecking=no 172.25.0.$i /交互式命令行
expect “password” {send “redhat\r” } / 表示回车\r
expect “#” {send “touch /root/abc.txt\r” }
expect “#” {send “exit\r” }
EOF
echo “连接172.25.0.$i 成功!”
done
删掉这个记录登录过的用户的文件/root/.ssh/known_hosts前面都需要先加入yes 。
man expect /timeout
ssh-keygen
spawn ssh-copy-id 172.25.0.$i
########################################
三、正则表达式
1.概述
一种表达方式:使用“ 一串符号 ” 来描述有共同属性的数据。如:语言、手语、眼神……
计算机里的通用语,使用的是一些规定好的符号^ $
绝大多数软件都支持正则表达式,如ps,word,grep,vim,java,shell,python……
grep、egrep 过滤工具,常用命令选项
-i:忽略字母大小写
-v:条件取反
-c:统计匹配的行数
-q:静默、无任何输出,一般用于检测,看$?返回值,为0匹配,否则不匹配
-n:显示出匹配结果所在的行号
- -color:标红显示匹配字串
-E : 调用egrep
#grep “^$” /etc/passwd /空白行
#grep “^root” /etc/passwd
#grep “[0-9]” /etc/passwd
#grep “[A-Z]” /etc/passwd
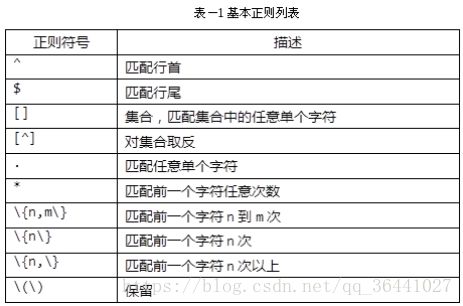
2.基本正则:
特点:处理单位是单个字符;兼容性强,支持软件多;缺点麻烦
^ 开始
$ 结尾
[ ] 集合,之一 [a-Z] = [a-zA-Z]
[^] 取反 [^abc] 不需要abc
. 任意单个字符,与操作系统里的?同义
.. 任意两个字符
* 匹配前一个字符出现的任意次 ab* 一定包含a,且b可以出现的任意次包括0次
.* 匹配任意所有 与操作系统里的*同义 a.* 以a开头的所有
\{n,m\} 匹配前一个字符出现了n到m次,m不写表示上不封顶 a\{3,5\} 匹配3-5个a
\{n\} 匹配前一个字符出现n次 a\{3\} 匹配3个a
\(\) 括号里面的东西都被复制了
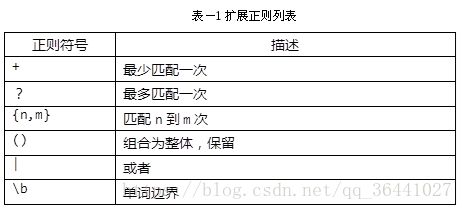
3.扩展正则:
特点:处理单位不是单个字符 (ab)* ab为一个整体
简单,兼容性差 grep 不支持扩展正则,egrep支持,加强版grep
简化基本正则:\{n,m\} → {n,m} (test|taste) 或者
添加新的符号: + ? | \b ()
如: a+ 表示a至少出现一次 a? 表示a可有可无 taste?
\b 单词分界点,前后都加表示该单词独立 # grep “\bthe\b” 1.txt
########################################
将ipv4地址单独过滤出来
# ifconfig | grep "\b[0-9]\{1,3\}\.\{1\}[0-9]\{1,3\}\.\{1\}[0-9]\{1,3\}\.\{1\}[0-9]\{1,3\}\b"
# ifconfig | grep -E "([0-9]{1,3}\.){3}[0-9]{1,3}"
########################################
2.基本元字符
行首尾及单字匹配: ^ 开始 $ 结尾 . 任意单个字符
未定义匹配次数: + ? *
{ } 限定表达式匹配的次数:{n} {n,m} {n,}
3.其他元字符
[ ]范围内单字匹配,匹配指定字符i集合内的任何一个字符:
[ ] 内加^ 可取反 : [a|c45_?] [a-z] [A-Z] [0-9] [a-Z0-9] [^A-Z] ^[^a-z]
整体及边界匹配:() | \b \< \>
\ 为转义符号,可以为一些普通字符赋予特殊含义,或者将一些特殊字符变为普通字符。
########################################
过滤 test 或 taste 这两个单字 # grep 't[ae]ste\{0,1\}' 1.txt
过滤不想要 oo 前面有 g 的 # grep '[^g]oo' 1.txt
过滤开头不是英文字母 # grep '^[^aZ]' 1.txt
过滤行尾结束为小数点.那一行 # grep “\.$” 1.txt
过滤出 g??d 的字串 # grep “g..d” 1.txt
过滤下载文件中包含 the 关键字 #grep 'the' 1.txt
过滤下载文件中不包含 the 关键字 # grep -v 'the' 1.txt
过滤下载文件中不论大小写 the 关键字 # grep -i 'the' 1.txt
过滤 test 或 taste 这两个单字 #grep 't[ae]st' 1.txt
过滤有 oo 的字节 #grep 'oo' 1.txt
过滤不想要 oo 前面有 g 的 #grep '[^g]oo' 1.txt
过滤 oo 前面不想有小写字节 #grep '[^a-z]oo' 1.txt
过滤有数字的那一行 #grep '[0-9]' 1.txt
过滤以 the 开头的 #grep '^the' 1.txt
过滤以小写字母开头的 #grep '^[a-z]' 1.txt
过滤开头不是英文字母 #grep '^[^a-zA-Z]' 1.txt
过滤行尾结束为小数点.那一行 #grep '\.$' 1.txt
过滤空白行 #grep '^$' 1.txt
过滤出 g??d 的字串 #grep 'g..d' 1.txt
过滤至少两个 o 以上的字串 #grep 'ooo*' 1.txt
过滤 g 开头和 g 结尾但是两个 g 之间仅存在至少一个o #grep 'goo*g' 1.txt
过滤任意数字的行 #grep '[0-9][0-9]*' 1.txt
过滤两个 o 的字串 #grep 'o\{2\}' 1.txt
过滤 g 后面接 2 到 5 个 o,然后在接一个 g 的字串 #grep 'go\{2,5\}g' 1.txt
过滤 g 后面接 2 个以上 o 的 #grep 'go\{2,\}g' 1.txt