Solr+MMSEG4J的简单学习
目录
- solr介绍
- MMSEG4J介绍
- 准备工具
- solr环境搭建
- 分词方法与效果分析
- 分词结果提交
- 词云分析
- 参考链接
一,solr介绍
Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。每个文档由一系列的 Field 构成,每个 Field 表示资源的一个属性。Solr 中的每个 Document 需要有能唯一标识其自身的属性,默认情况下这个属性的名字是 id,在 Schema 配置文件中使用:id进行描述。
二,MMSEG4J介绍
mmseg4j 是用 Chih-Hao Tsai 的 MMSeg 算法实现的中文分词器。并实现了 lucene 的 analyzer 和 solr 的 TokenizerFactory 以方便在 Lucene 和 Solr 中使用。
对 lucene 来说 ,mmseg4j 有以下四个 analyzer:SimpleAnalyzer、ComplexAnalyzer、MaxWordAnalyzer、MMSegAnalyzer。前面三个都是继承 MMSegAnalyzer,MMSegAnalyzer 默认使用 max-word 方式分词。四个分次类涉及到了三个分词方法:Simple、Complex、max-word。
三,准备工具(不用tomcat)
(1)
solr安装包。官方下载地址 http://www.apache.org/dyn/closer.lua/lucene/solr/6.5.1 。solr下载有三个包,不同系统下载不同的包,我是windows本地搭建进行分词,用的是jetty容器 ,在本地运行,下的是solr-6.5.1 .zip文件。
Solr 程序包 的目录结构
- build :在solr 构建过程中放置已编译文件的目录。
- client :包含了一些特定语言调用Solr 的API 客户端程序,目前只有Ruby 可供选择,Java 客户端叫SolrJ 在src/solrj 中可以找到。
- dist :存放Solr 构建完成的JAR 文件、WAR 文件和Solr 依赖的JAR 文件。
- example :是一个安装好的Jetty 中间件,其中包括一些样本数据和Solr 的配置信息。
- example/etc :Jetty 的配置文件。
- example/multicore :当安装Slor multicore 时,用来放置多个Solr 主目录。
- example/solr :默认安装时一个Solr 的主目录。
- example/webapps :Solr 的WAR 文件部署在这里。
- src :Solr 相关源码。
- src/java :Slor 的Java 源码。
- src/scripts :一些在大型产品发布时一些有用的Unix bash shell 脚本。
- src/solrj :Solr 的Java 客户端。
- src/test :Solr 的测试源码和测试文件。
- src/webapp :Solr web 管理界面。管理界面的Jsp 文件都放在web/admin/ 下面,可以根据你的需要修改这些文件。
(2)MMSEG4J分词工具包下载解压,我用的是mmseg4j 2.3.0版本
(3)目录安装:将solr安装在F:/solr/solr-6.5.1目录下,将MMSEG4J安装在F:/MMSEG4J目录下
F:/solr/solr-6.5.1
F:/MMSEG4J
注意:solr版本与mmseg4j版本一定要对应,否则易出问题。我这里用的都是最新的版本。
四,solr环境搭建
(1)在tomcat服务器下运行
tomcat9.0下载并解压 http://tomcat.apache.org/download-90.cgi, 按安装过程一步一步,我默认使用给定的端口号8080。
tomcat和solr的具体配置过程:
将solr-6.5.1\server\solr-webapp下的webapp文件夹拷贝到tomcat\webapps目录下,并将webapp重命名为solr(可以重命名为取任意名称)。
将solr-6.5.1\server\lib\ext下的所有jar包拷贝到tomcat\webapps\solr\WEB-INF\lib下
在WEB-INF下创建一个classses文件夹,并将solr-6.5.1\server\resources下的log4j.properties配置文件拷贝到classes文件夹下
在tomcat\webapps\solr下创建文件夹solrhome(可任意取名),将solr-6.5.1\server\solr下的所有内容拷贝到solrhome下面,此时tomcat\webapps\solr和tomcat\webapps\solr\solrhome文件夹目录结构如图

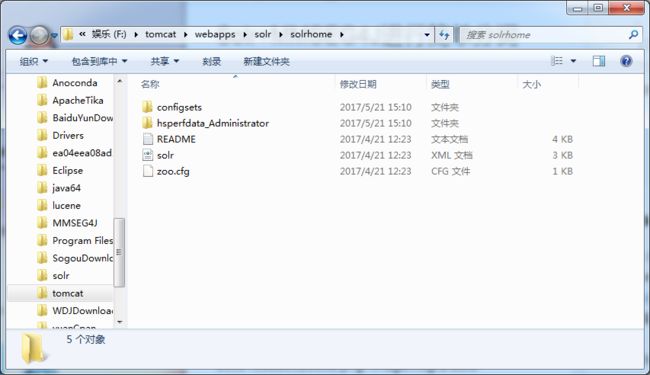
修改tomcat\webapps\solr\WEB-INF\web.xml,找到图示代码进行修改(注释掉),箭头所指的地方改成自己定义的solrhome所在的路径。

运行tomcat,访问http://localhost:8080/solr/index.html ,出现404错误。
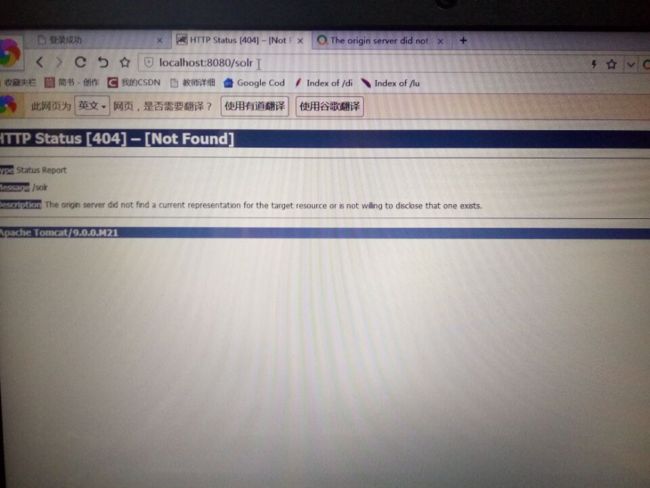
这个问题改了许久没有成功,因此采用了第二种方法基于jetty容器的运行。
(2)solr基于jetty容器的运行
- 在命令提示窗口定位到solr安装路径并且使用solr start命令后台启动solr
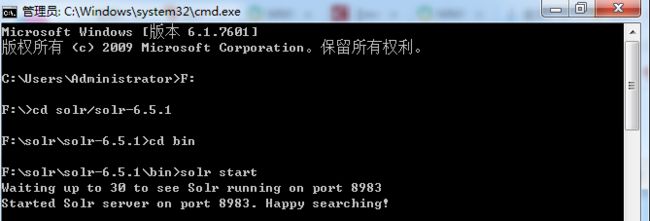
我们还可以输入命令
solr start -help
来查看更多命令操作


输入start solr之后,如果成功出现solr主页面(如下图),则说明solr安装配置没有没有问题,可以进行下一步操作。由于使用了自带的Jetty Server,所以启动后的默认端口就是8983。注意,在solr页面操作过程当中,要一直开着dos窗口。

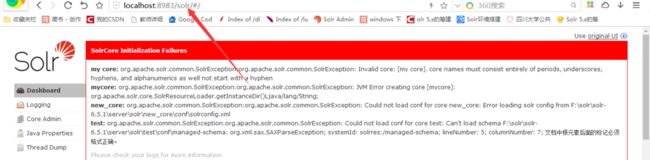
2.接着创建一个core
在dos输入命令 solr create -c mycore,创建一个mycore的索引库
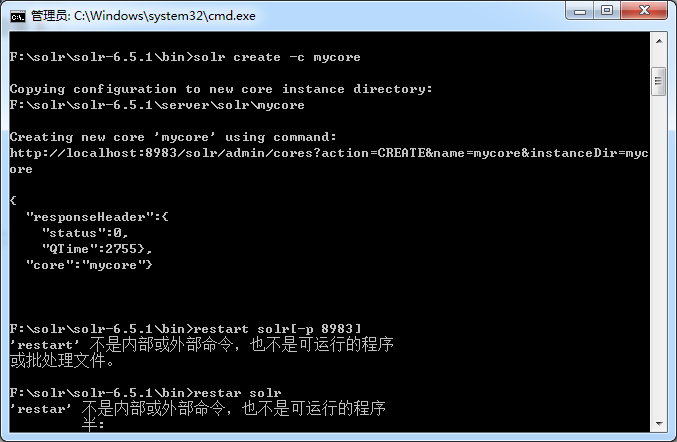
出现如下图所示则说明创建成功:
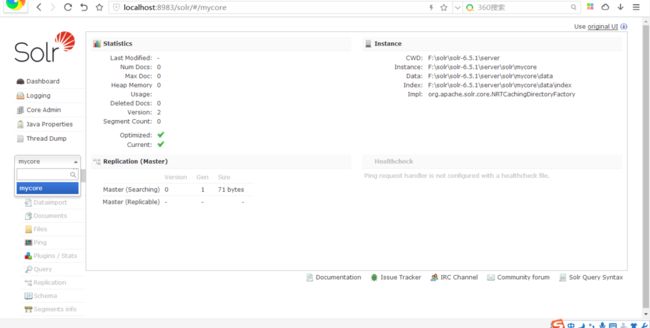
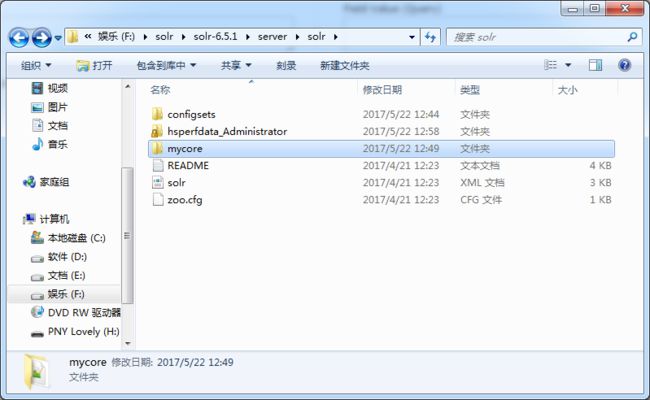
3.接着我们可以在F:\solr\solr-6.5.1\server\solr 下面看到刚刚创建的core包
点开mycore->conf->managed-schema(在5.0前,该文件是shcema.xml文件),点开并添加如下代码,dicPath改成自己managed-schema的路径:
<field name="mmseg4j_complex_name" type="text_mmseg4j_complex" indexed="true" stored="true"/>
<field name="mmseg4j_maxword_name" type="text_mmseg4j_maxword" indexed="true" stored="true"/>
<field name="mmseg4j_simple_name" type="text_mmseg4j_simple" indexed="true" stored="true"/>
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="F:\solr\solr-6.5.1\server\solr\mycore\conf"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
analyzer>
fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="F:\solr\solr-6.5.1\server\solr\mycore\conf"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
analyzer>
fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="F:\solr\solr-6.5.1\server\solr\mycore\conf"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
analyzer>
fieldType>
4.保存,重启solr
solr restart -p 8983
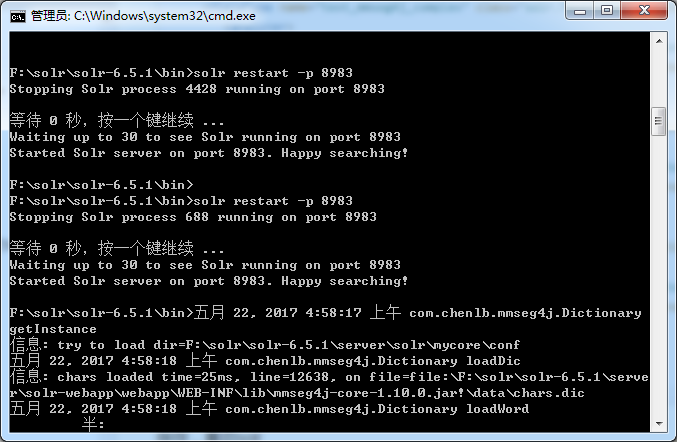
之后刷新我们的solr界面,mycore->analysis->select,可以看到成功的新增的Field

在Field Value中输入内容,选择FieldType,点击Analyse Values即可,结果如图:
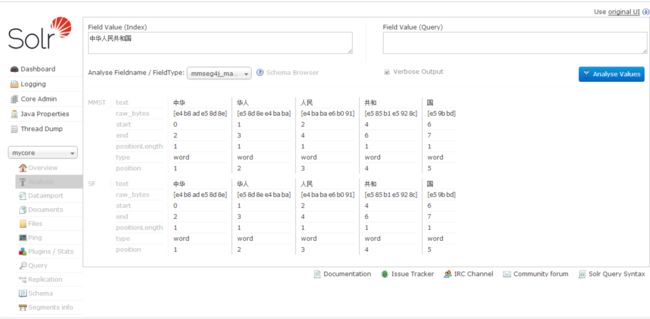
五,分词方法与效果分析
经济学博士四川大学公共管理学院教授博士生导师副院长全国政治学类专业教学指导委员会委员四川省政治学会常务理事四川省人民政府职能转变专家组组长成都市人民政府职能转变专家组组长西藏自治区人民政府咨询委员四川社会治理与公共安全研究智库首席专家四川大学社会发展与社会风险控制研究中心四川省社会科学重点研究基地副主任四川大学地方政府创新中心副主任
对这一段话采用不同的分词方法进行分词,比较他们的效果:
(1)mmseg4j_complex_name,分词效果如图。重点看对“西藏自治区人民政府”的分词

分析:Complex:在一串字符中,找到所以可能的三字快开始匹配,寻找最大长度的字块。
(2)mmseg4j_maxword_name,分词效果如图

分析:maxword是在complex分词后的结果去掉或保留单字。
(3)mmseg4j_simple_name
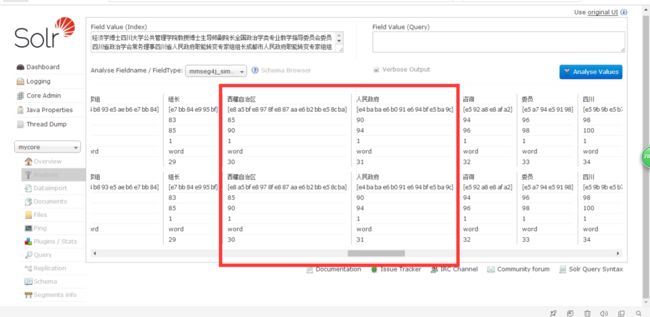
分析:simple:在一串字符串中从开头匹配子串,找到所有可能的匹配。
六,分词结果提交
这里我借用jieba分词来实现最终的分词结果。因为目前我还没有找到直接在solr界面对一个文件中的内容进行分词,但是jieba可以实现。
生成一个teacher.txt文件,存放四川大学教师简介信息。打开jupyter notebook界面(具体操作可以参考我上一篇博客),上传teacher.txt文件,编写如下代码,则可以达到分词效果如图:


将结果导出,并借助Tika工具,转换成xml文件。
七,词频统计
同样利用jupyter notebook+jieba,来实现词频统计,代码和结果如下图,我们统计前200个出现频率最高的词和他们的次数:

用Tika格式转换可以更明了的看到词频统计

参考链接:
1 . http://www.cnblogs.com/sainaxingxing/p/6065882.html
2 . http://m.blog.csdn.net/article/details?id=52065562
3 . http://blog.csdn.net/qq_38425619/article/details/72486596