先说下 Selenium 是什么?一句话讲是一种自动化测试工具。它支持各种浏览器的驱动,包括 Chrome,Safari,Firefox ,PhantomJS,可以方便地实现Web界面的测试。
由于淘宝页面比较复杂,直接请求比较繁琐,所以使用selenium自动测试工具驱动浏览器完成工作。比如点击、下拉、输入等
目标:
使用Selenium模拟浏览器抓取淘宝商品美食信息,并存储到mongodb
创建webdriver对象
from selenium import webdriver
browser=webdriver.chrome()
得到总共需加载的页码
大多数现代web应用都使用了AJAX技术。当浏览器加载一个页面的时候,该页面内的元素可能在不用的时间间隔内进行加载。这使得元素定位变得比较困难:如果一个元素还没有出现在DOM中,定位函数将会抛出一个ElementNotVisibleException异常。使用waits等待可以解决这个问题。等待将会给定位一个元素或者对元素进行一些其他的操作提供一个缓冲的时间。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
browser=webdriver.Chrome() #创建webdriver对象
wait=WebDriverWait(browser, 10)
def search():
try:
browser.get('https://www.taobao.com')#打开请求的url
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))#等待搜索输入框加载完成
input.send_keys("美食")#输入框中输入“美食”
sumbit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:
return search
def main():
total=search()
total=int(re.compile('(\d+)').search(total).group(1))
print (total)
if __name__=='__main__':
main()
输出结果:
100

小结:
1.显性等待:WebDriverWait,配合该类的until()和until_not()方法进行的等待。它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
调用方法如下:
WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息)
until()方法参数:
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until 中参数method ,用expected_conditions类中的方法:
presence_of_element_located 判断某个元素是否被加到了dom树里
element_to_be_clickable 判断某个元素中是否可见并且是enable的,这样的话才叫clickable
text_to_be_present_in_element 判断某个元素中的text是否包含了预期的字符串
presence_of_all_elements_located: 判断是否至少有1个元素存在于dom树中。举个例子,如果页面上有n个元素的class都是'column-md-3',那么只要有1个元素存在,这个方法就返回True
- total=int(re.compile('(\d+)').search(total).group(1))
相当于
pattern=re.compile('(\d+)')
match=re.search(pattern,total)
total=int(match.group(1))
实现翻页
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
browser=webdriver.Chrome() #创建webdriver对象
wait=WebDriverWait(browser, 10)
def search():
try:
browser.get('https://www.taobao.com')#打开请求的url
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))#等待搜索输入框加载完成
input.send_keys("美食")#输入框中输入“美食”
sumbit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:
return search
def next_page(page_number):
try:
print('正在翻页', page_number)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
)
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))) #判断str(page_number)是否在文本中
except TimeoutException:
next_page()
def main():
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
next_page(i)
if __name__=='__main__':
main()
输出部分:
正在翻页2
正在翻页3
.......
(其实谷歌浏览器一直在自动进行者翻页)
获得每个页面的商品
####config.py
SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
#####spider.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
from config2 import *
#browser=webdriver.Chrome() #创建webdriver对象
#wait=WebDriverWait(browser, 10)
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)
wait = WebDriverWait(browser, 10)
browser.set_window_size(1400, 900)
def search():
try:
browser.get('https://www.taobao.com')#打开请求的url
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))#等待搜索输入框加载完成
input.send_keys("美食")#输入框中输入“美食”
sumbit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
get_products()
return total.text
except TimeoutException:
return search()
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html=browser.page_source
doc=pq(html)
items = doc('#mainsrp-itemlist .items .item').items()#items 方法返回对象列表
for item in items:
product={
'image':item.find('.pic .img').attr('src'),
'price':item.find('.price').text(),
'deal':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
def next_page(page_number):
try:
print('正在翻页', page_number)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
)
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))) #高亮
get_products()
except TimeoutException:
next_page(page_number)
def main():
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
next_page(i)
if __name__=='__main__':
main()
输出部分结果
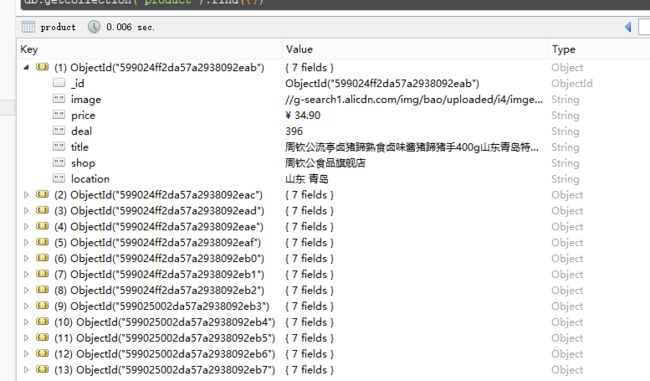
{'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i4/1089306067538397673/TB2OK6JxSFmpuFjSZFrXXayOXXa_!!0-saturn_solar.jpg_230x230.jpg', 'price': '¥ 34.90', 'deal': '396', 'title': '周钦公流亭卤猪蹄熟食卤味酱猪蹄猪手400g山东青岛特产卤猪脚包邮', 'shop': '周钦公食品旗舰店', 'location': '山东 青岛'}
{'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i4/628189716/TB1vysTSFXXXXbCXVXXXXXXXXXX_!!0-item_pic.jpg_230x230.jpg', 'price': '¥ 19.90', 'deal': '130625', 'title': '聚【百草味-夹心麻薯210gx3袋】零食小吃特产 美食 早餐食品糕点', 'shop': '百草味旗舰店', 'location': '浙江 杭州'}
{'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i1/TB1_VE5SXXXXXaAaXXXXXXXXXXX_!!0-item_pic.jpg_230x230.jpg', 'price': '¥ 17.90', 'deal': '47166', 'title': '良品铺子肉松饼传统糕点 点心 零食早餐 美食 特产小吃休闲食品散装', 'shop': '良品铺子旗舰店', 'location': '湖北 武汉'}
{'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i2/32799385/TB2IK0qal0kpuFjy1XaXXaFkVXa_!!32799385.jpg_230x230.jpg', 'price': '¥ 85.00', 'deal': '1', 'title': '包邮台湾进口 新鲜 美食 〖御品轩〗原味太阳饼 6枚', 'shop': 'goodie123', 'location': '上海'}
一开始用 Chrome 浏览器为方便查看测试效果,但为了不让一直浏览器界面出现就改回了PhantomJS。
存储到mongodb
#####config.py
MONGO_URL = 'localhost'
MONGO_DB = 'taobao'
MONGO_TABLE = 'product'
SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']
####spider.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
from config2 import *
import pymongo
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
#browser=webdriver.Chrome() #创建webdriver对象
#wait=WebDriverWait(browser, 10)
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)
wait = WebDriverWait(browser, 10)
browser.set_window_size(1400, 900)
def search():
try:
browser.get('https://www.taobao.com')#打开请求的url
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#q')))#等待搜索输入框加载完成
input.send_keys("美食")#输入框中输入“美食”
sumbit=wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
sumbit.click()
total=wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
get_products()
return total.text
except TimeoutException:
return search()
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html=browser.page_source
doc=pq(html)
items = doc('#mainsrp-itemlist .items .item').items()#items 方法返回对象列表
for item in items:
product={
'image':item.find('.pic .img').attr('src'),
'price':item.find('.price').text(),
'deal':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
save_to_mongo(product)
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到MONGODB成功', result)
except Exception:
print('存储到MONGODB失败', result)
def next_page(page_number):
try:
print('正在翻页', page_number)
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
)
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")))
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number))) #高亮
get_products()
except TimeoutException:
next_page(page_number)
def main():
try:
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2, total + 1):
next_page(i)
except Exception:
print('出错啦')
finally:
browser.close()
if __name__=='__main__':
main()
输出的部分结果:
{'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i4/1089306067538397673/TB2OK6JxSFmpuFjSZFrXXayOXXa_!!0-saturn_solar.jpg_230x230.jpg', 'price': '¥ 34.90', 'deal': '396', 'title': '周钦公流亭卤猪蹄熟食卤味酱猪蹄猪手400g山东青岛特产卤猪脚包邮', 'shop': '周钦公食品旗舰店', 'location': '山东 青岛'}
存储到MONGODB成功 {'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i4/1089306067538397673/TB2OK6JxSFmpuFjSZFrXXayOXXa_!!0-saturn_solar.jpg_230x230.jpg', 'price': '¥ 34.90', 'deal': '396', 'title': '周钦公流亭卤猪蹄熟食卤味酱猪蹄猪手400g山东青岛特产卤猪脚包邮', 'shop': '周钦公食品旗舰店', 'location': '山东 青岛', '_id': ObjectId('5990208e2da57a05b4945f23')}
{'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i4/628189716/TB1vysTSFXXXXbCXVXXXXXXXXXX_!!0-item_pic.jpg_230x230.jpg', 'price': '¥ 19.90', 'deal': '130625', 'title': '聚【百草味-夹心麻薯210gx3袋】零食小吃特产 美食 早餐食品糕点', 'shop': '百草味旗舰店', 'location': '浙江 杭州'}
存储到MONGODB成功 {'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i4/628189716/TB1vysTSFXXXXbCXVXXXXXXXXXX_!!0-item_pic.jpg_230x230.jpg', 'price': '¥ 19.90', 'deal': '130625', 'title': '聚【百草味-夹心麻薯210gx3袋】零食小吃特产 美食 早餐食品糕点', 'shop': '百草味旗舰店', 'location': '浙江 杭州', '_id': ObjectId('5990208e2da57a05b4945f24')}
{'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i1/TB1_VE5SXXXXXaAaXXXXXXXXXXX_!!0-item_pic.jpg_230x230.jpg', 'price': '¥ 17.90', 'deal': '47166', 'title': '良品铺子肉松饼传统糕点 点心 零食早餐 美食 特产小吃休闲食品散装', 'shop': '良品铺子旗舰店', 'location': '湖北 武汉'}
存储到MONGODB成功 {'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i1/TB1_VE5SXXXXXaAaXXXXXXXXXXX_!!0-item_pic.jpg_230x230.jpg', 'price': '¥ 17.90', 'deal': '47166', 'title': '良品铺子肉松饼传统糕点 点心 零食早餐 美食 特产小吃休闲食品散装', 'shop': '良品铺子旗舰店', 'location': '湖北 武汉', '_id': ObjectId('5990208e2da57a05b4945f25')}
{'image': '//g-search3.alicdn.com/img/bao/uploaded/i4/i2/32799385/TB2IK0qal0kpuFjy1XaXXaFkVXa_!!32799385.jpg_230x230.jpg', 'price': '¥ 85.00', 'deal': '1', 'title': '包邮台湾进口 新鲜 美食 〖御品轩〗原味太阳饼 6枚', 'shop': 'goodie123', 'location': '上海'}
MongoDB的一些安装参考
- MongoDB数据库安装图解
- MongoDB设置环境变量与设置成Windows服务
- MongoDB服务无法启动-10061由于目标计算机积极拒绝,无法连接