操作系统学习笔记(八)---内存管理(分页、分段机制)
目录
一、内存管理硬件设计&地址空间
二、内存管理方法
连续内存分配(contiguous memory allocation)
多分区方案(multiple-partition method)
可变分区方案(variable-partition)
碎片(fragmentation)
非连续内存分配
分段机制(segmentation)
分页机制(paging)
TLB(translation-lookaside buffer )
多级页表
页置换策略
附:内核内存的分配
Buddy系统
Slab分配
一、内存管理硬件设计&地址空间
CPU能直接访问的存储器只有内存和处理器内的寄存器,机器指令可以用内存地址作参数而不能以磁盘地址作参数。因此,执行指令以及执行使用的数据必须在这些可直接访问的存储设备上。
基地址寄存器(base register)和界限地址寄存器(limit register)
每个进程都应该有独立的内存空间,需要确定一个进程可访问的合法地址的范围,并确保进程只访问其合法地址。基地址寄存器含有最小的合法物理内存地址,界限地址寄存器决定了范围的大小。
e.g:
基地址寄存器值为300040,界限寄存器为120900,那么程序可以合法访问从300040~420940(含)的所有地址。
内存空间保护的实现,是通过CPU硬件对用户模式所产生的每一个地址与寄存器的地址进行比较来完成的。只有操作系统可以通过特殊的特权指令来加载这两个寄存器。

地址空间
段机制启动、页机制未启动:逻辑地址->段机制处理->线性地址=物理地址
段机制和页机制都启动:逻辑地址->段机制处理->线性地址->页机制处理->物理地址
虚拟地址应该等价于逻辑地址(课本),但是因为对程序员而言可见的只有线性地址,有时候也把线性地址称为虚拟地址?
CPU所生成的地址通常称为逻辑地址(logical address),而内存单元所看到的的地址(即被加载到内存地址寄存器(memory-address register)中的地址)通常被称为物理地址(physical address)。
由程序所生成的所有逻辑地址的集合称为逻辑地址空间(logical address space)
与这些逻辑地址相对应的所有物理地址的集合称为物理地址空间(physical address space)
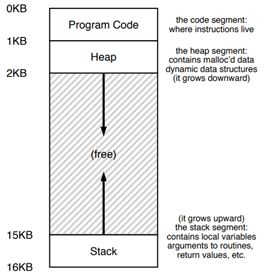
物理地址空间的大致布局:
虚拟地址空间(VM)的三个特征
1.Transparency(透明性、不可见的)
每个进程都认为它有独立的物理地址空间且不会认识到物理内存被虚拟化了。操作系统和硬件负责完成虚拟地址到物理地址的转化。
2.Efficiency(有效性)
从时间(不能让进程运行得很慢)、空间(不能占用过多的物理内存)等角度考虑,这就需要很多硬件支持,如TLB。
3.Protection
OS需要保证进程之间以及进程与OS之间不会发生冲突/物理内存不会相互覆盖,保护机制允许了进城之间的共享代码/数据。
对虚拟地址空间的解释:OS需要建立一个便于使用的物理内存的抽象,这个抽象便是(虚拟)地址空间。对于进程而言,可见的只是(虚拟)地址空间而不是物理内存,即其使用的地址都是虚拟地址,由OS转化为物理地址。
运行时从虚拟地址(这里指的是逻辑地址)到物理地址的映射是由内存管理单元(memory-management unit,MMU)的硬件设备来完成的。有许多方案可以完成这种映射。

一种简单的方案就是使用基地址寄存器,在这里称为重定位寄存器(relocation register)。用户进程所生成的地址在送交内存之前,都将加上重定位寄存器的值(如图)。
二、内存管理方法
内存通常分为两个区域:一个用于驻留操作系统,另一个用于用户进程。操作系统可以位于低内存,也可以位于高内存。影响这一决定的主要因素是中断向量的位置,由于中断向量通常位于低内存,所以操作系统也常常位于低内存……
连续内存分配(contiguous memory allocation)
这里讨论的是如何为需要调入内存的进程分配内存空间的方案,采用连续内存分配时,每个进程位于一个连续的内存区域。
连续内存分配有两个重要的技术:Splitting and Coalescing(姑且翻译为分裂和合并)

Splitting简单来说就是一个空闲内存块有10B,一个进程需要1B,那么我们把这个空闲块分为2部分:1B和9B。

Coalescing是针对进程释放内存后的操作,即将连续的空闲块合并。

上图中的三个空闲块会合并(如上图)。
多分区方案(multiple-partition method)
将内存分为多个大小固定的分区(partition),每个分区只能容纳一个进程。
当一个分区空闲时,可以从输入队列(等待队列)中选择一个进程,以调入到空闲分区。当进程终止时,其分区可以被其他进程所使用。
可变分区方案(variable-partition)
操作系统维护一个表,用于记录哪些可用和已被占用,把可用的内存块称为一个个的孔(hole)。
一开始所有内存作为1个孔,当有新进程需要内存时,为该进程查找足够大的孔,如果找到,为该进程分配所需的内存,孔内未分配的内存可以下次再用。
如何为新的进程分配合适的孔?
首次适应(first-fit):分配第一个足够大的孔,查找可以从头开始,也可以从上次first-fit结束时开始。
下次适应(next-fit):作为first-fit的优化而提出,使用一个指针记录上次搜索完成时的位置,下次分配时,从该记录位置开始搜索,到达链表尾部则绕回。该指针在空闲链表内循环游动,从而避免了在链表头部区域堆积过多的碎片。
最佳适应(best-fit):分配最小的足够大的孔。需要查找整个列表(或者列表按大小排序),这种方法可以产生最小剩余孔。
最差适应(worst-fit):分配最大的孔。需要查找整个列表。这种方法可以产生最大剩余孔
性能分析:主要从时间和空间两个方面来考虑
First-fit:查询(空闲块)速度较好,但是会在空闲链表开始部分产生较多的碎片
Best-fit:时间开销大,减少了浪费的空间
Worst-fit:时间开销大,空间利用率低,往往不是很好
碎片(fragmentation)
外部碎片及其解决方案:

简单来说,外部碎片就是内存中进程之间的(小)空闲块。
紧缩(compaction)是一种解决外部碎片的方案(如图,开销很大)
内部碎片:简单来说就是分配个一个进程的内存空间中未使用的那部分内存。加入一个进程需要1000KB,我们分配了一个1002KB的孔,那剩下的2KB就是碎片(这是无法使用的?)。
于是为了解决碎片问题就需要分段和分页技术,其根本思想是允许物理地址空间是非连续的。
非连续内存分配
段机制启动、页机制未启动:逻辑地址->段机制处理->线性地址=物理地址
段机制和页机制都启动:逻辑地址->段机制处理->线性地址->页机制处理->物理地址
分段机制(segmentation)
参考
https://objectkuan.gitbooks.io/ucore-docs/content/lab1/lab1_3_2_1_protection_mode.html
https://www.cnblogs.com/chenwb89/p/operating_system_003.html
先理解4个名词:
逻辑地址:分段机制下CPU把逻辑地址分为段选择子selector和段偏移offset
段描述符(描述段的属性):由三部分参数组成:段基地址(Base Address)、段界限(Limit)和段属性(Attributes)
段描述符表(包含多个段描述符的“数组”):分为GDT和LDT,大概就是全局和局部的关系。
段选择子(段寄存器,用于定位段描述符表中表项的索引):细节见网址
然后简单介绍下逻辑地址转换成物理地址的过程:
CPU把逻辑地址(由段选择子selector和段偏移offset组成)中的段选择子的内容作为段描述符表的索引,找到表中对应的段描述符,然后把段描述符中保存的段基址加上段偏移值,形成线性地址(Linear Address)。如果不启动分页存储管理机制,则线性地址等于物理地址。
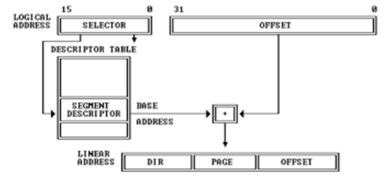
上图是分段和分页机制的结合。
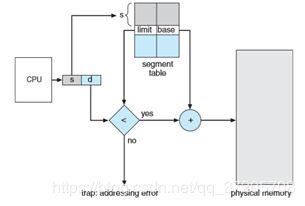

这个图是单纯的分段。
注意得到线性地址后会做一个检查,通过段描述符里的段基址和段界限
举个例子
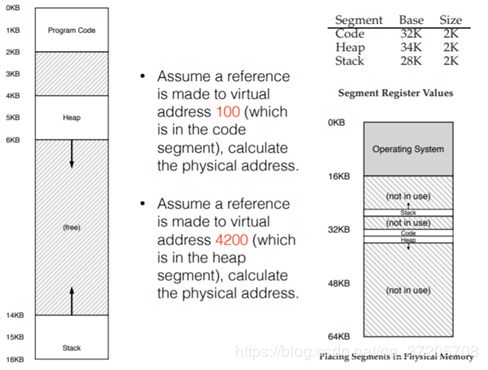
4200这个逻辑地址(虚拟地址)被划分为段选择子和段偏移,
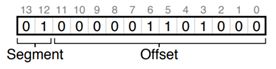
它的段偏移就是0000 0110 1000, or hex 0x068, or 104 in decimal,段选择子01选的是34K,最后的线性地址(物理地址)就是34K+104
注意段偏移是从上往下看还是从下往上看的问题,同时堆的计算和栈的计算(偏移不是实际的)是不一样的,最好先列出映射范围。下图给出的是虚拟地址15KB转换成物理地址27KB的过程。

优点:支持用户视角,实现简单,可以有效利用内存。
缺点:无法利用碎片,必须搬移内存,造成性能损失(管理空闲空间较难)。
分页机制(paging)
分页(paging)内存管理方案允许进程的物理地址空间可以是非连续的。
基本概念:
将物理内存分为固定大小的块,称为帧(frame);将逻辑内存也分为同样大小的块,称为页(page)。
每个进程有独立的页表。CPU生成的地址(虚拟地址)被分为两个部分:页号和偏移,页号作为页表中的索引,页表中的每一项称为页表条目,页表条目存储地址转换的信息。
每新建一个进程OS都会为其新建一个页表,即使虚拟地址相同但映射到的物理地址是不同的。页表往往可能很大,所以存储在物理内存中。
分页机制虚拟地址转换为物理地址的公式大致如下:
![]()
VPN_MASK用于从虚拟地址中获取部分位
PageTableBaseRegister(PTBR):页基表寄存器,指向页表基址,改变页表只需要改变这个寄存器即可。
这样访问一个字节就需要两次内存访问(一次用于页表条目,一次用于字节)。
优点:易于对空闲空间的管理,更具有灵活性(能够有效地支持物理地址空间的抽象)
缺点:实现复杂,不正确地使用会导致速度过慢(获得进程的页表信息需要一次额外的内存访问),同时有很大的内存浪费(页表需要占用物理内存)
TLB(translation-lookaside buffer )
A TLB is part of the chip’s memory-management unit (MMU), and is simply a hardware cache of popular virtual-to-physical address translations.
Upon each virtual memory reference, the hardware first checks the TLB to see if the desired translation is held therein; if so, the translation is performed (quickly) without having to consult the page table.
TLB主要用于加速地址转换的过程,其是一个小而块的专用的硬件缓冲(硬件昂贵),通常TLB能存储64~1024个条目(页号和帧号组成的键值对)。
注意VPN对于页表来说只是偏移,页表不存储VPN;
VPN对于TLB来说是需要存储的
![]()
而且对于页表条目和TLB条目来说其valid(有效位)的含义是不同的
页表条目的valid表示并没有给这个虚拟页分配/映射物理页
TLB的valid表示这个条目是否有效/存在
如果发生上下文切换(进程切换),TLB应该如何设置才能为进程提供地址保护?

如上图,假设PFN(100)为进程P1的,PFN(170)为进程P2的,TLB就无法区分。
解决方案:
①每次选择一个新的页表时,就flush(冲刷/删除)TLB,即设置所有的valid位为0,这明显会有较大的时间开销。
②在每个TLB条目中保存地址空间标识符(address-space identifier,ASID),ASID可用来唯一地标识进程。当TLB试图解析虚拟页号时,它确保当前运行进程的ASID与虚拟页相关的ASID相匹配。这样ASID就能允许TLB包含不同进程的条目。


The MIPS R4000 supports a 32-bit address space with 4KB pages.
Thus, we would expect a 20-bit VPN and 12-bit offset in our typical virtual address. However, there are only 19 bits for the VPN; and user addresses will only come from half the address space (the rest reserved for the kernel) and hence only 19 bits of VPN are needed.
The VPN translates to up to a 24-bit physical frame number (PFN), and hence can support systems with up to 64GB of (physical) main memory (224 4KB pages)

概述一下TLB和页表一起使用的流程:
当CPU产生逻辑地址后,其VPN提交给TLB,如果TLB命中则得到了帧号并可用来访问内存。如果TLB失效,则需要访问页表,同时将页号和帧号增加到TLB中。如果TLB条目已满,那么OS会选择一个来替换,替换策略有多种如LRU。另外,有的TLB允许某些条目固定,即不会替换它们,如内核代码的条目。
到这里我们再回过头看看PTE中到底有什么

valid bit:表示一个虚拟页到物理页的映射关系是否实际存在
protection bit:表示一个页是否可读/写或和其他一些操作
present bit:这个页在物理内存还是在磁盘(被换出了)
dirty bit:indicating whether the page has been modified since it was brought into memory.(脏位,该页是否被修改过)
A reference bit (a.k.a. accessed bit):表示该页是否被访问过,用于页置换机制(如Clock算法)
多级页表
多级页表的目标是减少页表占用的物理内存。下面分析如何用二级页表表示一个线性页表。
Imagine a small address space of size 16KB, with 64-byte pages. Thus, we have a 14-bit virtual address space, with 8 bits for the VPN and 6 bits for the offset.
给出物理地址空间为16KB,页大小为64bytes,由此推算出虚拟地址空间多少位以及VPN和VPO
页大小决定了页偏移64Bytes->6 bit
2^4 X 2^10 / 2^6 = 2^8 即物理地址空间被分为256个物理页,则我们需要用8 bit来表示物理页号PFN,又因为VPN与PFN一一对应,所以VPN用8 bit来表示
A linear page table would have 2^8 (256) entries(假如用线性页表表示)
要知道如何用二级页表表示这个线性页表,首先需要计算出这个线性页表所占用的物理内存

显然,这个页表有256个entries,假设每个PTE是4bytes(没有这个假设则无法计算),那么整个PTE就是1KB,需要分配16个64bytes的物理页(每个物理页可分配16个页表条目)。
The page directory needs one entry per page of the page table; thus, it has 16 entries.
As a result, we need 4 bits of the VPN to index into the directory; we use the top four bits of the VPN, as follows
对于页目录来说,每个页目录表条目对应的是页表的1个物理页,因此就有16个entries

![]()
![]()
PDBR一般用的是CR3寄存器,其锁定到一个物理页。CR3寄存器的保存与恢复是在与上下文切换相关任务的TSS段中进行的(每个进程不同)。
CPU要读取某个数据,采用线性页表时,最坏情况下需要几次访存操作?采用二级页表时,最坏情况下需要几次访存操作?
线性页表:最坏情况下,假设该物理页在磁盘上(这里不考虑访问外存?以及中断恢复不需要重新访问页表?那最坏不就等同于必须了么,二级页表必须3次)
->页表->(缺页异常处理)->内存字节
1 2
->页目录表->二级页表(可能需要创建)->(缺页异常处理)->内存字节
1 2 3
举个例子:二级页表的计算

In this example, instead of allocating the full sixteen pages for a linear page table, we allocate only three: one for the page directory, and two for the chunks of the page table that have valid mappings.
Here is an address that refers to the 0th byte of VPN 254: 0x3F80.
Calculate the physical address of 0x3F80
过程:0x3F80 = 1111 1110 000000
PDI=1111 PTI=1110 VPO = 000000
Page Directory这里直接给出了,PDI就是个偏移(在锁定的物理页上的),我们找到第15个看valid为1得到PFN=101,这里的PFN指的是物理页号(这里表示的是我们的二级页表在那个物理页,整个物理内存相当于一个0开始的PFN标记的序列)。然后我们找到PFN=101的物理页,再看PTI这个偏移为14,找到第14个位置valid为1得到PFN=55,这个PFN也是物理页号(表示我们要找的byte在哪个物理页上),最后拼接得到物理地址0101 0101 000000
页置换策略
需要被换出的页的特征是什么?
需要被换出的页的特征是“不常用”。不同的页替换算法对该定义有不同的解释,FIFO页替换算法总是淘汰最先进入内存的页,时钟页替换算法淘汰未被访问过的页。
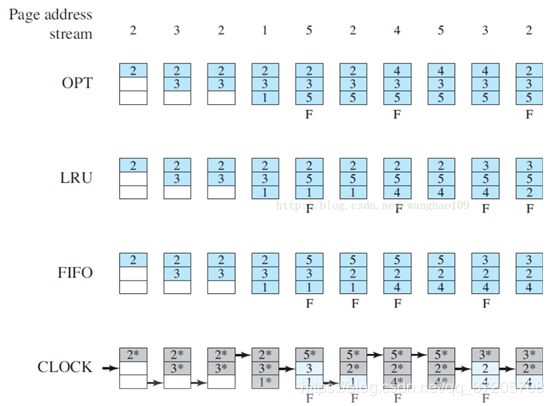
FIFO:置换时选择最旧的页置换,可以创建一个FIFO队列来管理内存中的页。
OPT(optimal page-replacement algorithm):最优页置换算法,假设已经知道之后要访问哪些页(这往往是不可能的),选择1个最长时间不会用的页替换掉。
LRU(least-recently-used):最近最少使用算法,将最长时间未使用的页置换掉。可以用计数器或栈来实现,无论用哪一种方法,每次内存引用都必须更新时钟域或者栈,首先这需要硬件支持,其次如果每次更新都采用中断来实现时间开销将大幅度上升。
CLOCK(二次机会算法/近似模拟LRU):选择一个页时,检查其引用位,如果值为0就直接置换该页,如果值为1,则给这个页第二次机会(置为0)并继续往下选择。实现方法:通常页以循环队列组织管理,用一个指针表示下次要置换哪个页。

Belady现象
指的是对有的页置换算法,页错误率(缺页次数/总访问次数)可能随着分配的帧数的增加而增加。
举个例子说明Belady异常:用串1,2,3,4,1,2,5,1,2,3,4,5
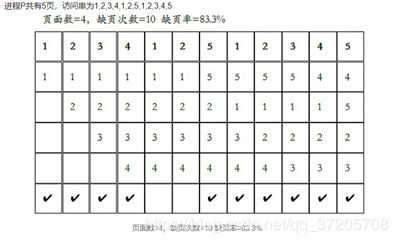

推荐这么画过程

附:内核内存的分配
内核内存的分配通常是从空闲内存池中获取的,而不是从满足普通用户模式进程的内存链表中获取的。主要有如下两个原因:
1.内核需要为不同大小的数据结构分配内存,其中有的不到一页。因此,内核必须谨慎使用内存,并试图减低碎片浪费。
2.有的硬件要直接与物理内存打交道,而不需要经过虚拟内存接口,因此需要内存常驻在连续的物理页中。用户进程所分配的页不必要在连续的物理内存中。
Buddy系统
概述:从物理上连续的大小固定的段上进行分配,内存按2的幂的大小来进行分配。
优点:可通过合并而快速地形成更大的段,解决了外碎片的问题
缺点:采用buddy算法,解决了外碎片问题,这种方法适合大块内存请求,不适合小内存区请求。虽然减少了内碎片,但没有显著提高系统效率。
实现:

假设连续内存段的大小原来为256KB,而内核申请21KB内存,就会按如图所示来等分内存,直到得到一个最小的可满足需求的空闲内存块(32KB再往下分不满足),最后用CL来满足内存请求。
如果上述CL被释放,则会自底向上合并为原来256KB的段。
Slab分配
Slab分配器思想
1)小对象的申请和释放通过slab分配器来管理。
2)slab分配器有一组高速缓存,每个高速缓存保存同一种对象类型,如i节点缓存、PCB缓存等。
3)内核从它们各自的缓存种分配和释放对象。
4)每种对象的缓存区由一连串slab构成,每个slab由一个或者多个连续的物理页面组成。这些页面种包含了已分配的缓存对象,也包含了空闲对象。
主要优点:
①没有因碎片而引起的内存浪费。因为每个内核数据结构都有相应的cache,而每个cache都由若干slab组成,每个slab又分为若干个与对象大小相同的部分。
②内存请求可以快速满足。