0-1背包问题的4种解决方法&&算法策略
蛮力法
递归与分治策略
动态规划
贪心算法
回溯法
分支限界法
前言
0-1背包是一个经典的问题,而它能用不同的算法思想去解决。恰巧最近在看算法,学习算法就是学习解决问题的思路。现在将0-1背包问题与解决方法整理出来,这样不仅能区分不同的算法思想,还能加深对0-1背包问题的理解。虽然有的算法思想并不能解决这一问题,但是为了对算法策略有一个较为整体的了解,所以在这里做一下简单的介绍。
蛮力法
蛮力法(brute force method,也称为穷举法或枚举法)是一种简单直接地解决问题的方法,常常直接基于问题的描述,所以,蛮力法也是最容易应用的方法。但是,用蛮力法设计的算法时间特性往往也是最低的,典型的指数时间算法一般都是通过蛮力搜索而得到的。
蛮力法所依赖的最基本技术是扫描技术,依次处理元素是蛮力法的关键,依次处理每个元素的方法是遍历。虽然设计很高效的算法很少来自于蛮力法,基于以下原因,蛮力法也是一种重要的算法设计技术:
(1)理论上,蛮力法可以解决可计算领域的各种问题。对于一些非常基本的问题,例如求一个序列的最大元素,计算n个数的和等,蛮力法是一种非常常用的算法设计技术。
(2)蛮力法经常用来解决一些较小规模的问题。如果需要解决的问题规模不大,用蛮力法设计的算法其速度是可以接受的,此时,设计一个更高效算法的代价是不值得的。
(3)对于一些重要的问题(例如排序、查找、字符串匹配),蛮力法可以产生一些合理的算法,他们具备一些实用价值,而且不受问题规模的限制。
(4)蛮力法可以作为某类时间性能的底限,来衡量同样问题的更高效算法。
蛮力法解0-1背包问题的基本思想:
对于有 n 种可选物品的 0/1 背包问题,其解空间由长度为 n 的 0-1 向量组成,可用子集数表示。在搜索解空间树时,深度优先遍历,搜索每一个结点,无论是否可能产生最优解,都遍历至叶子结点,记录每次得到的装入总价值,然后记录遍历过的最大价值。
#include
#include
using namespace std;
#define N 100
struct goods
{
int wight;//物品重量
int value;//物品价值
};
int n,bestValue,cv,cw,C;//物品数量,价值最大,当前价值,当前重量,背包容量
int X[N],cx[N];//最终存储状态,当前存储状态
struct goods goods[N];
int Force(int i){
if(i>n-1)
{
if(bestValue < cv && cw <= C)
{
for(int k=0;k force(0) 开始选择第一个物品,不管什么情况都从选择开始(开始递归,每个物品都有选或不选的可能,最后通过最大价值来判断哪些物品选择并记录到数组中),然后进 force(1),进入 force(1),一直到 force(n+1),i>n,return 结果,跳出 force(n+1),在 force(n) 处从跳出的地方继续向下走,就是进入减减减的环节了,然后继续向下,还是一样,加到 n+1 时就会跳出来当前的 force,调到前一个 force,继续向下,循环进行。
蛮力法求解0/1背包问题的时间复杂度为:最好情况下为 O(2^n), 最坏情况下为 O(n*2^n)。
递归与分治策略
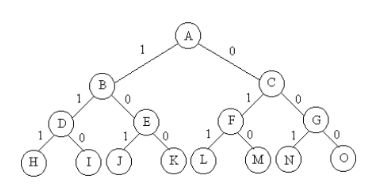
分治法的思想是,将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。如果原问题可以分割成k个子问题,1 直接或间接地调用自身的算法称为递归算法。用函数自身给出定义的函数称为递归函数。在计算机算法设计与分析中,递归技术是十分有用的。使用递归技术往往使函数的定义和算法的描述简捷且易于理解。有些数据结构,如二叉树等,由于其本身固有的递归特征,特别适合用递归的形式来描述。另外,还有一些问题,虽然其本身并没有明显的递归结构,但用递归技术来求解,可使设计出的算法简捷易懂且易于分析。 每个递归函数都必须有非递归定义的初始值,否则,递归函数就无法计算。 分治法的基本思想是将一个规模为n的问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题相同。递归地解这些子问题,然后将各子问题的解合并得到原问题的解。它的一般的算法设计模式如下: 其中,|P|表示问题P的规模,n0为一阈值,表示当问题P的规模不超过n0时,问题已容易解出,不必再继续分解。adhoc(P)是该分治法中的基本子算法,用于直接解小规模的问题P。当P的规模不超过n0时,直接用算法adhoc(P)求解。算法merge(y1,y2,...,yk)是该分治法中的合并子算法,用于将P的子问题P1,P2,...,Pk的解y1,y2,...,yk合并为P的解。 例子:快排,二分查找等。 动态规划算法与分治算法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。 与分治法不同的是,适合于用动态规划法求解的问题,经分解得到的子问题往往不是相互独立的。 该算法的有效性依赖于问题本身所具有的两个重要性质:最优子结构性质和子问题重叠性质。从一般意义上讲,问题所具有的这两个重要性质是该问题可用动态规划算法求解的基本要素。这对于在设计求解具体问题的算法时,是否选择动态规划算法具有指导意义 。 最优子结构 设计动态规划算法的第一步通常是要刻画最优解的结构。当问题的最优解包含了其子问题的最优解时,称该问题具有最优子结构性质。问题的最优子结构性质提供了该问题可用动态规划算法求解的重要线索。利用问题的最优子结构性质,以自底向上的方式递归地从子问题的最优解逐步构造出整个问题的最优解。 重叠子问题 可用动态规划算法求解的问题应具备的另一基本要素是子问题的重叠性质。在用递归算法自顶向下解此问题时,每次产生的子问题并不总是新问题,有些子问题被反复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只解一次,而后将其解保存在一个表格中,当再次需要解此子问题时,只是简单地用常数时间查看一下结果。通常,不同的子问题个数随问题的大小呈多项式增长。因此,用动态规划算法通常只需要多项式时间,从而获得较高的解题效率。 备忘录方法 备忘录方法是动态规划算法的变形。与动态规划算法一样,备忘录方法用表格保存已解决的子问题的答案,在下次需要解此子问题时,只要简单地查看该子问题的解答,而不必重新计算。与动态规划算法不同的是,备忘录方法的递归方式是自顶向下,而动态规划算法则是自底向上递归的。因此备忘录方法的控制结构与直接递归方法的控制结构相同,区别在于备忘录方法为每个解过的子问题建立了备忘录以备需要时查看,避免了相同子问题的重复求解。 例子:0-1背包问题、数组求斐波那契数列。 动态规划解0-1背包问题的基本思想: 对于每个物品我们可以有两个选择,放入背包,或者不放入,有n个物品,故而我们需要做出n个选择,于是我们设f[i][v]表示做出第i次选择后,所选物品放入一个容量为v的背包获得的最大价值。现在我们来找出递推公式,对于第i件物品,有两种选择,放或者不放。 ①如果放入第i件物品,则f[i][v] = f[i-1][v-w[i]]+p[i],表示,前i-1次选择后所选物品放入容量为v-w[i]的背包所获得最大价值为f[i-1][v-w[i]],加上当前所选的第i个物品的价值p[i]即为f[i][v]。 ②如果不放入第i件物品,则有f[i][v] = f[i-1][v],表示当不选第i件物品时,f[i][v]就转化为前i-1次选择后所选物品占容量为v时的最大价值f[i-1][v]。则:f[i][v] = max{f[i-1][v], f[i-1][v-w[i]]+p[i]}。 动态规划法求解0/1背包问题的时间复杂度为:O(min{nc,2^n})。 贪心算法通过一系列的选择来得到问题的解。它所做的每一个选择都是当前状态下局部最好的选择,即贪心选择。对于一个具体的问题,能用贪心算法求解的问题一般具有两个重要的性质:贪心选择性质和最优子结构性质。 所谓的贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。在动态规划算法中,每步所做的选择往往依赖于相关子问题的解。因而只有在解出相关子问题后,才能做出选择。而在贪心算法中,仅在当前状态下做出最好选择,即局部最优选择。然后去解做出这个选择后产生的相应的子问题。贪心算法所做的贪心选择可以依赖于以往所做过的选择,但绝不依赖于将来所做的选择,也不依赖于子问题的解。正是由于这种差别,动态规划算法通常以自底向上的方式解各子问题,而贪心算法则通过以自顶向下的方式进行,以迭代的方式做出相继的贪心选择,每做一次贪心选择就将所求问题简化为规模更小的子问题。 对于一个具体的问题,要确定它是否具有贪心选择性质,必须证明每一步所做的贪心选择最终导致问题的整体最优解。首先考察问题的一个整体最优解,并证明可修改这个最优解,使其以贪心选择开始。做了贪心选择后,原问题简化为规模更小的类似子问题。然后,用数学归纳法证明,通过每一步做贪心选择,最终可得到问题的整体最优解。其中,证明贪心选择后的问题简化为规模更小的类似子问题的关键在于利用该问题的最优子结构性质。 最优子结构性质 当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题可用动态规划算法或贪心算法求解的关键特征。 贪心算法与动态规划算法的差异,可以从0-1背包问题和背包问题中看出。对于0-1背包问题,贪心算法之所以不能得到最优解是因为在这种情况下,它无法保证最终能将背包装满,部分闲置的背包空间使每千克背包空间的价值降低了。事实上,在考虑0-1背包问题时,应比较选择该物品和不选择该物品所导致的最终方案,然后再做出最好的选择。由此可导出许多互相重叠的子问题。这正是该问题可用动态规划算法求解的另一重要特征。 例如:哈夫曼编码,最小生成树,大币找零。 回溯法有”通用的解题法”之称。用它可以系统地搜索一个问题的所有解或任一解。回溯法是一个既带有系统性又带有跳跃性的搜索算法。它在问题的解空间树中,按深度优先策略,从根节点出发搜索解空间树。算法搜索至解空间树的任一结点时,先判断该结点是否包含问题的解。如果肯定不包含,则跳过对以该结点为根的子树的搜索,逐层向其祖先结点回溯。否则,进入该子树,继续按深度优先策略搜索。回溯法求问题的所有解时,要回溯到根,且根结点的所有子树都已被搜索才结束。回溯法求问题的一个解时,只要搜索到问题的一个解就可结束。这种以深度优先方式系统搜索问题解的算法称为回溯法,它适用于解组合数较大的问题。 回溯法的算法框架 (1)问题的解空间 用回溯法解问题时,应明确定义问题的解空间。问题的解空间至少应包含问题的一个(最优)解。例如,对于有n中可选物品的0-1背包问题,其解空间由长度为n的0-1向量组成。该解空间包含对变量的所有可能的0-1赋值。当n=3时,其解空间是{(0,0,0),(0,1,0),(0,0,1),(1,0,0),(0,1,1),(1,0,1),(1,1,0),(1,1,1)}。定义了问题的解空间后,还应将解空间很好地组织起来,使得能用回溯法方便地搜索整个解空间。通常将解空间组织成树或图的形式。 (2)回溯法的基本思想 确定了解空间的组织结构后,回溯法从根结点出发,以深度优先方式搜索整个解空间。这个开始结点称为活结点,同时也称为当前的扩展结点。在当前的扩展结点处,搜索向纵向移至一个新结点。这个新结点就成为新的活结点,并成为当前扩展结点。如果在当前的扩展结点处不能再纵向移动,则这个结点就是死结点。此时,应该往回移动(回溯)至最近的一个活结点处,并使这个活结点成为当前扩展结点。回溯法以这种工作方式递归地在解空间中搜索,直至找到所要求的解或解空间中已无活结点为止。 回溯法搜索解空间树时,通常采用两种策略避免无效搜索,提高回溯法的搜索效率。其一是用约束函数在扩展结点处剪去不满足约束的子树;其二是用限界函数剪去得不到最优解的子树。这两类函数统称为剪枝函数。 (3)递归回溯 回溯法对解空间作深度优先搜索,因此在一般情况下可用递归函数来实现回溯法。 其中,形参t表示递归深度,即当前扩展结点在解空间树中的深度。n用来控制递归深度,当t>n时,算法已搜索到叶结点。此时,有Output(x)记录或输出得到的可行解x。算法Backtrack的for循环中f(n,t)和g(n,t)分别表示在当前扩展结点处未搜索过的子树的起始编号和终止编号。h(i)表示在当前扩展结点处x[t]的第i个可选值。Constraint(t)和Bound(t)表示在当前扩展结点处的x[1:t]的取值满足问题的约束条件,不满足问题的约束条件,可剪去响应的子树。Bound(t)返回值为true时,在当前扩展结点处x[1:t]的取值未使目标函数越界,还需由Backtrack(t+1)对其相应的子树进行进一步搜索。否则,当前扩展结点处x[1:t]的取值使目标函数越界,可剪去相应的子树。执行了算法的for循环后,已搜索遍当前扩展结点的所有未搜索过的子树。Backtrack(t)执行完毕,返回t-1层继续执行,对还没有测试过的x[t-1]的值继续搜索。当t=1时,若已测试完x[1]的所有可选值,外层调用就全部结束。显然,这一搜索过程按深度优先方式进行。调用一次Backtrack(1)即可完成整个回溯搜索过程。 (4)迭代回溯 采用树的非递归深度优先遍历算法,也可将回溯法表示为一个非递归的迭代过程。 上述迭代回溯算法中,用Solution(t)判断在当前扩展结点处是否已得到问题的可行解。它返回的值为true时,在当前扩展结点处x[1:t]是问题的可行解。此时,有Output(x)记录或输出得到的可行解。它返回的值为false时,在当前扩展结点处x[1:t]只是问题的部分解,还需向纵向继续搜索。算法中f(n,t)和g(n,t)分别表示在当前扩展结点处未搜索过的子树的起始编号和终止编号。h(i)表示在当前扩展结点处x[t]的第i个可选值。Constraint(t)和Bound(t)是当前扩展结点处的约束函数和限界函数。Constraint(t)返回的值为true时,在当前扩展结点处x[1:t]的取值满足问题的约束条件,否则不满足问题的约束条件,可剪去相应的子树。Bound(t)返回的值为true时,在当前扩展结点处x[1:t]的取值未使目标函数越界,还需对其相应的子树做进一步搜索。否则,当前扩展结点处x[1:t]的取值已使目标函数越界,可剪去相应的子树。算法的while循环结束后,完成整个回溯搜索过程。 用回溯法解题的一个显著特征是在搜索过程中动态产生问题的解空间。在任何时刻,算法只保存从根结点到当前扩展结点的路径。如果解空间树中从根结点到叶结点的最长路径的长度为h(n),则回溯法所需要的计算空间通常为O(h(n))。而显式地存储整个解空间则需要O(2^h(n))或O(h(n)!)内存空间。 (5)子集树与排列树 上面两棵解空间树是用回溯法解题时常遇到的两类经典的解空间树。当所给的问题是从n个元素的集合S中找出满足某种性质的子集时,相应的解空间树成为子集树。例如,n个物品的0-1背包问题所对应的解空间树就是一棵子集树。这类子集树通常有2^n个叶结点,其结点总个数为2^(n+1)-1.遍历子集树的任何算法均需要Ω(2^n)的计算时间。当所给的问题是确定n个元素满足某种性质的排列时,相应的解空间树成为排列树。排列树通常有n!个叶结点。因此遍历排列树需要Ω(n!)的计算时间。旅行售货员问题的解空间树就是一棵排列树。 用回溯法搜索子集树的一般算法可描述如下: 用回溯法搜索排列树的算法框架可描述如下: 例如:0-1背包问题,n后问题,旅行商问题等。 回溯法解0-1背包问题的基本思想: 为了避免生成那些不可能产生最佳解的问题状态,要不断地利用限界函数(bounding function)来处死那些实际上不可能产生所需解的活结点,以减少问题的计算量。这种具有限界函数的深度优先生成法称为回溯法。对于有n种可选物品的0/1背包问题,其解空间由长度为n的0-1向量组成,可用子集数表示。在搜索解空间树时,只要其左儿子结点是一个可行结点,搜索就进入左子树。当右子树中有可能包含最优解时就进入右子树搜索。 回溯法求解0/1背包问题的时间复杂度为:O(n*2^n)。 分支限界法类似于回溯法,也是在问题的解空间上搜索问题解的算法。一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出解空间中满足约束条件的所有解,而分支限界法的求解目标是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即某种意义的最优解。 由于求解目标不同,导致分支限界法与回溯法对解空间的搜索方式也不相同。回溯法以深度优先的方式搜索解空间,而分支限界法则以广度优先或最小消耗优先的方式搜索解空间。分支限界法的搜索策略是,在扩展结点处,先生成其所有的孩子结点(分支),然后再从当前的活结点表中选择下一个扩展结点。为了有效地选择下一扩展结点,加速搜索的进程,在每一个活结点处,计算一个函数值(限界),并根据函数值,从当前活结点表中选择一个最有利的结点作为扩展结点,使搜索朝着解空间上有最优解的分支推进,以便尽快地找出一个最优解。这种方法称为分支限界法。 分支限界法的基本思想 分支限界法常以广度优先或以最小耗费(最大效益)优先的方式搜索问题的解空间树。问题的解空间树是表示问题解空间的一棵有序树,常见的有子集树和排列树。在搜索问题的解空间树时,分支限界法与回溯法的主要区别在于它们对当前扩展结点所采用的扩展方式不同。在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有孩子结点。在这些孩子结点中,导致不可行解或导致非最优解的孩子结点被舍弃,其余孩子结点被加入活结点表中。此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点扩展过程。这个过程一直持续到找到所需要的解或活结点表为空时为止。 从活结点表中选择下一扩展结点的不同方式导致不同的分支限界法。最常见的有以下两种方式。 (1)队列(FIFO)分支限界法 队列式分支限界法将活结点表组织成一个队列,并按队列的先进先出原则选取下一个结点为当前扩展结点。 (2)优先队列式分支限界法 优先队列式分支限界法将活结点表组织成一个优先队列,并按优先队列中规定的结点优先级选取优先级最高的下一个结点成为当前扩展结点。 优先队列中规定的结点优先级常用一个与该结点相关的的数值p来表示。结点优先级的高低与p的大小相关。最大优先队列规定p值较大的结点优先级较高。在算法实现时通常用最大堆来实现最大优先队列,用最大堆的Deletemax运算抽取堆中下一个结点成为当前扩展结点,体现最大效益优先的原则。类似地,最小优先队列规定p值越小的结点优先级越高。在算法实现时通常用最小堆来实现最小优先队列,用最小堆的Deletemin运算来抽取堆中下一个结点成为当前扩展结点,体现最小费用优先的原则。 用优先队列分支限界法解具体问题时,应该根据具体问题的特点确定选用最大优先队列或最小优先队列来表示解空间的活结点表。例如,考虑n=3时0-1背包问题的一个实例如下:w = [16,15,15],p = [45,25,25],c = 30。队列式分支限界法用一个队列来存储活结点表,而优先队列式分支限界法则将活结点表组成优先队列并用最大堆来实现该优先队列。该优先队列的优先级定义为活结点所获得的价值。 用队列式分支限界法解此问题时,算法从根结点A开始。初始时,活结点队列为空,结点A是当前的扩展结点。结点A的2个孩子结点B和C均为可行结点,故将2个孩子结点按从左到右的顺序加入活动结点队列(类似于树的层次遍历),并且舍弃当前扩展结点A。依照先进先出的原则,下一个扩展结点是活结点队列的队首结点B。扩展结点B有孩子结点D和E。由于D是不可行结点,故被舍弃(因为选了质量为16的这件物品,而C=30,所以不能再选质量为15的物品了)。E是可行结点,被加入活结点队列。接下来,C成为当前扩展结点,它的2个孩子结点F和G均为可行结点,因此被加入到活结点队列中。扩展下一个结点E得到结点J和K。J是不可行结点,因此被舍弃。K是可行的叶结点,表示所求问题的一个可行解,其价值为45。 当活结点队列的队首结点F成为下一个扩展结点。它的2个孩子结点L和M均为叶结点。L表示获得价值为50的可行解;M表示获得价值为25的可行解。G是最后一个扩展结点,其孩子结点N和O均为可行叶结点。最后,活结点队列已空,算法终止。算法搜索得到的最优值是50。从这个例子可以看出,队列式分支限界法搜索解空间树的方式与解空间树的广度优先遍历算法极为相似。唯一的不同之处是队列式分支限界法不搜索以不可行结点为根的子树。 优先队列式分支限界法从根结点A开始搜索解空间树。用一个极大堆表示活结点表的优先队列。初始时堆为空,扩展结点A得到它的2个孩子结点B和C。这两个结点均为可行结点,因此被加入到堆中,结点A被舍弃。结点B获得的当前价值为45,而结点C的当前价值为0。由于结点B的价值大于结点C的价值,所以结点B是堆中最大元素,从而成为下一个扩展结点。扩展结点B的孩子结点D和E。D不是可行结点,因而被舍弃。E是可行结点被加入到堆中。E的价值为45,成为当前堆中最大元素,从而成为下一个扩展结点。扩展结点E得到2个叶结点J和K。J是不可行结点,被舍弃。K是可行叶结点,表示所求问题的一个可行解,其价值为45。此时,堆中仅剩下一个活结点C,它成为当前扩展结点。它的2个孩子结点F和G均为可行结点,因此插入到当前堆中。结点F的价值为25,是堆中最大元素,成为下一个扩展结点。结点F的2个孩子结点L和M均为叶结点。叶结点L对应价值为50的可行解。叶结点M对应价值为25的可行解。叶结点L所对应的解成为当前最优解。最后,结点G成为扩展结点,其孩子结点N和O均为叶结点,它们的价值分别为25和0。接下来,存储活结点的堆已空,算法终止。算法搜索得到的最优值为50。对应的最优解是从根结点A到叶结点L的路径(0,1,1)。 例如:0-1背包问题,单源最短路径问题,装载问题等。 分支限界法解0-1背包问题的基本思想: 首先,要对输入数据进行预处理,将各物品依其单位重量价值从大到小进行排列。在下面描述的优先队列分支限界法中,节点的优先级由已装袋的物品价值加上剩下的最大单位重量价值的物品装满剩余容量的价值和。算法首先检查当前扩展结点的左儿子结点的可行性。如果该左儿子结点是可行结点,则将它加入到子集树和活结点优先队列中。当前扩展结点的右儿子结点一定是可行结点,仅当右儿子结点满足上界约束时才将它加入子集树和活结点优先队列。当扩展到叶节点时为问题的最优值。 分支限界法求解0/1背包问题的时间复杂度为:O(2^n)。 参考: https://www.cnblogs.com/xym4869/p/8513801.html例如:int factorial(int n)
{
if(n == 0)
return 1;
else
return n*factorial(n-1);
}divide-and-conquer(P)
{
if(|P| <= n0) adhoc(P);
divide P into smaller subinstances P1,P2,...,Pk;
for(i = 1; i <= k; i++)
yi = divide-and-conquer(Pi);
return merge(y1,y2,...,yk);
}动态规划
动态规划算法适用于解最优化问题。通常可按以下4个步骤设计:
(1)找出最优解的性质,并刻画其结构特征。
(2)递归地定义最优值。
(3)以自底向上的方式计算出最优值。
(4)根据计算最优值时得到的信息,构造最优解。#include
贪心算法
回溯法
用回溯法解题通常包含以下3个步骤:
①针对所给问题,定义问题的解空间;
②确定易于搜索的解空间结构;
③以深度优先方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。void Backtrack(int t)
{
if( t > n) Output(x);
else
for(int i = f(n, t); i <= g(n,t); i++)
{
x[t] = h(i);
if(Constraint(t)&&Bound(t)) Backtrack(t+1);
}
}void InerativeBacktrack(void)
{
int t = 1;
while(t > 0)
{
if(f(n,t) <= g(n,t))
for(int i = f(n,t); i <= g(n,t); i++)
{
x[t] = h(i);
if(Constraint(t) && Bound(t))
{
if(Solution(t)) Output(x);
else t++;
}
}
else t--;
}
}
void Backtrack(int t)
{
if( t > n) Output(x);
else
for(int i =0; i <= 1; i++)
{
x[t] = i;
if(Constraint(t)&&Bound(t)) Backtrack(t+1);
}
}void Backtrack(int t)
{
if( t > n) Output(x);
else
for(int i =t; i <= n; i++)
{
swap(x[t], x[i]);
if(Constraint(t)&&Bound(t)) Backtrack(t+1);
swap(x[t], x[i]);
}
}#include 分支限界法
#include