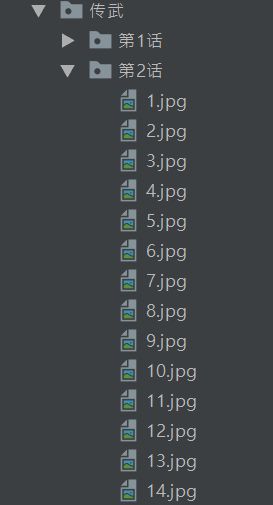
python爬虫爬取漫画(仅供学习)
项目名: crawl_chuanwu
爬取链接:https://www.manhuadui.com/manhua/chuanwu/
声明:本项目无任何盈利目的,仅供学习使用,也不会对网站运行造成负担。
1. 打开链接后,我们会看到这样的图片
3. 每个章节都是一个link,我们需要获得这些链接,直接右击检查网页源代码,我们能找到每个章节的url,很幸运,这个不是动态网页(ajax:异步 JavaScript 和 XML,一种用于创建快速动态网页的技术),所以可以用request+pyquery直接进行爬取。代码部分getDir.py
import requests
from pyquery import PyQuery as pq
import pickle
def get_html(url, code="utf-8"):
try:
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def get_dir(html):
doc = pq(html)
dirs = doc("div #chapter-list-1 a")
print((type(dirs.items())))
lst = []
for dir in dirs.items():
lst.append(dir.attr('href'))
with open("dir_lst.pickle", "wb") as f:
pickle.dump(lst, f)
f.close()
def main():
url = "https://www.manhuadui.com/manhua/chuanwu/"
html = get_html(url)
get_dir(html)
if __name__ == "__main__":
main()
我将下载下来的url通过pickle技术进行文件保存,保存目录为dir_lst.pickle,为后面下载漫画使用
接下来就是直接下载漫画了,首先进入第一话,同样进行右击查看网页源代码,发现找不着漫画图片的url,这时,我们对漫画图片进行右击,检查,很容易发现图片的url,为啥网页源代码没有呢,原因就是这里采用了ajax技术,作为一个新手,我一时难以下手,后来网上查了一下,发现selenium可以解决这种问题。
selenium是什么呢?
Selenium是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,
就像真正的用户在操作一样。支持的浏览器包括IE(7、8、9)、Mozilla Firefox、Mozilla Suite等。
这个工具的主要功能包括:测试与浏览器的兼容性、测试系统功能,
它是ThoughtWorks专门为Web应用程序编写的一个验收测试工具。详细代码的使用方法可以看相应官网或其他大神博客。
以下是爬取前三章漫画的代码 crawl_comic.py
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.wait import WebDriverWait
import requests
import re
import pickle
import os
"""
本例说明,这是一个爬取漫画堆里的一部叫做传武的漫画,因为selenium模仿浏览器,爬取速度很慢,
所以我只爬取了前3话,依旧很慢,所以仅供初学者进行参考
"""
# 该方法是得到每一话漫画的页数,并返回
def get_page_num(url, driver):
driver.get(url)
try:
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CLASS_NAME, "img_info"))
)
except TimeoutException:
print(u'加载页面失败')
html = driver.page_source
doc = pq(html)
page_num = doc("#images .img_info").text()[-3:-1]
return page_num
# 用yield生成器得到一个章节漫画图片的url
def pic_urls(page_num, url, driver):
for i in range(1, int(page_num)+1):
new_url = url+"?p="+str(i)
driver.get(new_url)
try:
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CLASS_NAME, "img_info"))
)
except TimeoutException:
print(u'加载页面失败')
html = driver.page_source
doc = pq(html)
photo_url = doc("#images img ").attr('src')
yield photo_url
# 对每一章节所有漫画图片的url进行爬取并保存在文件中
def download_photos(url, driver):
# url = "https://www.manhuadui.com/manhua/chuanwu/224176.html"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
page_num = get_page_num(url, driver)
chapter = re.findall(r"\d{6}", url)[0]
chapter = int(chapter) - 224175
i = 1
for pic_url in pic_urls(page_num, url, driver):
if not os.path.exists("传武/第{0}话/".format(chapter)):
os.makedirs("传武/第{0}话/".format(chapter))
with open("传武/第{0}话/{1}.jpg".format(chapter, i), "wb") as f:
print("\r正在下载传武/第{0}话/{1}.jpg".format(chapter, i), end="")
i += 1
content = requests.get(pic_url, headers=headers).content
f.write(content)
f.close()
# 主函数,前面的方法是爬取一个章节的所有漫画,在这里我们通过更改url得到其它章节的漫画
# 由于这里是顺序结构,爬取速度相对较慢,底子好的人可以用异步方式进行爬取
def main():
driver = webdriver.Chrome()
with open("dir_lst.pickle", "rb") as f:
lst = pickle.load(f)
# 截取前三章节的url
dir = lst[0:3]
url_a = "https://www.manhuadui.com"
for _ in dir:
url = url_a + _
download_photos(url, driver)
if __name__ == "__main__":
main()
成果: