论文快速降重的一点实用性见解(仅供参考)
本人在写毕业论文查重降重过程中的一点小小的总结,以paperfree为例,现分享给大家,仅供参考!
一、首先摸清楚查重的算法。Paperfree的算法是:
总体相似度 = 相似字数 / 检测字数
被系统自动识别出来的非正文部分(如目录,标题,公式,图表,参考文献等)不参与检测,检测字数一般略小于论文字数。
相似字数 =(句子1字数 * 句子1相似度 + 句子2字数 * 句子2相似度 + ...... + 句子n字数 * 句子n相似度),句子相似度范围0.00~1.00,绿色句子相似度按照0计算。
红色句子为重度相似(80%~100%),建议修改;橙色句子为轻度相似(50%~80%),可酌情修改;绿色句子表示没有检测到相似语句。
简单归纳:
论文重复率=相似字数÷总字数
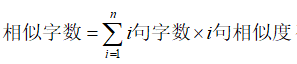 (其中i句相似度>50%为有效,<50%记作0)
(其中i句相似度>50%为有效,<50%记作0)
简单理解:查重时把文章分解为一个个小句,根据某个算法算出单句相似度。把其中相似度大于50%的句子的相似字数加总再除以论文总字数即为重复率。
单句相似度这个概念似乎比较玄学,网站没有明确说明算法,但目前NLP实践中,文本相似度的算法有很多种:Jaccard相似度、余弦相似度、Jaro相似度等,对于人工修改的参考意义都差不多,以Jaccard相似度为例: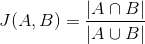
即用两句话中汉字的交集数除以并集数,如“小红在写论文”“小绿在改论文”两句话,交集字符为小/在/论/文(4个);并集字符为小/红/在/写/论/文/绿/改(8个)。因此,Jaccard相似度=4/8*100%=50%。
最重要的一个信息是:相似度>50%的句子才会被标黄,相似度>80%的句子会被标红。相似度<50%的被标绿并且相似度被计为0.
二、那我们的降重目标就很清晰了,一共有两个途径:
①降低每句相似字数,以降低总相似字数;
②把句子的相似度降低到50%以下,那么这句相似字数直接就变为0了。
我们发现这两个途径其实一样。但是②的效果更显著,因为能直接把句子变绿(要坚强)从而大幅降重,所以对于大多数句子,我们的目标显然是用方法②把他变绿。。。
当然还有一些句子非常坚强,比如“根据图2-1我们可以看到,...”这种句子就比较难绿,但是总体而言难绿的句子不多,所以把重复率降到5%以下是不难的。
三、具体措施
我们目前看到的大多数降重思想都局限在方法①,即没有目的地用同义词替换、把字句被字句转换等方法尽力降低相似字数。但是有了科学思想的指导,我们的修改方向就更清晰了。
1.首要争取对象——50出头
像这种相似度50%出头的黄色句子是首要争取对象,因为只要改几个字就能变绿,从50直接变成0,因而在降重工程中最受欢迎(大家都争着绿他,很是可怜)。


改成“这进一步说明了IIT现象更易发生于初始要素禀赋相近的国家间”后,绿化成功。
2.短句合并成长句增加分母
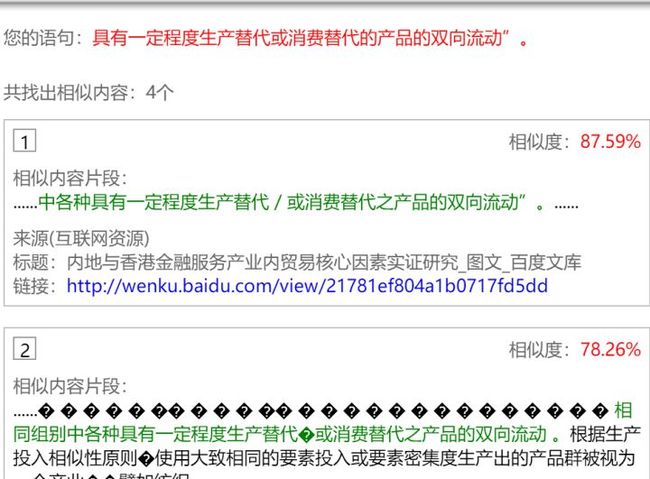
这种定义引用类的红色句子,相似度88%,应该无可救药了吧?但是查重分解句子是会根据标点的,我删去句子后面的逗号,将短句连成长句以增加该句的分母,对语序做了调整,最终竟然硬生生把这句定义给绿化成功了(请叫我绿化小达人)。
修改后的句子:“SITC分类规定的相同组别中具有一定生产或消费替代程度的产品的双向流动”,绿化成功√。我也不知道这样一改相似度怎么就降到50%以下了,但是这种思路可以借鉴,就是短句并长句增加分母。同理也可以通过扩句增加分母,其精髓在于用自己的语言稀释干货(注水绿化法),以降低相似度。如“A导致了B”改成“C带来的A导致了D现象的产生最终造成B的结果”,其中C和D可以扯得越长越好,这样句子相似度会大大降低。

3.长句分解为短句弃卒保帅
总有些专业词组几乎不可能修改,而且在句子中占的比重过大,需要战略性地放弃修改这些部分,把他们独立成一个短句分离出去以方便后面句子的绿化工程。例如:
Nuno 和Faustino(2009)运用面板数据模型对葡萄牙和金砖国家贸易中的产业内贸易水平影响因素进行的实证分析表明,一国资源禀赋的数量与该国产业内贸易发展程度存在负相关性。
这个长句子开头部分的“Nuno 和Faustino(2009)...”一堆字符是无法改变的(名字换成中文也同样被人写过了),非常占空间,即便把后面的内容加长很多也很难把整个句子的相似度降到50%以下。这个时候可以放弃小部分的降重,把前半句改成独立的句子“Nuno 和Faustino(2009)同样对IIT影响因素进行了研究。”后面也改写成独立的句子“他们应用面板数据模型进行的实证研究发现,在葡萄牙与金砖国家的双边贸易中,初始的自然资源对该国对外贸易的IIT指数具有负面的影响效应”。这样虽然前面的句子依然重复,但是舍弃了大段无法改变的重复字符后,后面的句子就有了被绿化的可能,整体的重复率还是会降低。
4.无可救药型直接删去
下面这个红色的句子估计被无数人用过了,大家也很可能已经尝试过用各种姿势♂绿他,于是知难而退,索性直接删掉,也不影响文章的意思。

四、经验总结
由于在线改重功能可以改一句话及时看到新的重复率,所以可以利用算法技巧不断修正结果,非常好用。但是仍存在该网站和知网查重率不一致的问题,在一些情况下查重率偏差很大。
重复率有差异的原因主要在两处:一是算法严格程度差异;二是网站背后的数据库大小差异。
1、算法严格程度差异可能是由于50%标绿这个阈值大小不同,也可能是单句相似度的Jaccard相似度/余弦相似度/Jaro相似度等指标选择不同,但知网算法的严格程度通常小于外库。原因在于第2点差异。
2、知网的数据库大于其他查重网站。知网本科论文查重与其他网站的最大区别在于知网pmlc有【大学生论文联合对比库】,这个数据库收录了各学校历年的毕业论文,这些论文是其他网站所没有的。因此其他网站会通过严格算法来使查重结果和知网平衡,这也是很多抄袭、大篇幅粘贴者的查重率在知网和外网差异很高的原因。但是对于自己写作的有原则的大学生来说,paper系列的查重结果肯定是有参考意义的。并且有些同学认真写的论文在知网的重复率很可能比其他网站更低。(案例A:某同学前几天私信我说paperpass重复率39%,但是他说自己真的是认真写的。我就建议他在学校知网上试一次,结果出来竟然是6.9%,这说明paperpass的单句算法过于严格)
相信大多数同学还是坚持原创,那么用Paperfree系列以及上述降重技巧肯定能满足需求了,降到5~10%不是什么难事。
作者:Edo.K
来源:知乎