MFS分布式文件系统实战(4)——MFS高可用(pacemaker+corosync+vmfence+mfsmaster)
1.什么是pacemaker?
Pacemaker是一个集群资源管理器。
它利用集群基础构件(OpenAIS 、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,
以实现群集服务(亦称资源)的最大可用性。
它可以做几乎任何规模的集群,并带有一个强大的依赖模式,让管理员能够准确地表达群集资源之间的关系(包括顺序和位置)。
几乎任何可以编写的脚本,都可以作为管理起搏器集群的一部分。
尤为重要的是Pacemaker不是一个heartbeat的分支,似乎很多人存在这样的误解。
Pacemaker是CRM项目(亦名V2资源管理器)的延续,该项目最初是为heartbeat而开发,但目前已经成为独立项目。
2.什么是corosync?
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
Corosync是集群管理套件的一部分,通常会与其他资源管理器一起组合使用它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。它是一个新兴的软件,2008年推出,但其实它并不是一个真正意义上的新软件,在2002年的时候有一个项目Openais , 它由于过大,分裂为两个子项目,其中可以实现HA心跳信息传输的功能就是Corosync ,它的代码60%左右来源于Openais. Corosync可以提供一个完整的HA功能,但是要实现更多,更复杂的功能,那就需要使用Openais了。Corosync是未来的发展方向。在以后的新项目里,一般采用Corosync,而hb_gui可以提供很好的HA管理功能,可以实现图形化的管理。另外相关的图形化有RHCS的套件luci+ricci,当然还有基于java开发的LCMC集群管理工具。
pcs(Pacemaker/Corosync configuration system):集群管理工具pcs
pcs命令配置群集示例
一、建立群集:
[shell]# pcs cluster auth node1 node2 #配置群集节点的认证as the hacluster user
[shell]# pcs cluster setup --name mycluster node1 node2 #创建一个两个节点的集群
[shell]# pcs cluster start --all #启动所有集群
[shell]# pcs resource defaults resource-stickiness=100 #设置资源默认粘性
[shell]# pcs resource defaults
[shell]# pcs resource op defaults timeout=90s #设置资源超时时间
[shell]# pcs resource op defaults
[shell]# pcs property set no-quorum-policy=ignore #两个节点时,忽略节点quorum功能
[shell]# pcs property set stonith-enabled=false #没有fencing设备时,禁用STONITH组件功能;在 stonith-enabled="false" 的情况下,分布式锁管理器 (DLM) 等资源以及依赖DLM 的所有服务(例如 cLVM2、GFS2 和 OCFS2)都将无法启动。
[shell]# crm_verify -L -V #验证群集配置信息
二、建立集群资源
1、查看可用资源
[shell]# pcs resource list ## 查看支持资源列表,pcs resource list ocf:heartbeat
[shell]# pcs resource describe agent_name ## 查看资源使用参数,pcs resource describe ocf:heartbeat:IPaddr2
2、配置虚拟IP
[shell]# pcs resource create ClusterIP ocf:heartbeat:IPaddr2 \
ip="192.168.10.15" cidr_netmask=32 nic=eth0 op monitor interval=30s
3、配置Apache(httpd)
[shell]# pcs resource create WebServer ocf:heartbeat:apache \
httpd="/usr/sbin/httpd" configfile="/etc/httpd/conf/httpd.conf" \
statusurl="http://localhost/server-status" op monitor interval=1min
4、配置Nginx
[shell]# pcs resource create WebServer ocf:heartbeat:nginx \
httpd="/usr/sbin/nginx" configfile="/etc/nginx/nginx.conf" \
statusurl="http://localhost/ngx_status" op monitor interval=30s
5.1、配置FileSystem
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="/dev/sdb1" directory="/var/www/html" fstype="ext4"
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="-U 32937d65eb" directory="/var/www/html" fstype="ext4"
5.2、配置FileSystem-NFS
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="192.168.10.18:/mysqldata" directory="/var/lib/mysql" fstype="nfs" \
options="-o username=your_name,password=your_password" \
op start timeout=60s op stop timeout=60s op monitor interval=20s timeout=60s
6、配置Iscsi
[shell]# pcs resource create WebData ocf:heartbeat:iscsi \
portal="192.168.10.18" target="iqn.2008-08.com.starwindsoftware:" \
op monitor depth="0" timeout="30" interval="120"
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="-U 32937d65eb" directory="/var/www/html" fstype="ext4" options="_netdev"
7、配置DRBD
[shell]# pcs resource create WebData ocf:linbit:drbd \
drbd_resource=wwwdata op monitor interval=60s
[shell]# pcs resource master WebDataClone WebData \
master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
[shell]# pcs resource create WebFS ocf:heartbeat:Filesystem \
device="/dev/drbd1" directory="/var/www/html" fstype="ext4"
8、配置MySQL
[shell]# pcs resource create MySQL ocf:heartbeat:mysql \
binary="/usr/bin/mysqld_safe" config="/etc/my.cnf" datadir="/var/lib/mysql" \
pid="/var/run/mysqld/mysql.pid" socket="/tmp/mysql.sock" \
op start timeout=180s op stop timeout=180s op monitor interval=20s timeout=60s
9、配置Pingd,检测节点与目标的连接有效性
[shell]# pcs resource create PingCheck ocf:heartbeat:pingd \
dampen=5s multiplier=100 host_list="192.168.10.1 router" \
op monitor interval=30s timeout=10s
10、创建资源clone,克隆的资源会在全部节点启动
[shell]# pcs resource clone PingCheck
[shell]# pcs resource clone ClusterIP clone-max=2 clone-node-max=2 globally-unique=true ## clone-max=2,数据包分成2路
[shell]# pcs resource update ClusterIP clusterip_hash=sourceip ## 指定响应请求的分配策略为:sourceip
三、调整集群资源
1、配置资源约束
[shell]# pcs resource group add WebSrvs(资源组名称) ClusterIP(添加资源的名称) ## 配置资源组,组中资源会在同一节点运行
[shell]# pcs resource group remove WebSrvs ClusterIP ## 移除组中的指定资源
[shell]# pcs resource master WebDataClone WebData ## 配置具有多个状态的资源,如 DRBD master/slave状态
[shell]# pcs constraint colocation add WebServer ClusterIP INFINITY ## 配置资源捆绑关系
[shell]# pcs constraint colocation remove WebServer ## 移除资源捆绑关系约束中资源
[shell]# pcs constraint order ClusterIP then WebServer ## 配置资源启动顺序
[shell]# pcs constraint order remove ClusterIP ## 移除资源启动顺序约束中资源
[shell]# pcs constraint ## 查看资源约束关系, pcs constraint --full
2、配置资源位置
[shell]# pcs constraint location WebServer prefers node11 ## 指定资源默认某个节点,node=50 指定增加的 score
[shell]# pcs constraint location WebServer avoids node11 ## 指定资源避开某个节点,node=50 指定减少的 score
[shell]# pcs constraint location remove location-WebServer ## 移除资源节点位置约束中资源ID,可用pcs config获取
[shell]# pcs constraint location WebServer prefers node11=INFINITY ## 手工移动资源节点,指定节点资源的 score of INFINITY
[shell]# crm_simulate -sL ## 验证节点资源 score 值
3、修改资源配置
[shell]# pcs resource update WebFS ## 更新资源配置
[shell]# pcs resource delete WebFS ## 删除指定资源
4、管理群集资源
[shell]# pcs resource disable ClusterIP ## 禁用资源
[shell]# pcs resource enable ClusterIP ## 启用资源
[shell]# pcs resource failcount show ClusterIP ## 显示指定资源的错误计数
[shell]# pcs resource failcount reset ClusterIP ## 清除指定资源的错误计数
[shell]# pcs resource cleanup ClusterIP ## 清除指定资源的状态与错误计数
四、配置Fencing设备,启用STONITH
1、查询Fence设备资源
[shell]# pcs stonith list ## 查看支持Fence列表
[shell]# pcs stonith describe agent_name ## 查看Fence资源使用参数,pcs stonith describe fence_vmware_soap
2、配置fence设备资源
[shell]# pcs stonith create ipmi-fencing fence_ipmilan \
pcmk_host_list="pcmk-1 pcmk-2" ipaddr="10.0.0.1" login=testuser passwd=acd123 \
op monitor interval=60s
mark:
If the device does not support the standard port parameter or may provide additional ones, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
If the device does not know how to fence nodes based on their uname, you may also need to set the special pcmk_host_map parameter. See man stonithd for details.
If the device does not support the list command, you may also need to set the special pcmk_host_list and/or pcmk_host_check parameters. See man stonithd for details.
If the device does not expect the victim to be specified with the port parameter, you may also need to set the special pcmk_host_argument parameter. See man stonithd for details.
example: pcmk_host_argument="uuid" pcmk_host_map="node11:4;node12:5;node13:6" pcmk_host_list="node11,node12" pcmk_host_check="static-list"
3、配置VMWARE (fence_vmware_soap)
特别说明:本次实例中使用了第3项(pcs stonith create vmware-fencing fence_vmware_soap)这个指定pcmk配置参数才能正常执行Fencing动作。
3.1、确认vmware虚拟机的状态:
[shell]# fence_vmware_soap -o list -a vcenter.example.com -l cluster-admin -p -z ## 获取虚拟机UUID
[shell]# fence_vmware_soap -o status -a vcenter.example.com -l cluster-admin -p -z -U ## 查看状态
[shell]# fence_vmware_soap -o status -a vcenter.example.com -l cluster-admin -p -z -n
3.2、配置fence_vmware_soap
[shell]# pcs stonith create vmware-fencing-node11 fence_vmware_soap \
action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \
port="node11" shell_timeout=60s login_timeout=60s op monitor interval=90s
[shell]# pcs stonith create vmware-fencing-node11 fence_vmware_soap \
action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \
uuid="421dec5f-c484-3d69-ddfb-65af46530581" shell_timeout=60s login_timeout=60s op monitor interval=90s
[shell]# pcs stonith create vmware-fencing fence_vmware_soap \
action="reboot" ipaddr="192.168.10.10" login="vmuser" passwd="vmuserpd" ssl="1" \
pcmk_host_argument="uuid" pcmk_host_check="static-list" pcmk_host_list="node11,node12" \
pcmk_host_map="node11:421dec5f-c484-3d69-ddfb-65af46530581;node12:421dec5f-c484-3d69-ddfb-65af46530582" \
shell_timeout=60s login_timeout=60s op monitor interval=90s
注:如果配置fence_vmware_soap设备时用port=vm name在测试时不能识别,则使用uuid=vm uuid代替;
建议使用 pcmk_host_argument、pcmk_host_map、pcmk_host_check、pcmk_host_list 参数指明节点与设备端口关系,格式:
pcmk_host_argument="uuid" pcmk_host_map="node11:uuid4;node12:uuid5;node13:uuid6" pcmk_host_list="node11,node12,node13" pcmk_host_check="static-list"
4、配置SCSI
[shell]# ls /dev/disk/by-id/wwn-* ## 获取Fencing磁盘UUID号,磁盘须未格式化
[shell]# pcs stonith create iscsi-fencing fence_scsi \
action="reboot" devices="/dev/disk/by-id/wwn-0x600e002" meta provides=unfencing
5、配置DELL DRAC
[shell]# pcs stonith create dell-fencing-node11 fence_drac
.....
6、管理 STONITH
[shell]# pcs resource clone vmware-fencing ## clone stonith资源,供多节点启动
[shell]# pcs property set stonith-enabled=true ## 启用 stonith 组件功能
[shell]# pcs stonith cleanup vmware-fencing ## 清除Fence资源的状态与错误计数
[shell]# pcs stonith fence node11 ## fencing指定节点
7、管理tomcat
[shell]#pcs resource create tomcat ersweb statusurl=http://127.0.0.1 java_home=/usr/java/jdk1.6.0_12/ catalina_home=/usr/local/Ers/tomcat/ op monitor interval=30s
五、群集操作命令
1、验证群集安装
[shell]# pacemakerd -F ## 查看pacemaker组件,ps axf | grep pacemaker
[shell]# corosync-cfgtool -s ## 查看corosync序号
[shell]# corosync-cmapctl | grep members ## corosync 2.3.x
[shell]# corosync-objctl | grep members ## corosync 1.4.x
2、查看群集资源
[shell]# pcs resource standards ## 查看支持资源类型
[shell]# pcs resource providers ## 查看资源提供商
[shell]# pcs resource agents ## 查看所有资源代理
[shell]# pcs resource list ## 查看支持资源列表
[shell]# pcs stonith list ## 查看支持Fence列表
[shell]# pcs property list --all ## 显示群集默认变量参数
[shell]# crm_simulate -sL ## 检验资源 score 值
3、使用群集脚本
[shell]# pcs cluster cib ra_cfg ## 将群集资源配置信息保存在指定文件
[shell]# pcs -f ra_cfg resource create ## 创建群集资源并保存在指定文件中(而非保存在运行配置)
[shell]# pcs -f ra_cfg resource show ## 显示指定文件的配置信息,检查无误后
[shell]# pcs cluster cib-push ra_cfg ## 将指定配置文件加载到运行配置中
4、STONITH 设备操作
[shell]# stonith_admin -I ## 查询fence设备
[shell]# stonith_admin -M -a agent_name ## 查询fence设备的元数据,stonith_admin -M -a fence_vmware_soap
[shell]# stonith_admin --reboot nodename ## 测试 STONITH 设备
5、查看群集配置
[shell]# crm_verify -L -V ## 检查配置有无错误
[shell]# pcs property ## 查看群集属性
[shell]# pcs stonith ## 查看stonith
[shell]# pcs constraint ## 查看资源约束
[shell]# pcs config ## 查看群集资源配置
[shell]# pcs cluster cib ## 以XML格式显示群集配置
6、管理群集
[shell]# pcs status ## 查看群集状态
[shell]# pcs status cluster
[shell]# pcs status corosync
[shell]# pcs cluster stop [node11] ## 停止群集
[shell]# pcs cluster start --all ## 启动群集
[shell]# pcs cluster standby node11 ## 将节点置为后备standby状态,pcs cluster unstandby node11
[shell]# pcs cluster destroy [--all] ## 删除群集,[--all]同时恢复corosync.conf文件
[shell]# pcs resource cleanup ClusterIP ## 清除指定资源的状态与错误计数
[shell]# pcs stonith cleanup vmware-fencing ## 清除Fence资源的状态与错误计数
3.搭建实验环境
实验环境:rhel7.5
| 主机信息 | 主机号 |
|---|---|
| server1(mfsmaster+corosync+pacemaker) | 172.25.8.1 |
| server2(mfschunker) | 172.25.8.2 |
| server3(mfschunker) | 172.25.8.3 |
| server4( mfsmaster+corosync+pacemaker ) | 172.25.8.4 |
该实验是在上一篇文章的环境的基础上进行的
(1)创建第四个快照并且开启
[root@foundation8 images]# qemu-img create -f qcow2 -b rhel7.5-1.qcow2 mfs4
(2)用真机连接第四个虚拟机
[root@foundation8 images]# ssh root@172.25.8.4
(3)给server4配置master服务


(4)进行域名解析
![]()

(5)编写系统的配置文件,防止服务异常关闭
![]()
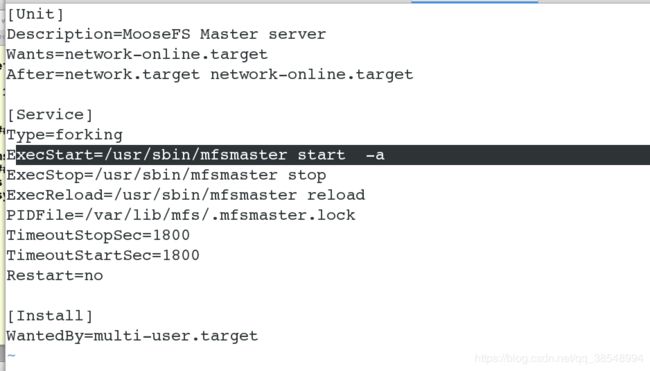
(6)开启服务

#1 mfsmaster的高可用
(1)配置mfsmaster,先获取高可用安装包
ResilientStorage:是高可用中的一个插件;
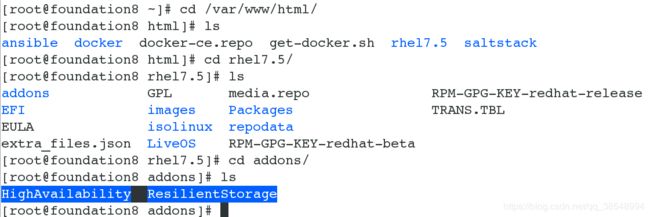

#1 给server1安装pacemaker,corosyncy,pcs

(2) 给server1做server1和server4的ssh免密服务
因为在做vip漂移的时候,如果没有ssh 免密服务,那么就需要密码的认证服务,因此无法进行vip漂移
#生成密钥,方便连接
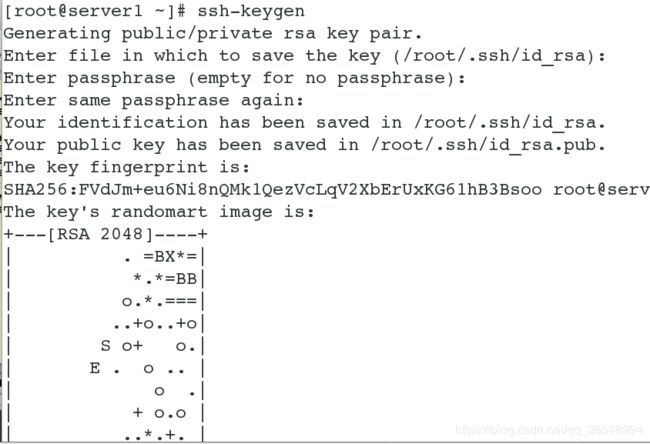
设置server4和自己的免密
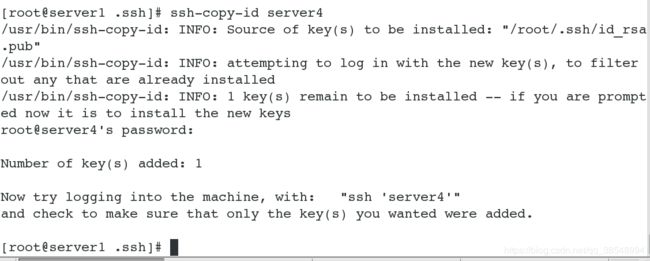
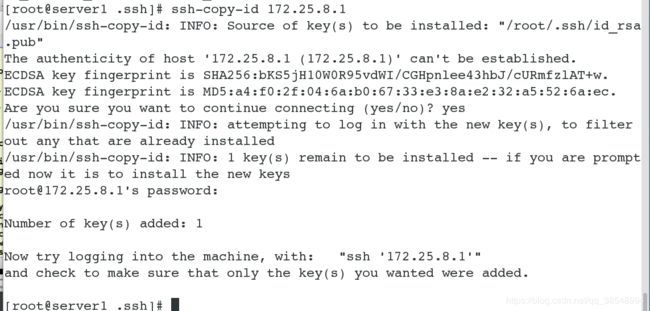
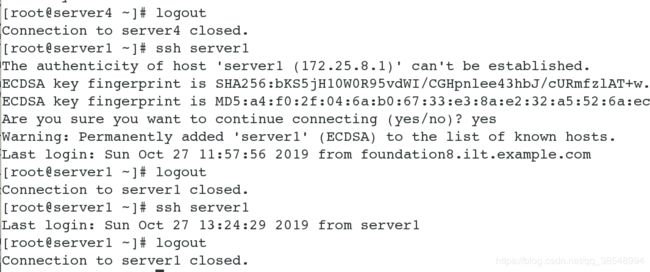
(3)开启服务
[root@server1 ~]# systemctl start pcsd
[root@server1 ~]# systemctl enable pcsd
[root@server1 ~]# passwd hacluster
Changing password for user hacluster. # 设置密码,主备必须相同
New password: Retype new password:
passwd: all authentication tokens updated successfully.


- (2) 配置bankup-mfsmaster
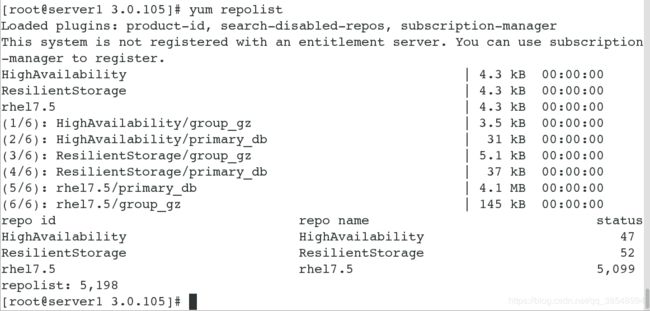
配置yum源

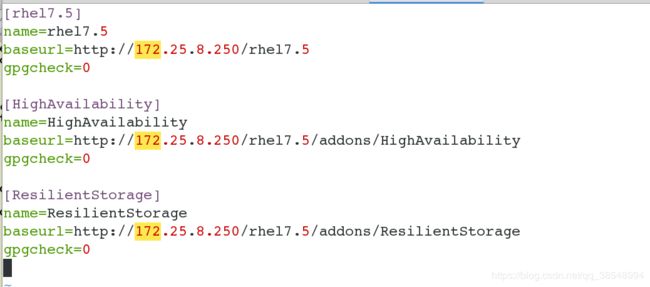


#安装pacemaker和corosync和pcs

开启服务

#创建用户
[root@server4 ~]# useradd hacluster #创建用户
[root@server4 ~]# id hacluster
[root@server4 ~]# passwd hacluster
Changing password for user hacluster. # 设置密码,主备必须相同
New password: Retype new password:
passwd: all authentication tokens updated successfully.
-
(4)在sevrer1上创建mfs集群并且启动
创建集群,并且进行认证

设置集群名称
[root@server1 ~]# pcs cluster setup --name mycluster server1 server4 #集群名称:mycluster ;server1和server4是加入mycluster集群中
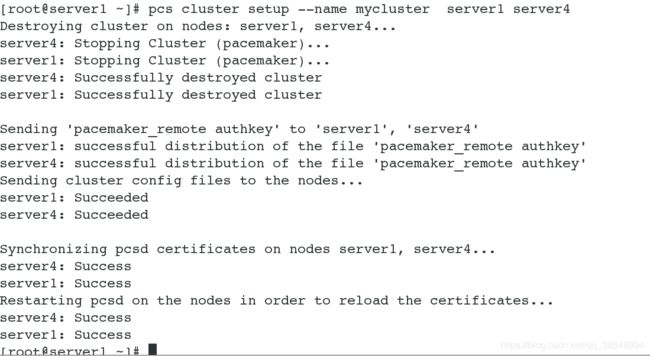
[root@base2 ~]# pcs status nodes # 查看集群状态,有报错,是因为有部分服务没有开启
Error: error running crm_mon, is pacemaker running?
[root@base2 ~]# pcs cluster start --all # 开启所有集群的服务
[root@base2 ~]# pcs status nodes # 再次查看节点信息
开启集群所有服务并设置成开机自启动


查看集群状态
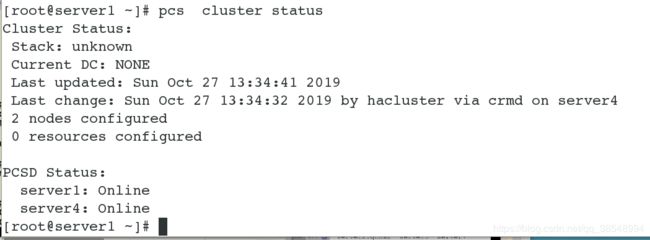
# 验证corosync是否正常,在status后面显示有no faults表示一切正常
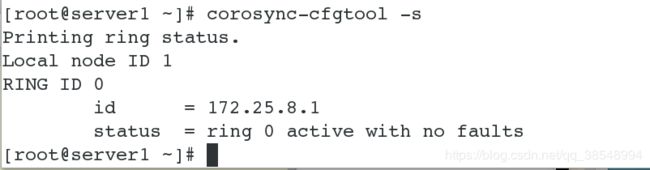
#查看corosync状态
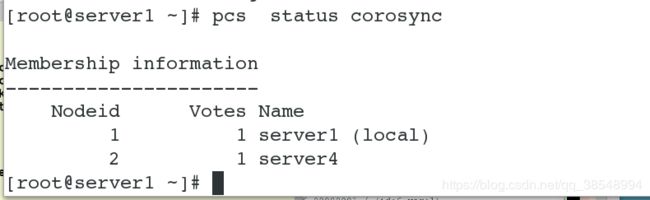
-
创建主备集群
#检查配置,有报错

#更改属性,禁用STONITH
![]()
#再次检查,没有报错


#查看创建资源帮助

#给集群里面创建资源vip以及验证高可用

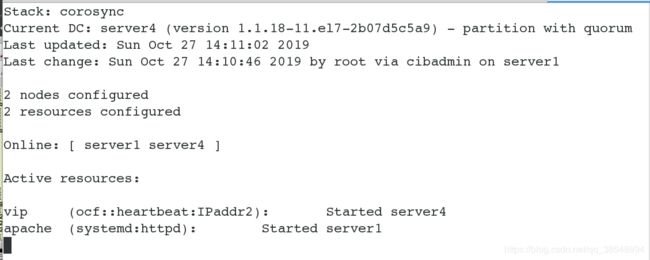
#查看集群的状态,可以看到目前server1和server4两个master节点都在线
![]()
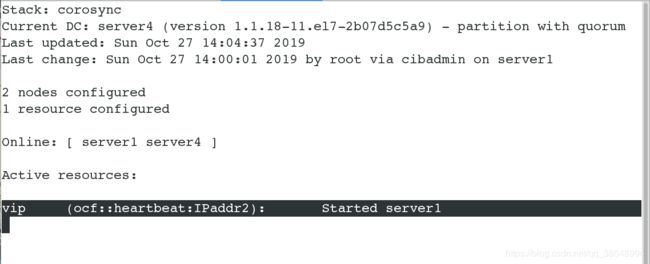
![]()
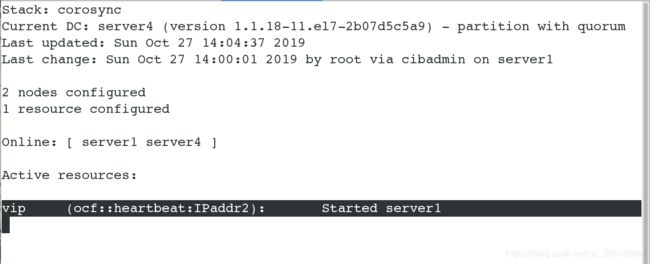
#查看创建成功,可以看出目前vip在server1上面
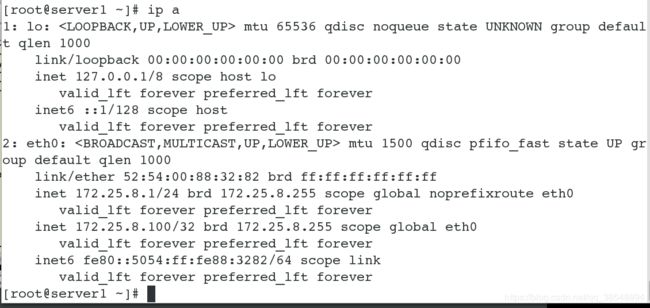
-
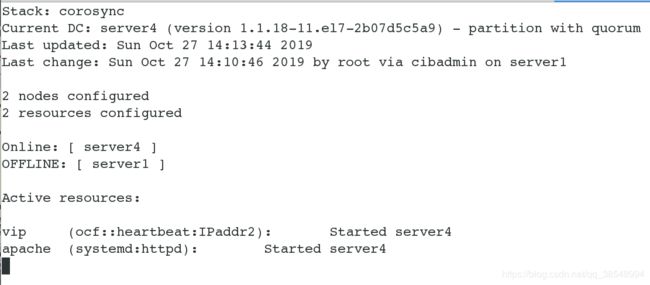
执行故障转移
关闭server1的集群服务,查看监控vip会自动漂移到server4上

![]()
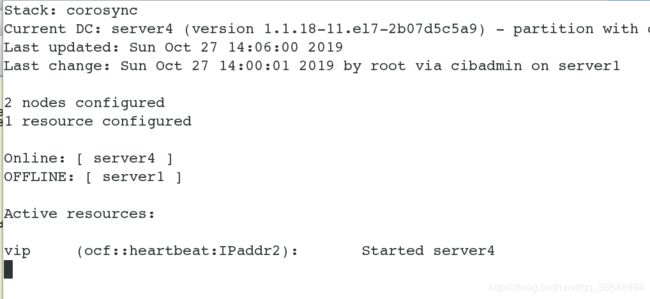
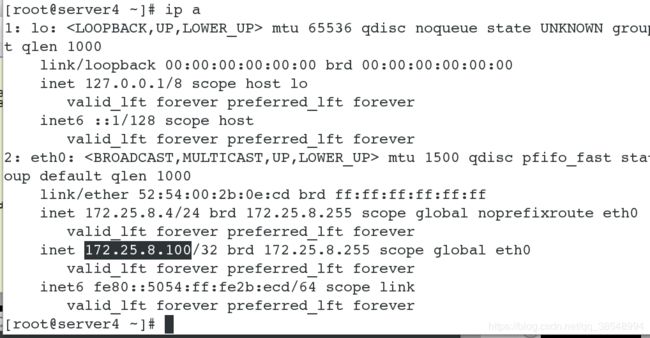
[root@server1 ~]# pcs cluster start server1 # 当master重新开启时
再次查看集群的状态
![]()
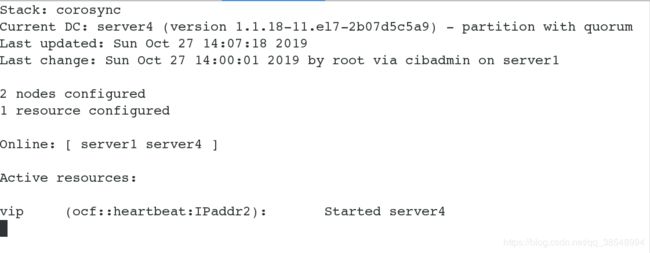
发现vip仍然在server4上面的,这可因为我们这个里面没有优先级的设定,所以重新开启服务,vip没有进行漂移;
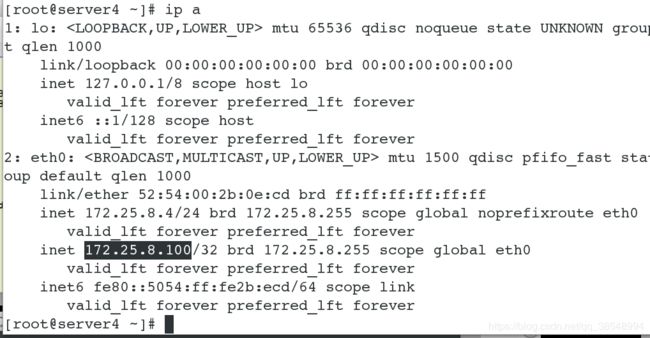
以上所有的实验我们实验了高可用,当master出现故障时,backup-master会立刻接替master的工作,保证客户端可以正常得到服务
[root@server1 ~]# pcs resource standards # 获取可用资源标准列表
[root@server1 ~]# pcs resource providers # 查看资源提供者的列表
[root@serve1 ~]# pcs resource agents ocf:heartbeat # 查看特定的可用资源代理

#2 给集群中添加apache服务
#给server1和server4安装httpd服务


#设置apache的发布页面的内容


#开启server1的集群服务,且给集群中创建apache资源

![]()
#关闭server1的集群,apache的集群直接漂移到server4上
![]()
#测试访问

#重新开启server1的集群,关闭server4的集群


#查看集群状态
![]()
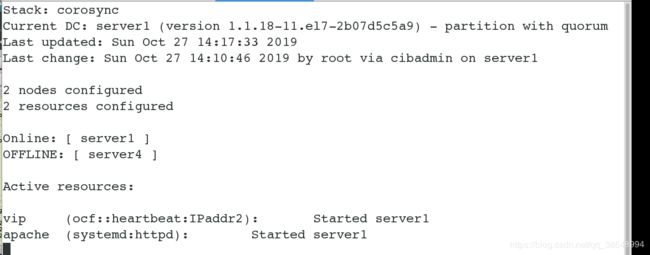
#vip也自动漂移到server1上
#测试访问

#3 存储共享(我们vip的方式来实现共享)
先恢复环境,写好解析
[root@foundation8 ~]# umount /mnt/mfs #若卸载的时候显示正忙,可以使用fuder -kvm /mnt/mfs将其进程杀死,再进行卸载
[root@foundation8 ~]# umount /mnt/mfsmeta
[root@foundation8 ~]# vim /etc/hosts
172.25.78.100 mfsmaster



对server1/2/3/4进行域名解析



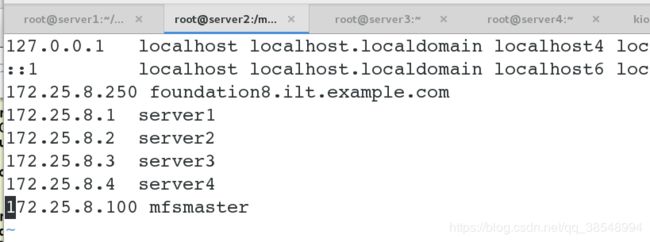

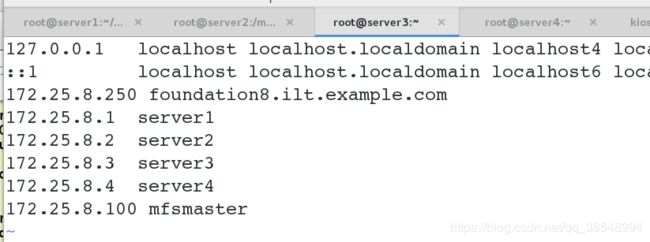

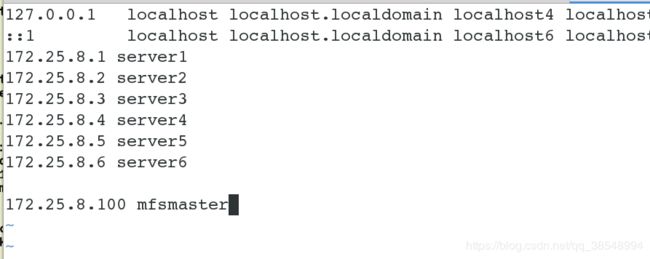
#对客户端进行域名解析
[root@foundation8 ~]# vim /etc/hosts
#关闭server1和server4上的mfsmaster服务,以及关闭server2和server3的mfschunkserver的服务,关闭这些服务,是因为系统自动启动mooser-master/moosefs-chunkserver服务
![]()
![]()

![]()
#給chunkserver(server2)和chunkserver(server3)分别添加一块磁盘
#server2是之前已经添加过的了
[root@server3 ~]# fdisk -l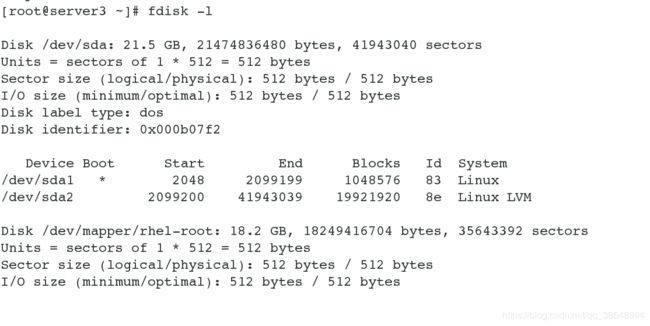
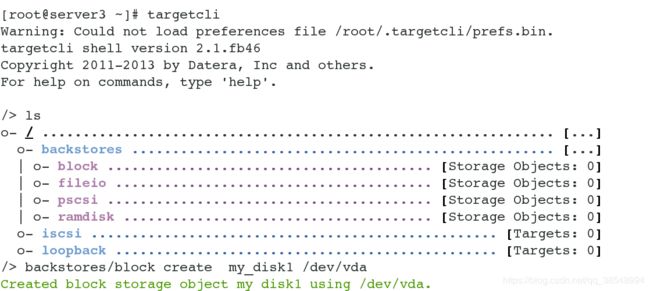
[root@server3 ~]# yum install -y targetcli # 安装远程块存储设备
[root@server3 ~]# systemctl start target # 开启服务
[root@server3 ~]# targetcli # 配置iSCSI服务
添加磁盘block
/> backstores/block create my_disk1 /dev/vda
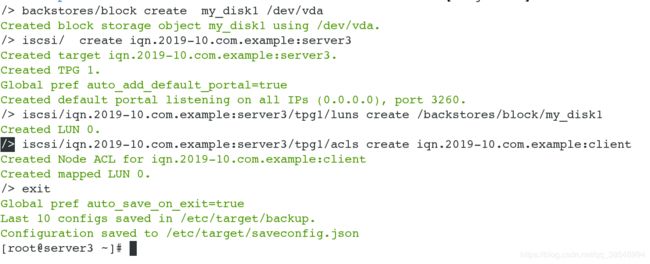
/> iscsi/ create iqn.2019-10.com.example:server3
port 3260:这个端口是默认的;
创建设备luns
/> iscsi/iqn.2019-10.com.example:server3/tpg1/luns create /backstores/block/my_disk1
创建客户端
/> iscsi/iqn.2019-10.com.example:server3/tpg1/acls create iqn.2019-10.com.example:client
/> exit

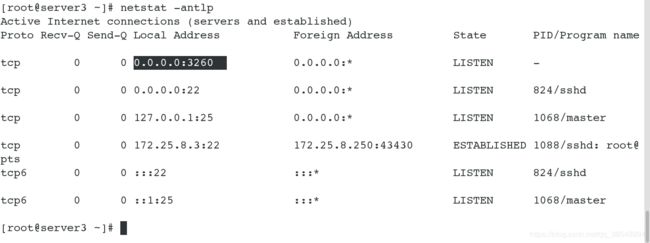
#查看端口,3260被打开
在master上安装iscsi客户端软件

#发现远程设备

#登陆

# 可以查看到远程共享出来的磁盘


[root@server1 ~]# fdisk /dev/sda # 使用共享磁盘,建立分区
Command (m for help): n
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-16777215, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-16777215, default 16777215):
Using default value 16777215
Command (m for help): p
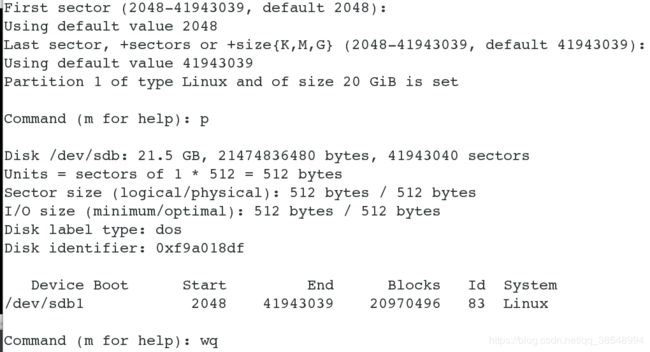

[root@server1 ~]# mkfs.xfs /dev/sda1 # 格式化分区
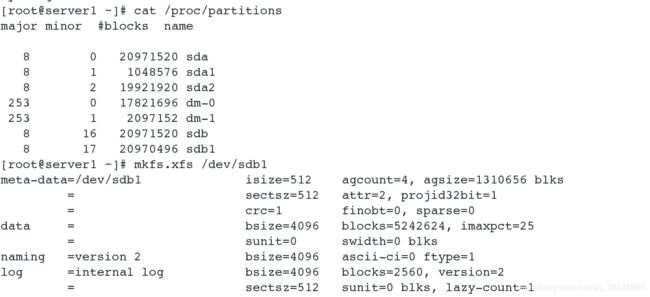
#将创建的分区进行挂载
![]()
[root@server1 ~]# cp -p /var/lib/mfs/* /mnt #带权限拷贝/var/lib/mfs的所有数据文件到/dev/sdb1上
[root@server1 ~]# chown mfs.mfs /mnt # 当目录属于mfs用户和组时,才能正常使用

![]()
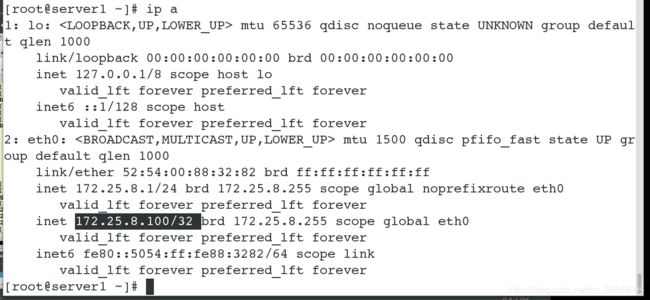
[root@server1 ~]# mount /dev/sda1 /var/lib/mfs/ # 使用分区,测试是否可以使用共享磁盘

[root@server1~]# systemctl start moosefs-master # 服务开启成功,就说明数据文件拷贝成功,共享磁盘可以正常使用,只是为了验证
![]()
![]()
- 配置backup-master,是之也可以使用共享磁盘
![]()
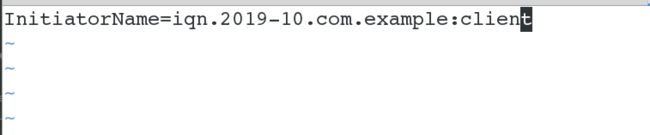

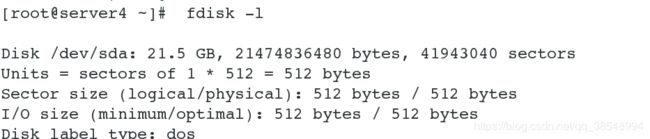
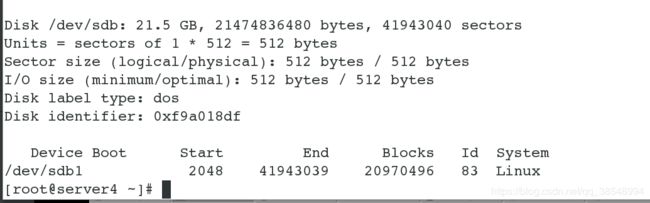
[root@server4 ~]# mount /dev/sda1 /var/lib/mfs/ # 此处使用的磁盘和master是同一块,因为master已经做过配置了,所以我们只需要使用即可,不用再次配置
[root@server4 ~]# systemctl start moosefs-master # 测试磁盘是否可以正常使用
[root@server4 ~]# systemctl stop moosefs-master

#查看server1上的mfs用户gid和groups是否保持一致,不一致就会出现问题,

#查看集群上的资源

#查看集群是否打开
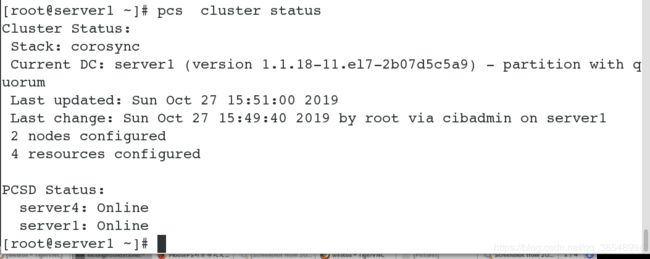
- 在master 上创建mfs文件系统
[root@server1 mfs]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sdb1 direcrtory=/var/lib/mfs fstype=xfs op monitor interval=30s #创建mfsdata文件系统,挂载磁盘分区,并且进行初始化,op monitor:运行监视器;interval:时间间隔
[root@server1 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min #创建mfsd系统,systemd:moosefs-master(服务名称) systemd的服务启动
[root@server1 ~]# pcs resource group add mfsgroup vip mfsdata mfsd #创建资源组,vip mfsdata mfsd:这三个是添加的服务名称,mfsgroup:组名
[root@server1 ~]# pcs cluster stop server1 # 当关闭master之后,master上的服务就会迁移到backup-master上
![]()
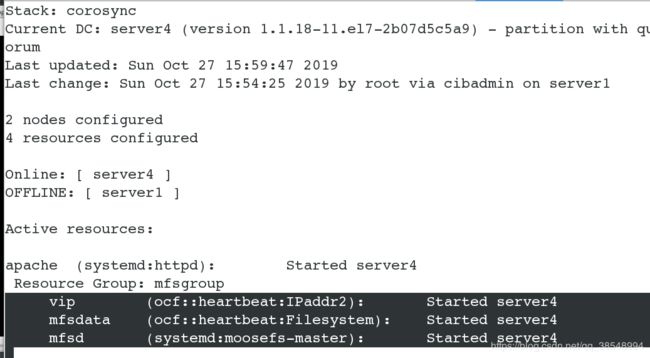
#查看监控,但是有个问题,就是apache,并没有在server1集群上
![]()
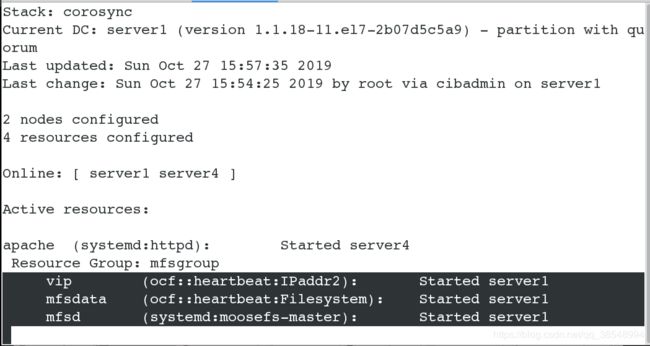
#关闭master的集群服务,全部漂移到server4上,这里时没有确定优先级的

![]()
现在存在一个问题:
如果当关闭sevrer1集群,打开server4集群后,vip会漂移到server4,但是当重新启动server1后,vip会自动飘回到server1,这是为什么?
解答: 正常情况下,当两个集群server1和server4,一个server1down 掉,转移到另一个server4上面后,如果第一个server1重启后,是不应该发生转移的,因为server4还没有down掉,如果随意转移的话,会发生资源的占用;
经过测试:
#1将其apache也添加到资源组mfsgroup后,就不会发生上述的问题,再次重启server1集群,资源组都是在server4上
#2如果apache和资源是分开的,那么就会出现上述的问题,我的理解是因为优先没有确定,所以导致的随意飘动
-
fence自动断电重启(也就是fence解决脑裂问题)
(1)先在客户端测试高可用
- 打开chunkserver
[root@server2 ~]# systemctl start moosefs-chunkserver
[root@server3 ~]# systemctl start moosefs-chunkserver
- 查看vip的位置
[root@server4 ~]# ip a - 开启master
[root@server1 ~]# pcs cluster start server1 - 在客户端进行分布式存储测试
[root@foundation8 ~]# mfsmount # 挂载,挂载失败 ,进行域名解析
[root@foundation8 ~]# vim /etc/hosts
172.25.8.100 mfsmaster
[root@foundation8 ~]# cd /mnt/mfs
[root@foundation8 mfs]# ls # 因为此目录下不是空的
dir1 dir2
[root@foundation8 mfs]# rm -fr * # 删除此目录下的所有文件
[root@foundation8 mfs]# ls
[root@foundation8 ~]# cd
[root@foundation8 ~]# mfsmount # 可以成功挂载
mfsmaster accepted connection with parameters: read-write,restricted_ip,admin ; root mapped to root:root
[root@foundation8 ~]# cd /mnt/mfs/dir1


在客户端上传大文件和关闭server4的集群要同时进行,要让server4集群先关闭,否则不会产生脑裂的现象
mfs默认一块50M
[root@foundation8 dir1]# dd if=/dev/zero of=file2 bs=1M count=2000 # 我们上传一份大文件
[root@server4 ~] # pcs cluster stop server4
[root@foundation78 dir1]# mfsfileinfo file2 # 我们查看到文件上传成功,并没有受到影响
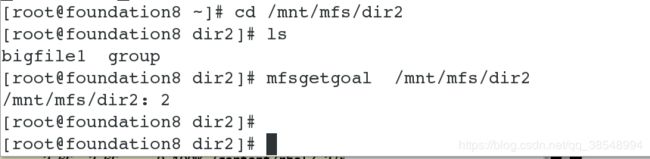
![]()


通过以上实验我们发现,当master挂掉之后,backup-master会立刻接替master的工作,保证客户端可以进行正常访问,但是,当master重新运行时,我们不能保证master是否会抢回自己的工作,从而导致master和backup-master同时修改同一份数据文件从而发生脑裂,此时fence就派上用场了
- 安装fence服务
[
[root@server1 ~]# yum install -y fence-virt
[root@server1~]# mkdir /etc/cluster
[root@server4 ~]# yum install -y fence-virt
[root@server4 ~]# mkdir /etc/cluster

![]()


#真机安装fence服务
[root@foundation8 kiosk]# yum install -y fence-virtd
[root@foundation8 kiosk]# yum install fence-virtd-libvirt -y
[root@foundation8 kiosk]# yum install fence-virtd-multicast -y
[root@foundation8 kiosk]# fence_virtd -c #初始化
Listener module [multicast]:
Multicast IP Address [225.0.0.12]:
Multicast IP Port [1229]:
Interface [virbr0]: br0 # 注意此处要修改接口,必须与本机一致
Key File [/etc/cluster/fence_xvm.key]:
Backend module [libvirt]:









[root@foundation8 kiosk]# mkdir /etc/cluster # 这是存放密钥的文件,需要自己手动建立
[root@foundation8 cluster]# ls
fence_xvm.key

[root@foundation78 cluster]# scp fence_xvm.key root@172.25.8.1:/etc/cluster/
[root@foundation78 cluster]# scp fence_xvm.key root@172.25.8.4:/etc/cluster/

[root@foundation8 cluster]# systemctl start fence_virtd
[root@foundation8 cluster]# netstat -anulp | grep 1229

[root@foundation8 ~]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1

[root@foundation8 cluster]# virsh list # 查看主机域名
[root@server1 ~]# cd /etc/cluster
[root@server1 cluster]# pcs stonith create vmfence fence_xvm pcmk_host_map="server1:haproxy1;server4:haproxy4" op monitor interval=1min #server1:haproxy1 主机名:虚拟机名称

[root@server1 cluster]# cd
[root@server1 ~]# pcs resource show #查看所有资源
[root@server1 ~]# pcs property set stonith-enabled=true
[root@server1 cluster]# crm_verify -L -V #进行认证

![]()

#设置资源默认粘性(防止资源回切)
#将其server4设置成优先级高于server1, server4变成master





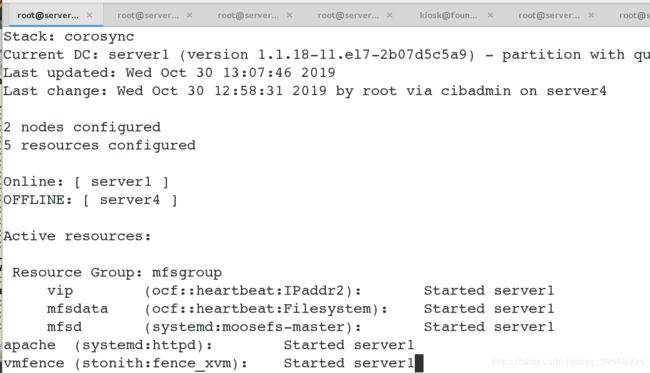

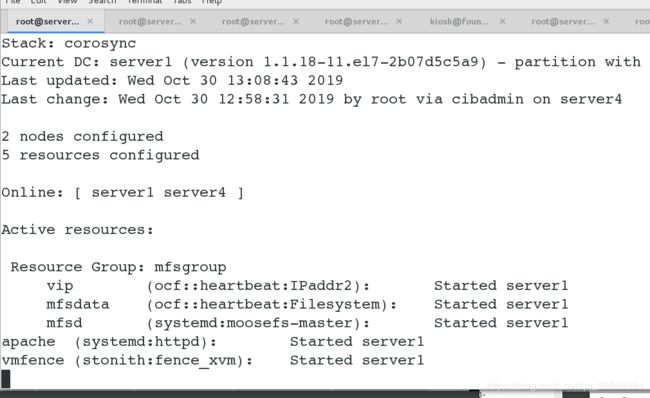
#你会发现以上的资源组和其他服务服务都没有发生随意的漂移
[root@server4 cluster]# fence_xvm -H server4(也可以是虚拟机的名称haproxy4) # 使server4断电重启
[root@server1 cluster]# crm_mon # 查看监控,server4上的服务迁移到serve1上了
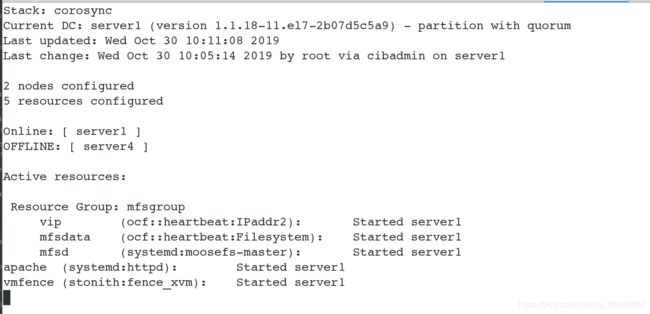
[root@server1 cluster]# echo c > /proc/sysrq-trigger # 模拟server1(master端)内核崩溃 ,查看监控,server4会立刻接管server1(master端)的所有服务
![]()
当server1断电重启成功后,不会抢占资源,保证不会脑裂;
- 查看监控:输入:crm_mon,发现server1(master)重启成功之后,并不会抢占资源,服务依旧在server4(backup-master端)正常运行,说明fence生效
小知识
pcs cluster cib:查看集群资源的详细信息
stonith_admin -I :当前支持fence的方式
fence_xvm -H node1(虚拟机名称):指定fence
pcs stonith fence server1(主机名称):