2019 Interspeech CycleGAN-based Emotion Style Transfer as Data Augmentation for SER
利用:Cycle consistent adversarial networks (CycleGAN)
目的:addressing the data scarcity problem in speech emotion recognition
(1)在 CycleGAN的基础上从大型的unlabeled 语音数据库 迁移特征 到合成的特征表示。
(2)扩展了 CycleGAN:用分类loss which improves the discriminability of the generated data
实验
生成的数据有两种使用方法:
(1)直接augmentation到训练数据中
(2)作为独立的training set
结果在within-corpus and cross-corpus均表现很好
Introduction就介绍了全文的目的。生成目标类别的数据,使得总体数据的比例是可控制的。同时在总量上也扩充,得到一个a large and balanced synthetic dataset.
第二,三段介绍了GAN在speech方面的应用。
贡献
(1)合成的是feature vectors
(2)基于cycle GAN既保证了(1)的相似性又保证了可区分性。
(3)基于真实数据和合成数据的NN分类器表现优于传统的只用real data的。
method
有标签的数据库X
N类情感
a source domain S :外部的无标签dataset
Ti : samples of emotion i in the labeled dataset X.
两个mapping functions: G i G_i Gi translate from source到target, F i F_i Fi从T到S。
对抗判别器adversarial discriminator D i T D_i^T DiT:鼓励 Gi(S到T)to generate synthetic targets indistinguishable from real samples
同时, F i F_i Fi和 D i S D_i^S DiS:
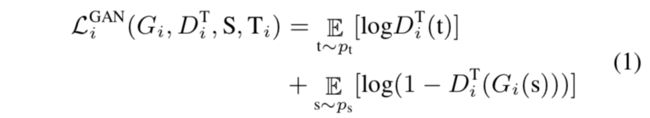
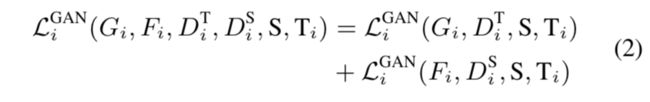
cycle consistency loss
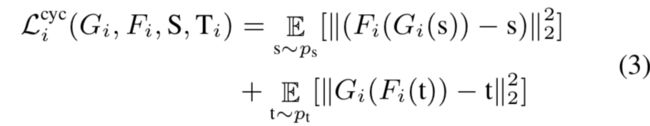
最后的loss由三部分组成
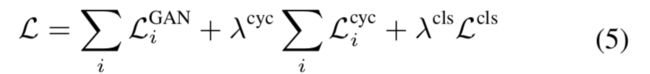
(补充实验部分2.11晚)
IEMOCAP: 四类5531个(1,103 angry, 1,636 happy, 1,708 neutral, 1,084 sad)样本作为 training set
MSP-IMPROV:作为testing set,一共7798个(792 angry, 2,644 happy, 3,477 neutral, 885 sad),分布是极其不平衡的,所以用作test
TEDLIUM.无标记的 source data 用来生成 synthetic feature vectors.
特征:1582维的‘emobase2010’
因为四类情感,所以 model包括 四个 generators, 四个 discriminators 和一个 classifier.
因为generators很难学习高纬的特征表示,所以预先训练了 G i G_i Gi, F i F_i Fi在对应的source(全部的TEDLIUM) and target(IEMOCAP特定的情感) data for 10k epochs 。
为了平衡generators和 discriminators ,训练两次g再训练一次d。 除此, 还用了one-sided label smoothing (第一次见)
4.2. Emotiontransfer
主要目的:generate feature vectors that preserve the distribu- tion of the real target samples
两种设置:有classification loss和没有classification loss
从结果来看是实现了这个目的的。
4.3. Within-corpus evaluation
三个前馈NN,分别训练在:
(i) only real samples taken from IEMOCAP,
(ii) only synthetic features
(iii) the combination of both.
(i) 和(ii)都是两层hidden layers ,但是(ii)200 neurons是(i)的两倍,batch-size256是(i)的四倍,
而(iii)1000 neurons,学习率是前两个的0.5(参数设置值得借鉴)
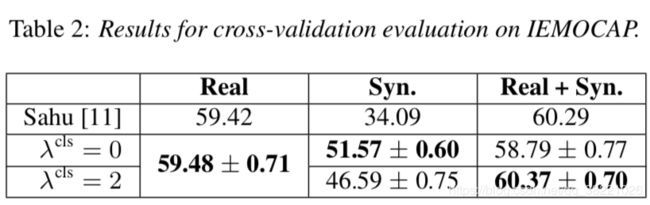
为了说明差异,画了confusion matrices 。
4.4. Cross-corpusevaluation
和4.3一样设置的三组实验,MSP-IMPROV as test set. W,30% of the samples as development set for hyper-parameter tun- ing and the remaining 70% as test set。两部分的情感比例是一致的。(ii)(iii)的超参数和4.3不一样。high dropout rate appears 因为 overfitting problem with synthetic samples.
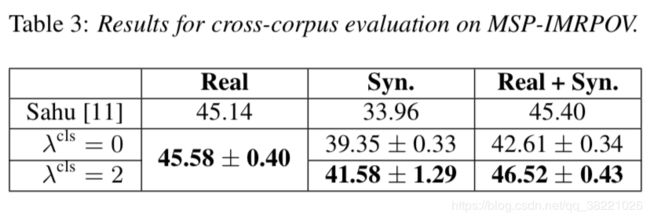
额外的synthetically generated training samples can improve classification performance for data which was not involved in CycleGAN training.
和4.3不一样的是, classification loss 对cross-domain scenarios.是有帮助的。