PyTorch 修炼篇(一) : CIFAR-10 分类模型
学习参考:pytorch-cifar
import os
import time
import torch
import torch.nn as nn # 神经网络工具箱
import torch.nn.functional as F # functional中的函数是一个确定的不变的运算公式,输入数据产生输出就ok。
import numpy as np
from torch.autograd import Variable
from torch.utils.data.dataloader import DataLoader
import torchvision.datasets as datasets # 数据模块
import torchvision.transforms as transforms # 数据变换模块
import matplotlib.pyplot as pltCIFAR-10数据加载和处理
我们使用CIFAR10数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为验证集。这次我们只对其中的猫和狗两类进行预测。
BATCH_SIZE = 128
# 由于torchvision的datasets输入[0,1]的PILmage,所以先归一化为[-1,1]的Tensor
transform = transforms.Compose(
[transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))] # 归一化分别为RGB三通道的均值和标准差
)
# Load the raw CIFAR-10 data.
# 下载数据然后进行变换
train_data = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform) # download如果为True,则网上下载,若已有下载好的数据就不会重复下载
test_data = datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
# 通过train_loader把数据传入网络
# 参数num_works:用多少个子进程加载数据。0表示数据将在主进程中加载(默认:0)
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True)Files already downloaded and verified
Files already downloaded and verified
定义神经网络
# 用于ResNet18和34的残差快,用的是两层的恒等残差快即2个3x3
class BasicBlock(nn.Module): # nn.Module是所有神经网络的基类,自己定义的任何神经网络都要继承nn.Module
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__() # 第四、五行都是python类继承的基本操作,此写法应该是python2.7的继承格式,但python3里写这个好像也可以
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, # 输入in_planes个通道,输出planes的通道即planes个卷积核
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
# 经过处理后的x 要与 x 的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一纬度
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out) # 不具备可学习参数的层,将它们用函数代替,这样可以不用放在构造函数中进行初始化。
# reLu其实没有可学习的参数,只是进行运算而已,所以使用functional中的relu函数
# 而卷积层和全连接层都有可学习的参数,所以用的是nn.Module中的类
return out
# 用于ResNet50,101和152的残差块,用的是1x1 + 3x3 + 1x1的卷积
class Bottleneck(nn.Module):
# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion * planes,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.shorcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shorcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shorcut(x)
out = F.relu(out)
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 池化层
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512 * block.expansion, num_classes) # 线性层
def _make_layer(self, block, planes, num_blocks, stride=1):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.maxpool(self.bn1(self.conv1(x))))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
# out = F.avg_pool2d(out, 7, stride=1) # [(7 - 7 + 0) / 1] + 1 = 1. 所以最后输出1x1
out = F.avg_pool2d(out, 1, stride=1) # [(1 - 1 + 0) / 1] + 1 = 1. 所以最后输出1x1
out = out.view(out.size(0), -1) # .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def ResNet50():
return ResNet(Bottleneck, [3, 4, 6, 3])
def ResNet101():
return ResNet(Bottleneck, [3, 4, 23, 3])
def ResNet152():
return ResNet(Bottleneck, [3, 8, 36, 3])
# if __name__ == "__main__":
use_gpu = torch.cuda.is_available()
device = torch.device("cuda" if use_gpu else "cpu")
print('use: ', device)
# 定义神经网络
net = ResNet34().to(device) # 通过to方法,可在CPU和GPU之间相互移动
print(net)use: cuda
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(linear): Linear(in_features=512, out_features=10, bias=True)
)
定义损失函数和优化器
import torch.optim as optim # 深度学习中常用的优化方法都封装于此
criterion = nn.CrossEntropyLoss() # 用到神经网络工具箱nn中的交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # optim模块中的SGD梯度优化方式---随机梯度下降训练网络
第一节:把最开始放在trainloader里面的数据给转换成variable,然后指定为网络的输入;
第二节:每次循环新开始的时候,要确保梯度归零
第三节:forward+backward,就是调用我们在第三步里面实例化的net()实现前传,loss.backward()实现后传
每结束一次循环,要确保梯度更新
all_train_costs = [] # 获取每个iter的平均训练损失
all_train_accs = []
test_cost = [] # 获取epoch的平均测试损失
test_accs = []
best_acc = 0 # best test accuracy
EPOCH_NUM = 20
for pass_id in range(EPOCH_NUM):
print('\nTraining epoch:%d' % pass_id)
# 开始训练
net.train() # 同下面的net.eval(): 是针对网络训练和测试时采用不同方式的情况,如:Batch Normalization和Droupout
running_loss = 0.0 # 定义一个变量方便我们对loss进行输出
correct = 0.0
total = 0
timestart = time.time()
for batch_id, data in enumerate(train_loader, 0): # 每个小批量输出
inputs, labels = data # data是从enumberate返回的data,包含数据和标签信息,分别赋值给inputs和labels
if use_gpu:
inputs, labels = inputs.cuda(), labels.cuda()
# zero the parameter gradients
optimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度
# forward + backward + optimize
outputs = net(inputs) # 把每个批量数据输入网络
loss = criterion(outputs, labels) # 计算每个批量的损失值
loss.backward() # loss进行反向传播,自动计算所有的梯度
optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮
# print statistics
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 此时这里的correct是tensor,而python自动创建的tensor类型是torch.LongTensor。
# 在pytorch中的int/long之间的运算得到的还是整形。
# 需要用item()转化为标量,即还原到基本的python运算。
# iter的训练结果
all_train_costs.append(running_loss / total) # 样本平均损失
all_train_accs.append(correct / total) # 样本平均正确率
if batch_id % 391 == 390: # print every 391 mini-batches
print('[%d, %5d] Loss: %.3f | Acc: %.3f%% (%d/%d)' %
(pass_id, batch_id, running_loss / total, 100.*correct/total, correct, total))
print('Epoch:{:d}| loss:{:.3f} acc:{:.3f} time:{:.2f}s'.format(pass_id, running_loss / total, correct/total, time.time() - timestart), end=' ')
print('\nTesting epoch:%d' % pass_id)
# 开始测试
net.eval()
test_loss = 0.0
correct = 0.0
total = 0
with torch.no_grad():
for batch_id, data in enumerate(test_loader): # 循环每一个batch
images, labels = data
if use_gpu:
images, labels = images.cuda(), labels.cuda()
outputs = net(images) # 输入网络进行测试
loss = criterion(outputs, labels)
test_loss += loss.item()
_,predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Epoch: %d | Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (pass_id, test_loss/total, 100.*correct/total, correct, total))
# epoch的测试结果
test_cost.append(test_loss / total) # 这里师兄那代码是loss.item()
test_accs.append(correct / total)
# save checkpoint.
acc = 100.*correct/total
if acc > best_acc:
print('Saving..')
state = {
'net': net.state_dict(),
'acc': acc,
'epoch': pass_id,
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/ckpt.pth')
best_acc = acc
print('Finished Training and Testing !') Training epoch:0
[0, 390] Loss: 0.012 | Acc: 43.816% (21908/50000)
Epoch:0| loss:0.012 acc:0.438 time:151.05s
Testing epoch:0
Epoch: 0 | Loss: 0.010 | Acc: 52.960% (5296/10000)
Saving..
Training epoch:1
[1, 390] Loss: 0.009 | Acc: 58.678% (29339/50000)
Epoch:1| loss:0.009 acc:0.587 time:149.10s
Testing epoch:1
Epoch: 1 | Loss: 0.009 | Acc: 59.990% (5999/10000)
Saving..
Training epoch:2
[2, 390] Loss: 0.007 | Acc: 66.418% (33209/50000)
Epoch:2| loss:0.007 acc:0.664 time:149.77s
Testing epoch:2
Epoch: 2 | Loss: 0.008 | Acc: 64.500% (6450/10000)
Saving..
Training epoch:3
[3, 390] Loss: 0.006 | Acc: 72.142% (36071/50000)
Epoch:3| loss:0.006 acc:0.721 time:149.77s
Testing epoch:3
Epoch: 3 | Loss: 0.008 | Acc: 63.460% (6346/10000)
Training epoch:4
[4, 390] Loss: 0.005 | Acc: 76.526% (38263/50000)
Epoch:4| loss:0.005 acc:0.765 time:149.15s
Testing epoch:4
Epoch: 4 | Loss: 0.008 | Acc: 66.690% (6669/10000)
Saving..
Training epoch:5
[5, 390] Loss: 0.004 | Acc: 79.876% (39938/50000)
Epoch:5| loss:0.004 acc:0.799 time:149.68s
Testing epoch:5
Epoch: 5 | Loss: 0.008 | Acc: 67.810% (6781/10000)
Saving..
Training epoch:6
[6, 390] Loss: 0.004 | Acc: 83.128% (41564/50000)
Epoch:6| loss:0.004 acc:0.831 time:149.23s
Testing epoch:6
Epoch: 6 | Loss: 0.008 | Acc: 68.190% (6819/10000)
Saving..
Training epoch:7
[7, 390] Loss: 0.003 | Acc: 86.184% (43092/50000)
Epoch:7| loss:0.003 acc:0.862 time:149.85s
Testing epoch:7
Epoch: 7 | Loss: 0.009 | Acc: 66.930% (6693/10000)
Training epoch:8
[8, 390] Loss: 0.003 | Acc: 88.460% (44230/50000)
Epoch:8| loss:0.003 acc:0.885 time:149.49s
Testing epoch:8
Epoch: 8 | Loss: 0.009 | Acc: 67.520% (6752/10000)
Training epoch:9
[9, 390] Loss: 0.002 | Acc: 90.346% (45173/50000)
Epoch:9| loss:0.002 acc:0.903 time:149.96s
Testing epoch:9
Epoch: 9 | Loss: 0.010 | Acc: 67.770% (6777/10000)
Training epoch:10
[10, 390] Loss: 0.002 | Acc: 91.584% (45792/50000)
Epoch:10| loss:0.002 acc:0.916 time:149.25s
Testing epoch:10
Epoch: 10 | Loss: 0.009 | Acc: 68.740% (6874/10000)
Saving..
Training epoch:11
[11, 390] Loss: 0.001 | Acc: 93.290% (46645/50000)
Epoch:11| loss:0.001 acc:0.933 time:149.49s
Testing epoch:11
Epoch: 11 | Loss: 0.010 | Acc: 68.630% (6863/10000)
Training epoch:12
[12, 390] Loss: 0.001 | Acc: 94.270% (47135/50000)
Epoch:12| loss:0.001 acc:0.943 time:149.27s
Testing epoch:12
Epoch: 12 | Loss: 0.010 | Acc: 69.860% (6986/10000)
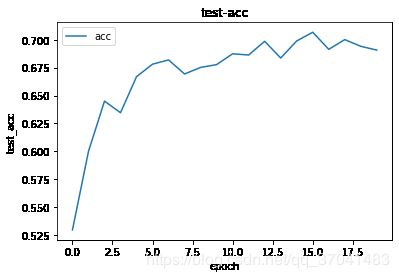
Saving..
Training epoch:13
[13, 390] Loss: 0.001 | Acc: 95.076% (47538/50000)
Epoch:13| loss:0.001 acc:0.951 time:149.41s
Testing epoch:13
Epoch: 13 | Loss: 0.011 | Acc: 68.360% (6836/10000)
Training epoch:14
[14, 390] Loss: 0.001 | Acc: 95.912% (47956/50000)
Epoch:14| loss:0.001 acc:0.959 time:149.70s
Testing epoch:14
Epoch: 14 | Loss: 0.011 | Acc: 69.890% (6989/10000)
Saving..
Training epoch:15
[15, 390] Loss: 0.001 | Acc: 96.218% (48109/50000)
Epoch:15| loss:0.001 acc:0.962 time:149.20s
Testing epoch:15
Epoch: 15 | Loss: 0.011 | Acc: 70.670% (7067/10000)
Saving..
Training epoch:16
[16, 390] Loss: 0.001 | Acc: 96.732% (48366/50000)
Epoch:16| loss:0.001 acc:0.967 time:148.99s
Testing epoch:16
Epoch: 16 | Loss: 0.011 | Acc: 69.140% (6914/10000)
Training epoch:17
[17, 390] Loss: 0.001 | Acc: 97.200% (48600/50000)
Epoch:17| loss:0.001 acc:0.972 time:150.15s
Testing epoch:17
Epoch: 17 | Loss: 0.012 | Acc: 70.010% (7001/10000)
Training epoch:18
[18, 390] Loss: 0.001 | Acc: 97.354% (48677/50000)
Epoch:18| loss:0.001 acc:0.974 time:150.21s
Testing epoch:18
Epoch: 18 | Loss: 0.012 | Acc: 69.410% (6941/10000)
Training epoch:19
[19, 390] Loss: 0.001 | Acc: 97.364% (48682/50000)
Epoch:19| loss:0.001 acc:0.974 time:149.82s
Testing epoch:19
Epoch: 19 | Loss: 0.012 | Acc: 69.070% (6907/10000)
Finished Training and Testing !
画loss与acc的关系图
def draw_loss_acc(loss, acc, mode='train'):
iters = len(loss) # 若model==train时,即为iter的长度。若mode==test时,iters为epoch的长度。
plt.plot(range(iters), np.ones(iters), 'r--', label='1')
plt.plot(range(iters), loss, label='loss')
plt.plot(range(iters), acc, label='acc')
plt.title(mode)
if mode == 'train':
plt.xlabel('iter') # 训练时保存的是iter的损失
else:
plt.xlabel('epoch') # 测试时保存的epoch的损失
plt.ylabel('loss_acc')
plt.legend()
plt.savefig(os.path.join('lost_acc','loss_acc_{}.png'.format(mode)))
plt.show()
plt.clf()draw_loss_acc(all_train_costs, all_train_accs, 'train')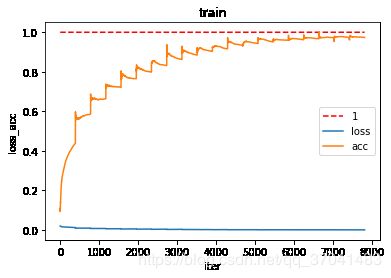
draw_loss_acc(test_cost,test_accs,'test')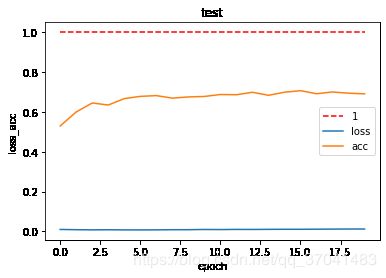
画单独的loss or acc的图
def draw_loss_or_acc(data, label, mode='train'):
iters = len(data)
plt.plot(range(iters),data, label=label)
plt.title(mode+'-'+label)
if mode == 'train':
plt.xlabel('iter')
else:
plt.xlabel('epoch')
plt.ylabel(mode + '_' +label) # 俩字符串拼接
plt.legend()
plt.savefig(os.path.join('lost_acc','{}_{}.png'.format(label,mode)))
plt.show()
plt.clf()draw_loss_or_acc(all_train_costs,'cost','train')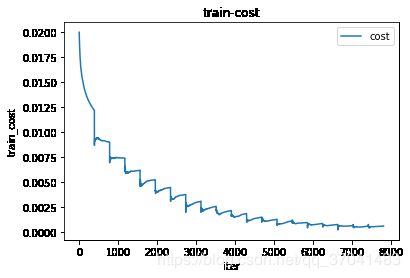
draw_loss_or_acc(all_train_accs,'acc','train')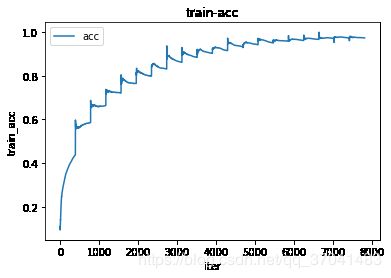
draw_loss_or_acc(test_cost,'cost','test')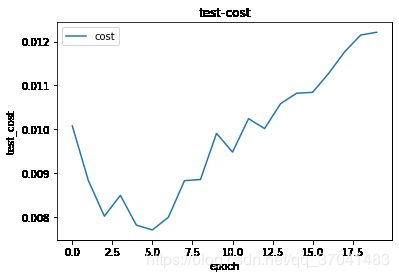
draw_loss_or_acc(test_accs,'acc','test')