Scrapy框架抓取四川大学公共管理学院教师信息
目录
- 项目要求
- 准备步骤
- 代码编写
- 结果分析
- 问题解析
- 相关链接
一,项目要求
- 明确目标网址和items:我们要抓取的是四川大学公共管理学院教师主页128位教师信息,包括的item有name(x姓名),title(职称),dep(所属部系),email(邮件),img(图片)以及详情页面的decs(个人简介)
- 明确分页处理的方法
- 明确怎么获取详情页信息
- 会使用xpath来编写数据路径
二 , 准备步骤
- 在Scrapy当中下载requests库,如果已经下载了的,则可以跳过这个步骤
Scrapy使用request对象来爬取web站点。
request对象由spiders对象产生,经由Scheduler传送到Downloader,Downloader执行request并返回response给spiders。
代码如下:
scrapy install requests- 新建一个项目,在这里我新建的项目名是teacher。在项目当中会用到pipelines.py,items.py, settings.py以及spider文件夹
scrapy startproject teacher三, 代码编写
- 解读四川大学公共管理学院教师主页页面代码:
1.编码方式:

从上图可以看出编码方式采用的是UTF-8,因为抓取的是中文信息,有可能出现乱码或者抓取到的数据是/073801/aj90/ 等形式,这里我们先记住它的编码方式。
2.数据所在目录和路径:
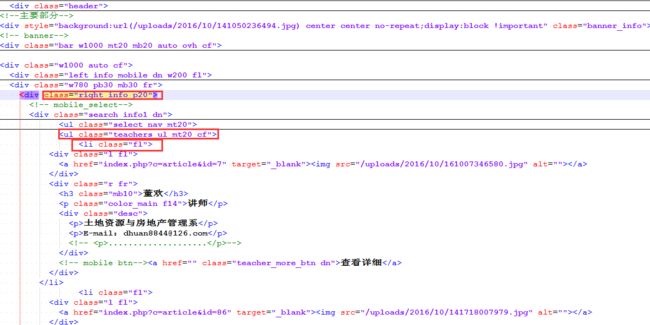
上图中我们可以看到我们要抓取的教师信息都在 //ul[@class=’teachers_ul mt20 cf’]/li 这里面,而且姓名所在的路径是div[@class=’r fr’]/h3/text() ,职称所在路径是div[@class=’r fr’]/p/text() ,邮件所在路径div[@class=’r fr’]/div[@class=’desc’]/p[2]/text() ,部门所在路径div[@class=’r fr’]/div[@class=’desc’]/p[1]/text() ,以及图片对应的链接 div[@class=’l fl’]/a/@href ,图片地址div[@class=’l fl’]/img/@src
在编写路径时,可以用scrapy shell 进行验证,这里不再详述.
3.下一页
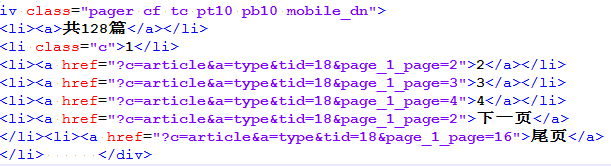
可以看到下一页是在li标签的倒数第二个,因此我的下一页路径可以写成 //div[@class=’pager cf tc pt10 pb10 mobile_dn’]/li[last()-1]/a/@href
- 代码编写
1.item.py
我们要在item.y中定义我们的变量名
import scrapy
class TeacherItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
img = scrapy.Field()
dep = scrapy.Field()
email = scrapy.Field()
url = scrapy.Field()
decs = scrapy.Field()
pass2.编写teachespider.py文件并导入spider中,完整代码如下:
#coding:utf-8
#!/usr/bin/python
# -*- coding:utf-8 -*-
import scrapy
import requests
import urllib2
from scrapy.selector import Selector
from teacher.items import TeacherItem
import re
import os
from urllib2 import urlopen
class TeacherSpider(scrapy.Spider):
name = "teacherspider" #爬虫名teacherspider
allowed_domains = ["ggglxy.scu.edu.cn"]
start_urls = [
'http://ggglxy.scu.edu.cn/index.php?c=article&a=type&tid=18',
]
webdata = requests.get('http://ggglxy.scu.edu.cn/index.php')
webdata.encoding = 'UTF-8'
print(webdata.text) #打印出网页html信息
def parse(self, response):
sel = Selector(response)
for teacher in response.xpath("//ul[@class='teachers_ul mt20 cf']/li"): #爬取数据所在目录
item = TeacherItem()
item['name'] = teacher.xpath("div[@class='r fr']/h3/text()").extract_first()
item['title'] = teacher.xpath("div[@class='r fr']/p/text()").extract_first()
# -*- 图片处理 -*-
img_src = teacher.xpath("div[@class='l fl']/img/@src").extract_first() #图片路径
teacher_name = "%s.jpg" % (item['name']) #给图片重新命名
img_path = os.path.join("E:\\io&ir\\teacher", teacher_name) #将图片下载到本地
item['img'] = img_path
item['email'] = teacher.xpath("div[@class='r fr']/div[@class='desc']/p[2]/text()").extract_first()
item['dep'] = teacher.xpath("div[@class='r fr']/div[@class='desc']/p[1]/text()").extract_first()
href = teacher.xpath("div[@class='l fl']/a/@href").extract_first()
request=scrapy.http.Request(response.urljoin(href),callback=self.parse_decs) #回调抓取详情页信息函数
request.meta['item']=item
yield request
# -*- 分页处理 -*-
nextpage = sel.xpath("//div[@class='pager cf tc pt10 pb10 mobile_dn']/li[last()-1]/a/@href").extract_first()
if nextpage:
nextpage = 'http://ggglxy.scu.edu.cn/index.php'+nextpage
yield scrapy.http.Request(nextpage, callback=self.parse)
# -*- 详情页信息抓取 -*-
def parse_decs(self,response):
item=response.meta['item']
item['url']=response.url
item['decs']=response.xpath("//div[@class='desc']/text()").extract_first()
yield item执行爬取命令
scrapy crawl teacherspider -o teacher.xml3.pipeline.py数据处理和setting.py设置 ( 相关参考)
执行上述爬取命令,有可能出现乱码数据,这里介绍两种处理方法:
(1)在 scrapy crawl teacherspider -o teacher.json后面再加上 -s FEED-EXPORT-ENCODING=utf-8,下载时数据自动导成为utf-8编码的数据,即
scrapy crawl teacherspider -o teacher.xml -s FEED_EXPORT_ENCODING=utf-8(2)在pipelines.py中加入如下代码
import codecs
class TeacherPipeline(object):
def __init__(self):
self.file = codecs.open('teacher.json', 'w', encoding='utf-8') #文件自动保存为utf-8格式的teacher.json文件
def process_item(self, item, spider):
line = json.dumps(dict(item),ensure_ascii=False) + '\n'
#print line
#self.file.write(line.decode("unicode_escape"))
self.file.write(line)
return item同时,在settings.py中启用
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'teacher.pipelines.TeacherPipeline': 300,
}设置好之后,执行爬取命令即可得到正常编码数据
scrapy crawl teacherspider上面两种方法各有优势,根据个人喜好使用。第一种是不需要再编写代码,但是每次执行爬取命令时较复杂;而第二种的话是数据爬取之后的处理操作,更偏向结构化,而且爬取命令更简单,且会自动生成文档。
四,结果解读
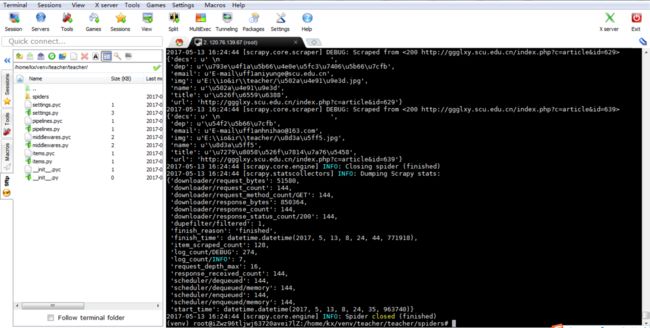
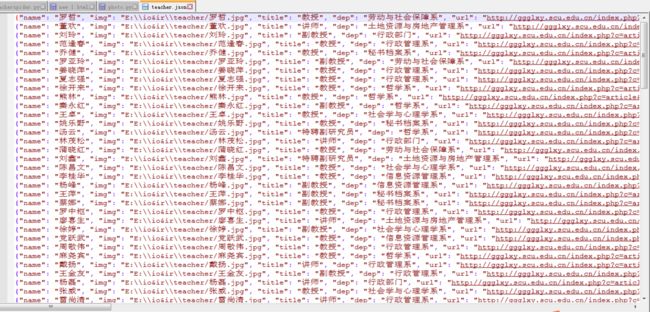
页面成功抓取信息,下载teacher.json文件并打开如下图,刚好128条
五,问题解析
- 路径问题,在写xpath过程当中一定要注意路径,严格按照要求来编写,常见报错
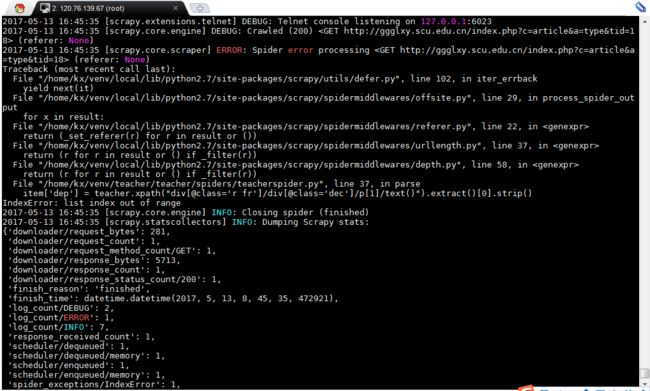

- 编码问题(上面以详述)
-包导入问题。不同版本的python 在导入包的时候执行的命令不一样
- 分页问题。控制好结束语句,并且要保证将所以数据抓取到。
- 图片下载。如果单按照上述代码进行图片抓取的话,是不能达到想要的结果的。我找了很多资料,图片下载太麻烦,因此先放弃用scrapy,目前在尝试用jupyter notebook 。
- 传值问题。此项目值,我们要抓取详情页面的信息,要获取详情页url同时还要进行值的提出
- 数据顺序。如上数据结构页,可以看到提取到的数据不是按html顺序提取的,应该可以通过控制优先级来控制。
scrapy异步处理Request请求,Scrapy发送请求之后,不会等待这个请求的响应,可以同时发送其他请求或者做别的事情。
六,相关链接
- scrapy shell
- requests
- 编码问题
- 常见错误
- 参考案例1
- [参考案例2](http://www.jianshu.com/p/ad6bf3f2a883?utm_campaign=haruki&utm_content=note&utm_medium=reader_share&utm_source=qq
)