前言:
电影票房预测项目中,我们需要根据电影的预算,类型,语言,发行时间,电影时长,受欢迎程度,演员信息,工作人员信息等信息来预测电影票房。
与之前的Kaggle共享单车租赁预测的不同之处在于,共享单车项目中,我们的数据都是数值型变量,但是在这个票房预测项目中,我们的数据绝大多数都是些json,str格式,所以我们需要花费大量的时间来处理数据,所以这篇文章我们只涉及数据处理与建模调参,中间的数据分析与可视化可以戳这里:Kaggle电影票房预测(数据分析与可视化)
本次项目说明:
- 编程语言:Python
- 编译工具:jupyter notebook
- 涉及到的库:pandas,numpy,matplotlib,sklearn,seaborn,datetime,dateutil
- Kaggle链接:https://www.kaggle.com/c/tmdb-box-office-prediction
1.0 数据概览
#导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import json
from collections import Counter
from wordcloud import WordCloud
from dateutil.parser import parse
import warnings
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV, cross_val_score
#设置jupyter可以多行输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all' #默认为'last'
#jupyter绘图魔术方法
%matplotlib notebook
#忽略警告
warnings.filterwarnings("ignore")
#读取数据
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
#查看对象尺度
train_data.shape
test_data.shape
output:
(3000, 23)
(4398, 22)
发现测试集的数据竟然比训练集还要多...只能希望给这些数据够模型训练了,测试集少的一列是revenue列,也就是票房列,需要我们建模预测。
#训练集总览
train_data.info()
output:
RangeIndex: 3000 entries, 0 to 2999
Data columns (total 23 columns):
id 3000 non-null int64
belongs_to_collection 604 non-null object
budget 3000 non-null int64
genres 2993 non-null object
homepage 946 non-null object
imdb_id 3000 non-null object
original_language 3000 non-null object
original_title 3000 non-null object
overview 2992 non-null object
popularity 3000 non-null float64
poster_path 2999 non-null object
production_companies 2844 non-null object
production_countries 2945 non-null object
release_date 3000 non-null object
runtime 2998 non-null float64
spoken_languages 2980 non-null object
status 3000 non-null object
tagline 2403 non-null object
title 3000 non-null object
Keywords 2724 non-null object
cast 2987 non-null object
crew 2984 non-null object
revenue 3000 non-null int64
dtypes: float64(2), int64(3), object(18)
memory usage: 539.1+ KB
字段解释:
- id:电影的唯一id
- belongs_to_collection:这个电影系列的系列名称(不是系列电影就是空值)/TMDB上的ID/海报和背景图链接,json格式
- budget:电影的预算,0代表未知
- genres:电影的类型以及类型对应的TMDB上的ID,使用json格式封装信息
- homepage:电影官方主页
- imdb_id:电影在TMDB的ID
- orginal_language:电影的原始语言
- orginal_title:电影的原始名称
- overview:简短的描述
- popularity:电影的流行程度,使用浮点数代表
- poster_path:电影海报链接
- production_copanies:电影的出品公司,使用json格式
- production_countries: 电影出品公司所在国家,使用json格式
- release_date:发行时间
- runtime:电影时长
- spoken_languages:电影语言,json格式
- status:电影的状态,是否已经发布
- tagline:电影的宣传标语
- title:电影英文名
- keywords:电影的关键词以及相应关键词在TMDB上的ID
- cast:演员的姓名/id/性别,使用json格式
- crew:职员(导演/编辑/摄影...)的姓名/id/性别,使用json格式
- revenue:电影总收入
#训练集和测试集的空值一览
train_data.isna().sum()
test_data.isna().sum()
output:
id 0
belongs_to_collection 2396
budget 0
genres 7
homepage 2054
imdb_id 0
original_language 0
original_title 0
overview 8
popularity 0
poster_path 1
production_companies 156
production_countries 55
release_date 0
runtime 2
spoken_languages 20
status 0
tagline 597
title 0
Keywords 276
cast 13
crew 16
revenue 0
dtype: int64
id 0
belongs_to_collection 3521
budget 0
genres 16
homepage 2978
imdb_id 0
original_language 0
original_title 0
overview 14
popularity 0
poster_path 1
production_companies 258
production_countries 102
release_date 1
runtime 4
spoken_languages 42
status 2
tagline 863
title 3
Keywords 393
cast 13
crew 22
dtype: int64
可以看到训练集和测试集中,belongs_to_collection/homepage/tagline这些列缺失值较多,不过也正常,很多电影都只有一部,没有官网和宣传标语也是非常正常的,对于缺失值我们后面载处理就行了。
2.0 数据处理
train_data[:3]
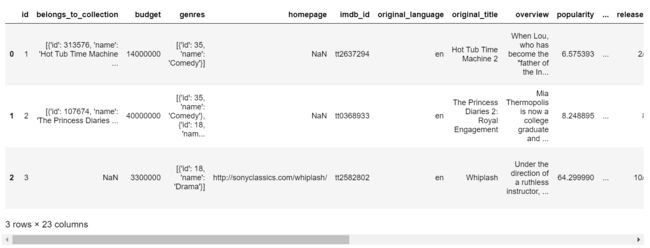
由于数据有很多列,超出了显示边界,所以就只展示了一部分数据。可以看到数据集中很多都是json格式的数据,所以,处理数据的第一步,我们要将json格式的数据处理掉!
使用eval()函数,就可以将字符串类型的list转换为list类型了,这样后面处理各列就方便多了。
dict_columns = ['belongs_to_collection', 'genres', 'production_companies',
'production_countries', 'spoken_languages', 'Keywords', 'cast', 'crew']
def text_to_dict(df):
for column in dict_columns:
df[column] = df[column].apply(lambda x: {} if pd.isna(x) else eval(x) )
return df
train_data = text_to_dict(train_data)
test_data = text_to_dict(test_data)
train_data[:3]
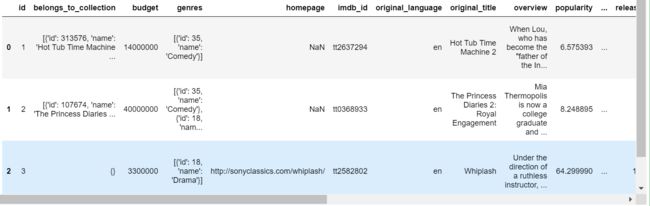
2.1 belongs_to_collection列处理
一般来说一个电影就是属于一个系列而不会是多个系列,为了防止意外情况,我们来验证下belongs_to_collection所有的list是否都是只有一个dict( list元素中一个dict就是一个系列)。
train_data['belongs_to_collection'].map(lambda x:len(x) if x!='{}' else 0).value_counts()
output:
0 2396
1 604
Name: belongs_to_collection, dtype: int64
OK,那么现在我们知道了,belongs_to_collection列中有2396部电影都不属于电影系列,剩下的604部电影都是只属于一个电影系列的。其实电影属于哪一个系列对票房的影响不大,而这个电影是否是属于一个电影系列的,这是对票房有影响的,所以这里我们新增1列就是电视是否属于系列电影。
#训练集处理
train_data['has_collection'] = train_data['belongs_to_collection'].map(lambda x:1 if x!={} else 0)
#测试集处理
test_data['has_collection'] = test_data['belongs_to_collection'].map(lambda x:1 if x!={} else 0)
2.2 genres列处理
一个电影可能属于多种类型(喜剧/动作/悬疑...这种),所以首先我们来看下,电影类型数量的分布。
(train_data['genres'].map(lambda x:len(x) if x!={} else 0).value_counts().sort_index()).plot(kind='bar')
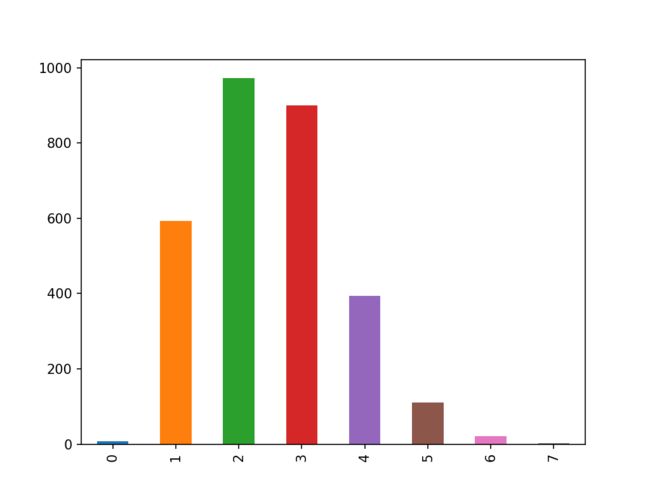
大部分电影还是只属于2-3种类型,不属于任何电影类型或者属于7种电影类型都是极少数。
对于genres列,如果一个电影它属于多种类型,比如既是动作片也是悬疑片,那么他可能会受到更多人欢迎,票房也就好,所以这里我们要增加一列,就是这个电影是属于几种类型的。
#训练集处理
train_data['genres_num'] = train_data['genres'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['genres_num'] = test_data['genres'].map(lambda x:len(x) if x!={} else 0)
不同类型的电影可能受欢迎的程度也会不同,比如喜剧片比动作片要更受欢迎,所以类型的不同可能也会导致票房的不同,这里我就是要将所有的电影类型类型进行分类。
首先需要新增一列,将所有的电影类型从dict中分离出来。
#训练集处理
train_data['genres_all'] = train_data['genres'].map(lambda x:','.join([i['name'] for i in x]))
#测试集处理
test_data['genres_all'] = test_data['genres'].map(lambda x:','.join([i['name'] for i in x]))
train_data['genres_all'][:5]
output:
0 Comedy
1 Comedy,Drama,Family,Romance
2 Drama
3 Thriller,Drama
4 Action,Thriller
Name: genres_all, dtype: object
然后将所有的电影类型找出来,顺便可以看下哪些电影类型最多,哪些电影类型最少。
list_genres = list(train_data['genres'].map(lambda x:[i['name'] for i in x]))
list_genres_count = []
for i in list_genres:
for j in i:
list_genres_count.append(j)
#%matplotlib notebook
fig,ax=plt.subplots(figsize=(12,6))
w = WordCloud( \
width = 1000, height = 700,\
background_color = "white",
collocations=False
).generate(','.join(list_genres_count))
plt.imshow(w)
plt.xticks([])
plt.yticks([])
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)

可以看到剧情和喜剧类的电影最多,惊悚和动作电影也不少,这些电影类型其实从侧面也反映了观众的喜好。
然后我们就可以给电影进行分类操作了,找出所有的电影类型并创建相应的列,如果genres_all列中包括这个类型,那就是1,否则就是0。
genres_top = Counter(list_genres_count).most_common()
list_genres_count = Counter(list_genres_count)
list_genres_count = list(list_genres_count)
#训练集处理
for i in list(list_genres_count):
train_data['genres_'+i] = train_data['genres_all'].map(lambda x:1 if i in x else 0)
#测试集处理
for i in list(list_genres_count):
test_data['genres_'+i] = test_data['genres_all'].map(lambda x:1 if i in x else 0)
2.3 homepage列处理
有官方主页说明宣传力度大,那么关注也会越多,票房越好,所以新增一列,判断电影是否有主页。
训练集处理
train_data['has_homepage'] = train_data['homepage'].map(lambda x:0 if pd.isna(x) else 1)
#测试集处理
test_data['has_homepage'] = test_data['homepage'].map(lambda x:0 if pd.isna(x) else 1)
2.4 original_language
先看下有多少种原始语言,以及他们的分布如何。
train_data['original_language'][:5]
0 en
1 en
2 en
3 hi
4 ko
Name: original_language, dtype: object
len(train_data['original_language'].value_counts())
output:
36
sns.countplot(train_data['original_language'])
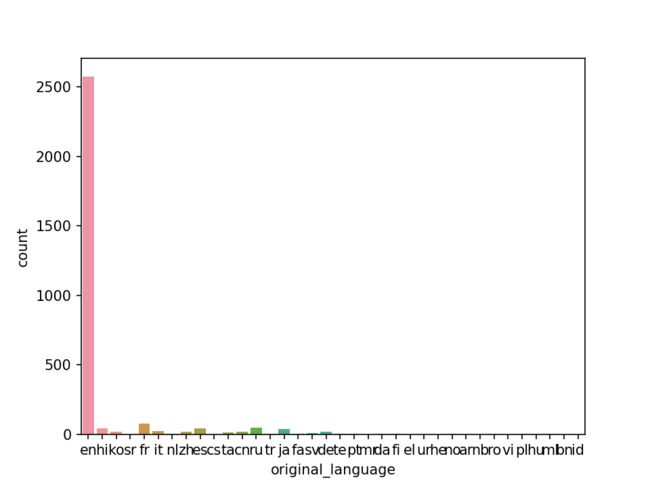
可以看到,一共36种语言,但是绝大多电影都是英语,所以这里只取频次前15的语言新建列进行分类。
original_language_list = [i[0] for i in Counter(train_data['original_language']).most_common(15)]
#训练集处理
for i in original_language_list:
train_data['orginal_language_' + i] = train_data['original_language'].map(lambda x:1 if x==i else 0 )
#测试集处理
for i in original_language_list:
test_data['orginal_language_' + i] = test_data['original_language'].map(lambda x:1 if x==i else 0 )
2.5 production_companies列处理
首先看下,电影的出品公司数量分布,出品公司越多,说明电影投入啊,宣发力度越大,所以公司数量对票房也是很重要的一点。
#训练集处理
train_data['pr_companies_num'] = train_data['production_companies'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['pr_companies_num'] = test_data['production_companies'].map(lambda x:len(x) if x!={} else 0)
sns.countplot(train_data['pr_companies_num'])
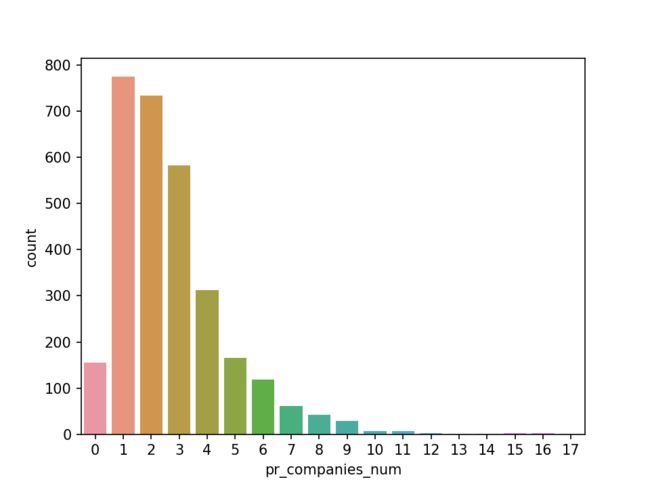
可以看到,绝大多是电影是由1-3家公司出品的。
然后将电影公司从dict中抽离出来,形成一个单独的列。
#测试集处理
train_data['companies_all'] = train_data['production_companies'].map(lambda x:','.join([i['name'] for i in x]))
#测试集处理
test_data['companies_all'] = test_data['production_companies'].map(lambda x:','.join([i['name'] for i in x]))
list_companies = list(train_data['production_companies'].map(lambda x:[i['name'] for i in x]))
list_companies_count = []
for i in list_companies:
for j in i:
list_companies_count.append(j)
companies_top = Counter(list_companies_count).most_common()
len(Counter(list_companies_count))
output:
3695
电影公司由大公司,也有小公司,所以不同公司出品对票房的影像也是不同,但是由于电影公司一共有3695家,太多了,所以我们只取频次前30家公司新建列。
production_companies_count_list = [i[0] for i in Counter(list_companies_count).most_common(30)]
#训练集处理
for i in production_companies_count_list:
train_data['companies_' + i] = train_data['companies_all'].map(lambda x:1 if i in x else 0 )
#测试集处理
for i in production_companies_count_list:
test_data['companies_' + i] = test_data['companies_all'].map(lambda x:1 if i in x else 0 )
2.6 production_countries列处理
出品国家这列其实和出品公司列的处理基本一致,先找出出品国家的数量,然后根据频次进行分类处理。
train_data['production_countries'][:3]
output:
0 [{'iso_3166_1': 'US', 'name': 'United States o...
1 [{'iso_3166_1': 'US', 'name': 'United States o...
2 [{'iso_3166_1': 'US', 'name': 'United States o...
Name: production_countries, dtype: object
先新增一列,电影的出品方国家数量有多少,出品国家越多,意味着在更多的国家上线,票房也就越好。
#训练集处理
train_data['pr_countries_num'] = train_data['production_countries'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['pr_countries_num'] = test_data['production_countries'].map(lambda x:len(x) if x!={} else 0)
然后我们需要将出品方国家从json格式种分离出来,找出所有的出品方国家有哪些,再进行分类。
#测试集处理,新增一列,将出品方国家从json中分离出来
train_data['countries_all'] = train_data['production_countries'].map(lambda x:','.join([i['iso_3166_1'] for i in x]))
#测试集处理,新增一列,将出品方国家从json中分离出来
test_data['countries_all'] = test_data['production_countries'].map(lambda x:','.join([i['iso_3166_1'] for i in x]))
list_countries = list(train_data['production_countries'].map(lambda x:[i['iso_3166_1'] for i in x]))
list_countries_count = []
for i in list_countries:
for j in i:
list_countries_count.append(j)
fig,ax=plt.subplots(figsize=(12,6))
w = WordCloud( \
width = 1000, height = 700,\
background_color = "white",
collocations=False
).generate(','.join(list_countries_count))
plt.imshow(w)
plt.xticks([])
plt.yticks([])
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)

pd.DataFrame(Counter(list_countries_count).most_common(30)).set_index([0]).iloc[:,0].plot(kind='bar')
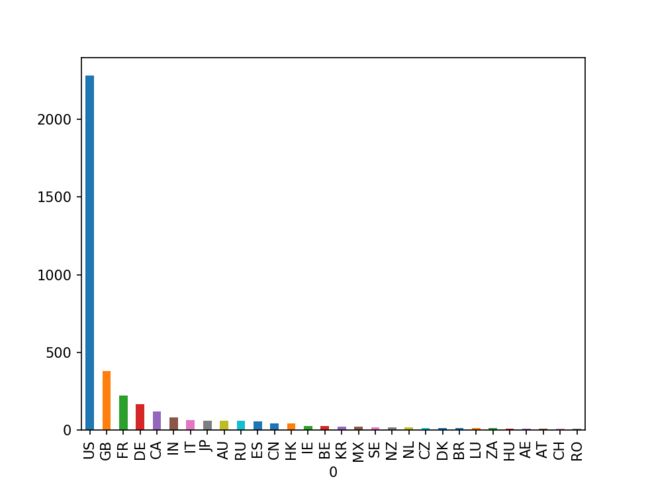
len(Counter(list_countries_count))
output:
74
countries_top = Counter(list_countries_count).most_common()
可以看到,出品方国家虽然有74个,但是绝大多是电影是由美国出品的,远超其他国家。
所以这里我们只取频次前25的国家新建列。
production_countries_count_list = [i[0] for i in Counter(list_countries_count).most_common(25)]
#训练集处理
for i in production_countries_count_list:
train_data['pr_countries_' + i] = train_data['countries_all'].map(lambda x:1 if i in x else 0 )
#测试集处理
for i in production_countries_count_list:
test_data['pr_countries_' + i] = test_data['countries_all'].map(lambda x:1 if i in x else 0 )
2.7 release_date列处理
对于发行时间这列,我们需要将时间拆分为年月日,季度以及星期几,一共新增5列。
def func_one(x):
if x<=3:
return 1
elif x<=6:
return 2
elif x<=9:
return 3
else:
return 4
train_data['release_year'] = train_data['release_date'].map(lambda x:parse(x).year)
train_data['release_month'] = train_data['release_date'].map(lambda x:parse(x).month)
train_data['release_day'] = train_data['release_date'].map(lambda x:parse(x).day)
train_data['release_weekday'] = train_data['release_date'].map(lambda x:parse(x).isoweekday())
train_data['release_quarter'] = train_data['release_month'].map(func_one)
test_data.loc[test_data['release_date'].isnull(),'release_date']='1/1/2000'
test_data['release_year'] = test_data['release_date'].map(lambda x:parse(x).year)
test_data['release_month'] = test_data['release_date'].map(lambda x:parse(x).month)
test_data['release_day'] = test_data['release_date'].map(lambda x:parse(x).day)
test_data['release_weekday'] = test_data['release_date'].map(lambda x:parse(x).isoweekday())
test_data['release_quarter'] = test_data['release_month'].map(func_one)
这里要注意下,如果一个时间比如说是8/6/61,这个61他是1961年,而不是2061年,但是有时候parse(x)却会转化错误,导致生成的年份是2061,所以这里我们需要再将大于2019的年份减去100,这才是正确的时间。
def fun_year(x):
if x>2019:
x = x-100
return x
train_data['release_year'] = train_data['release_year'].map(fun_year)
test_data['release_year'] = test_data['release_year'].map(fun_year)
2.8 runtime列处理
runtime列存在一些空值,这里统一使用众数进行填充。
#训练集处理
train_data['runtime'] = train_data['runtime'].fillna(train_data['runtime'].mode()[0])
#测试集处理
test_data['runtime'] = test_data['runtime'].fillna(test_data['runtime'].mode()[0])
2.9 spoken_languages列处理
spoken_languages列的处理和上面的json列处理也是差不太多,我们新增一列语言数量的列,然后找出频次前25的语言新建列进行分类。
train_data['spoken_languages'][:2]
output:
0 [{'iso_639_1': 'en', 'name': 'English'}]
1 [{'iso_639_1': 'en', 'name': 'English'}]
Name: spoken_languages, dtype: object
#训练集处理
train_data['spoken_languages_num'] = train_data['spoken_languages'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['spoken_languages_num'] = test_data['spoken_languages'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
train_data['spoken_languages_all'] = train_data['spoken_languages'].map(lambda x:','.join([i['iso_639_1'] for i in x]))
#测试集处理
test_data['spoken_languages_all'] = test_data['spoken_languages'].map(lambda x:','.join([i['iso_639_1'] for i in x]))
list_spoken_languages = list(train_data['spoken_languages'].map(lambda x:[i['iso_639_1'] for i in x]))
list_spoken_languages_count = []
for i in list_spoken_languages:
for j in i:
list_spoken_languages_count.append(j)
languages_top = Counter(list_spoken_languages_count).most_common()
spoken_languages_count_list = [i[0] for i in Counter(list_spoken_languages_count).most_common(25)]
#训练集处理
for i in spoken_languages_count_list:
train_data['spoken_languages_' + i] = train_data['spoken_languages_all'].map(lambda x:1 if i in x else 0 )
#测试集处理
for i in spoken_languages_count_list:
test_data['spoken_languages_' + i] = test_data['spoken_languages_all'].map(lambda x:1 if i in x else 0 )
3.0 status列处理
train_data['status'].value_counts()
Released 2996
Rumored 4
Name: status, dtype: int64
可以看到绝大多是电影都是已发行状态,所以这列我们将电影的状态分为Released和其他其他两种情况,那么1就是Released,0就是其他。
train_data['has_Released'] = train_data['status'].map(lambda x:1 if x=='Released' else 0)
test_data['has_Released'] = test_data['status'].map(lambda x:1 if x=='Released' else 0)
3.1 tagline列处理
和homepage列一样,我们新增一列,将数据分为有tagline和没有tagline列。
train_data['has_tagline'] = train_data['tagline'].map(lambda x:0 if pd.isna(x) else 1)
test_data['has_tagline'] = test_data['tagline'].map(lambda x:0 if pd.isna(x) else 1)
3.2 Keywords列处理
关键词越多,说明电影内容越丰富,同时也会吸引更多人注意,潜在票房也会越高,所以这里首先新增1列,判断电影关键词数量。
#训练集处理
train_data['Keywords_num'] = train_data['Keywords'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['Keywords_num'] = test_data['Keywords'].map(lambda x:len(x) if x!={} else 0)
然后我们找出所有的关键词,根据频次进行排序,取频次前N的关键词进行分类处理。
#训练集处理
train_data['Keywords_all'] = train_data['Keywords'].map(lambda x:','.join([i['name'] for i in x]))
#测试集处理
test_data['Keywords_all'] = test_data['Keywords'].map(lambda x:','.join([i['name'] for i in x]))
list_Keywords = list(train_data['Keywords'].map(lambda x:[i['name'] for i in x]))
list_Keywords_count = []
for i in list_Keywords:
for j in i:
list_Keywords_count.append(j)
keywords_top = Counter( list_Keywords_count).most_common()
fig,ax=plt.subplots(figsize=(12,6))
w = WordCloud( \
width = 1000, height = 700,
background_color = "white",
collocations=True
).generate(','.join(list_Keywords_count))
plt.imshow(w)
plt.xticks([])
plt.yticks([])
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)

可以看到,独立电影,女权,暴力,谋杀,警匪,性,爱情这些是比较常见的关键词。
由于关键词数量较多,这里我们取频次前30的关键词进行分类处理。
list_Keywords_count = [i[0] for i in Counter(list_Keywords_count).most_common(30)]
#训练集处理
for i in list(list_Keywords_count):
train_data['Keywords_'+i] = train_data['Keywords_all'].map(lambda x:1 if i in x else 0)
#测试集处理
for i in list(list_Keywords_count):
test_data['Keywords_'+i] = test_data['Keywords_all'].map(lambda x:1 if i in x else 0)
3.3 cast列处理
演员数量越多,说明电影投入越大,所以一样要新增1列判断电影的演员数量。
#训练集处理
train_data['cast_num'] = train_data['cast'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['cast_num'] = test_data['cast'].map(lambda x:len(x) if x!={} else 0)
将演员的姓名从json格式中分离出来。
#训练集处理
train_data['cast_all'] = train_data['cast'].map(lambda x:','.join([i['name'] for i in x]))
#测试集处理
test_data['cast_all'] = test_data['cast'].map(lambda x:','.join([i['name'] for i in x]))
list_cast = list(train_data['cast'].map(lambda x:[i['name'] for i in x]))
list_cast_count = []
for i in list_cast:
for j in i:
list_cast_count.append(j)
cast_top = Counter( list_cast_count).most_common()
演员也分大牌演员和跑龙套的,不同演员对电影的票房影像不一样,所以这里取频次前30的演员,对进行分类处理,判断电影是否包含这些演员。
list_cast_count = [i[0] for i in Counter(list_cast_count).most_common(30)]
for i in list(list_cast_count):
train_data['cast_'+i] = train_data['cast_all'].map(lambda x:1 if i in x else 0)
for i in list(list_cast_count):
test_data['cast_'+i] = test_data['cast_all'].map(lambda x:1 if i in x else 0)
另外就是演员中性别的数量,比例可能也会对电影票房造成影响,有些就是大部分演员都是男性,比如敢死队这种,有些就是大部分演员都是女性,比如国产宫斗剧,电影的性别的组成不同,潜在观众也会不同,所以可能对最后的票房造成影响。
train_data['gender_0_Cast'] = train_data['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
train_data['gender_1_Cast'] = train_data['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
train_data['gender_2_Cast'] = train_data['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
test_data['gender_0_Cast'] = test_data['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
test_data['gender_1_Cast'] = test_data['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
test_data['gender_2_Cast'] = test_data['cast'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
3.2 crew列处理
crew列的处理和cast列的处理基本一致,但是由于电影的部门数量不多,而且都是一样的(就是导演,编剧,摄影这种电影工作岗位),所以将这些岗位都进行了分类处理,来判断这个电影是否有某个岗位。
#训练集处理
train_data['crew_num'] = train_data['crew'].map(lambda x:len(x) if x!={} else 0)
#测试集处理
test_data['crew_num'] = test_data['crew'].map(lambda x:len(x) if x!={} else 0)
#训练集处理
train_data['crew_all'] = train_data['crew'].map(lambda x:','.join([i['name'] for i in x]))
train_data['crew_department_all'] = train_data['crew'].map(lambda x:','.join([i['department'] for i in x]))
#测试集处理
test_data['crew_all'] = test_data['crew'].map(lambda x:','.join([i['name'] for i in x]))
test_data['crew_department_all'] = test_data['crew'].map(lambda x:','.join([i['department'] for i in x]))
list_crew = list(train_data['crew'].map(lambda x:[i['name'] for i in x]))
list_crew_count = []
for i in list_crew:
for j in i:
list_crew_count.append(j)
crew_top = Counter(list_crew_count).most_common()
list_department = list(train_data['crew'].map(lambda x:[i['department'] for i in x]))
list_department_count = []
for i in list_department:
for j in i:
list_department_count.append(j)
department_top = Counter( list_department_count).most_common()
list_crew_count = [i[0] for i in Counter(list_crew_count).most_common(30)]
list_department_count = [i[0] for i in Counter(list_department_count).most_common()]
for i in list(list_crew_count):
train_data['crew_'+i] = train_data['crew_all'].map(lambda x:1 if i in x else 0)
for i in list(list_crew_count):
test_data['crew_'+i] = test_data['crew_all'].map(lambda x:1 if i in x else 0)
for i in list(list_department_count):
train_data['department_'+i] = train_data['crew_department_all'].map(lambda x:1 if i in x else 0)
for i in list(list_department_count):
test_data['department_'+i] = test_data['crew_department_all'].map(lambda x:1 if i in x else 0)
train_data['gender_0_crew'] = train_data['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
train_data['gender_1_crew'] = train_data['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
train_data['gender_2_crew'] = train_data['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
test_data['gender_0_crew'] = test_data['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 0]))
test_data['gender_1_crew'] = test_data['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 1]))
test_data['gender_2_crew'] = test_data['crew'].apply(lambda x: sum([1 for i in x if i['gender'] == 2]))
3.3 renvenue列处理
renvenue列使我们的因变量列,经常会遇到的一个问题就是如果这列的波动很大,会导致模型过拟合,我们可以先来看下renvenue列的分布。
sns.distplot(train_data['revenue'])
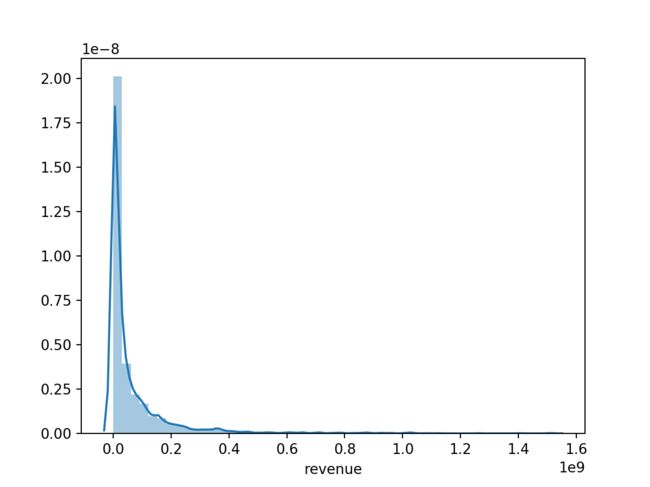
可以看到,数据波动还是蛮大的,所以这里我们将其进行对数转化,再看看下分布情况。
train_data['revenue_log'] = np.log(train_data['revenue'])
sns.distplot(train_data['revenue_log'])
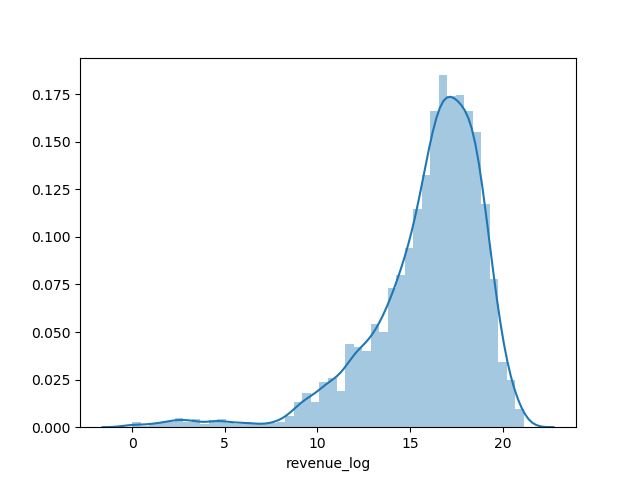
可以看到,数据的波动明显变小了,这对我们的模型是有益的。
4.0 机器学习建模与调参
4.1 建模
这里我分别尝试了RandForest和XGBoost进行类建模,但是发现RandForest调参之后的分数比直接使用默认参数的XGBoost分数还要低,所以这里直接使用 XGBoost进行建模调参。
train_data.shape
test_data.shape
output:
(3000, 271)
(4398, 269)
训练集和测试卷的json数据格式的列都进行了分类处理,还有些像id,homepag,overview...这种对票房影响不大,所以这里直接将这些列找出来,然后删掉。
train_drop_col = ['id','belongs_to_collection','genres','homepage','imdb_id','overview','original_language','original_title',
'poster_path','production_companies','production_countries','release_date','spoken_languages',
'status','tagline','title','Keywords','cast','crew','revenue','revenue_log','genres_all','companies_all','countries_all',
'spoken_languages_all','Keywords_all','cast_all','crew_all','crew_department_all']
test_drop_col = ['id','belongs_to_collection','genres','homepage','imdb_id','overview','original_language','original_title',
'poster_path','production_companies','production_countries','release_date','spoken_languages',
'status','tagline','title','Keywords','cast','crew','genres_all','companies_all','countries_all','spoken_languages_all',
'Keywords_all','cast_all','crew_all','crew_department_all']
设定模型的训练集和测试集,
X_train = train_data.drop(train_drop_col,axis=1)
y_train = train_data.loc[:,'revenue_log']
X_test = test_data.drop(test_drop_col,axis=1)
使用XGBoost进行建模,并拟合预测。
xgbrfr = XGBRegressor()
xgbrfr.fit(X_train,y_train)
y_pred = xgbrfr.predict(X_test)
submission=pd.DataFrame({'id':test_data['id'] , 'revenue':[max(0,x) for x in np.exp(y_pred)]})
submission.to_csv('moviebox_predictions_2.0.csv',index=False)
svc_rfr = cross_val_score(estimator=xgbrfr,X=X_train,y=y_train,cv=4)
svc_rfr.mean()
output:
0.5162551932810016
提交到Kaggle上得分:

4.1 调参
这里解释下调参为什么没有从n_estimators开始,因为我的电影性能问题,每次从n_estimators开始调参就卡死,所以调完其他参数后最后才敢调n_estimators参数。一般的话,都是从n_estimators开始调参。
第一轮调参:
params_1 ={'min_child_weight':[1,2,3,4,5,6]}
gs = GridSearchCV(xgbrfr, params_1, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
output:
0.5251436587021792
{'min_child_weight': 5}
确定min_child_weight=5
第二轮调参
xgbrfr = XGBRegressor(min_child_weight=5)
params_2 ={'max_depth':[3,4,5,6,7,8,9,10]}
gs = GridSearchCV(xgbrfr, params_2, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
output:
0.5314080427515098
{'max_depth': 6}
确定max_depth=6
第三轮调参
xgbrfr = XGBRegressor(min_child_weight=5,max_depth=6)
params_3 ={'gamma': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]}
gs = GridSearchCV(xgbrfr, params_3, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
output:
0.530309470934862
{'gamma': 0.1}
确定gamma=0.1
第四轮调参
xgbrfr = XGBRegressor(min_child_weight=5,max_depth=6,gramma=0.1)
params_4 ={'subsample': [0.6, 0.7, 0.8, 0.9], 'colsample_bytree': [0.6, 0.7, 0.8, 0.9]}
gs = GridSearchCV(xgbrfr, params_4, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
0.5429990312580631
{'colsample_bytree': 0.7, 'subsample': 0.9}
确定colsample_bytree=0.7,subsample=0.9
第五轮调参
xgbrfr = XGBRegressor(min_child_weight=5,max_depth=6,gramma=0.1,subsample=0.9,colsample_bytree=0.7)
params_5 ={'reg_alpha': [0.05, 0.1, 1, 2, 3], 'reg_lambda': [0.05, 0.1, 1, 2, 3]}
gs = GridSearchCV(xgbrfr, params_5, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
0.546215111884258
{'reg_alpha': 3, 'reg_lambda': 0.05}
确定reg_alpha=3,reg_lambda=0.05
第六轮调参
xgbrfr = XGBRegressor(min_child_weight=5,max_depth=6,gramma=0.1,subsample=0.9,colsample_bytree=0.7,reg_alpha=3,reg_lambda=0.05)
params_6 ={'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2]}
gs = GridSearchCV(xgbrfr, params_6, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
0.546215111884258
{'learning_rate': 0.1}
确定learning_rate=0.1
第七轮调参
xgbrfr = XGBRegressor(min_child_weight=5,max_depth=6,gramma=0.1,subsample=0.9,colsample_bytree=0.7,reg_alpha=3,reg_lambda=0.05,learning_rate=0.1)
params_7 ={'n_estimators': [100,200,300,400, 500, 600, 700, 800,900,1000]}
gs = GridSearchCV(xgbrfr, params_7, cv=4)
gs.fit(X_train,y_train)
#查验优化后的超参数配置
print(gs.best_score_)
print(gs.best_params_)
0.546215111884258
{'n_estimators': 100}
确定n_estimators=100
进过N轮的调参,我们终于确定了最佳的超参数,现在我们就可以根据这些最佳超参数,重新建模并进行预测。
xgbrfr = XGBRegressor(min_child_weight=5,max_depth=6,gramma=0.1,subsample=0.9,colsample_bytree=0.7,reg_alpha=3,reg_lambda=0.05,learning_rate=0.1)
xgbrfr.fit(X_train,y_train)
y_pred = xgbrfr.predict(X_test)
submission=pd.DataFrame({'id':test_data['id'] , 'revenue':[max(0,x) for x in np.exp(y_pred)]})
submission.to_csv('xgb_moviebox_predictions_2.0.csv',index=False)

可以看到,分数还是有一定的提升的,后续我们还可以在特征工程,特征选择,特征融合,模型融合等方面做出进一步改进,多尝试下,冲击前200指日可待!