获取标签内全部文本的几种方式
最近在用scrapy框架爬取贴吧内容练习时,总是出现一个问题,什么问题呢,我们都知道一个帖子的层数和内容条数是相同的,但是我在爬取的时候总是层主名字和内容对不上号,于是我输出了一下层主名字和内容的长度,结果出现这样的结果
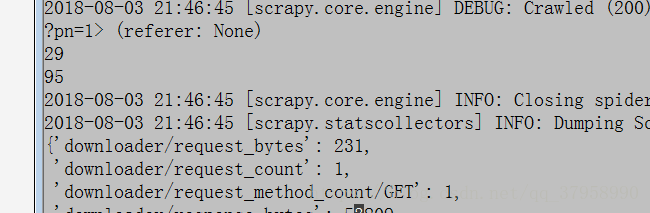
可以看到 ,在一页中,层主有29个,但他们所发的内容却有95个!这明显是不对的,经过我的检查发现有许多层的内容是这样的
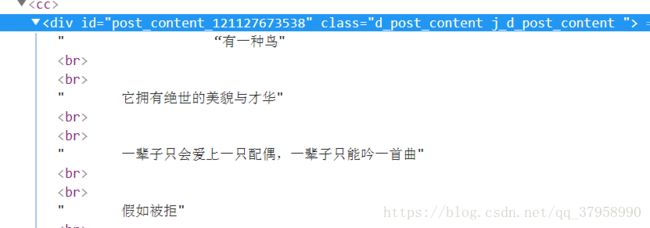
我的代码中取得这一段文字是这样写的
namelist=response.xpath('//li[@class="d_name"]/a/text()').extract()
content=response.xpath('//div[@class="d_post_content j_d_post_content"]/text()').extract()问题就出现了,我代码中爬取内容时使用的是text(),而这个方法只能得到本标签下也就是div下的文本内容,而其实有很多内容时被
包着的,text()就得不到了,那怎么办呢,我这里有四种方法可以解决这个问题。
1.获取最外层标签,遍历内部所有的子标签,获取标签文本
先获得一层内所有内容,挨个循环出来,然后用字符串拼接起来。注意 我这里写的代码与上面的不一样,上面写的是直接爬取全部的数据,我这里是一层一层的爬取
2.正则去掉所有标签<.*?> re.compile.sub()
3./text()获取标签的文本 //text()获取标签以及子标签的文本
这个只需要换一下就行了,但是还需要手动拼接一下
4使用xpath('string(.)')这种方式来获取所有文本并且拼接

string()是一种方法,可以得到标签下所有的文本内容并拼接在一起,一般推荐使用这个