R语言绘制词云图(中文&英文)
词云图是非常有趣的一种图形,可以很直观的展示出数据频率的关系,下面将分别介绍基于R语言的中文词云图及英文词云图的绘制。
但是不论是中文词云图还是英文词云图,都是基于R中的wordcloud包和wordcloud2包,其实总的来说,绘制词云图的思路很清晰,主要就是两步:
step1:计算词向量和词频向量;
step2:生成词云图.
所以如果说难,主要是因为计算词向量和词频向量这里会存在一些问题,函数的调用倒是没有多大问题。
词向量就是样本中所包含的词所组成的一个向量,词频向量是词所对应的频数组成的向量。
中文词云图
对于中文的词云图绘制,大家一致觉得使用R的jiebaR包非常不错,而且看到很多博客上也是使用jiebaR包的。
ok,一起来攻克step1这个棘手的问题吧!
首先详细介绍jiebaR中的segment()函数,通过segment()函数的help文档,我们可以看到,其名字为:Chinese text segmentation function,即:中文文本分词函数。其语法为:segment(code, jiebar, mod = NULL),下面详细介绍该函数的参数。
code:一个中文句子或者是一个文本文档的路径;
jiebar:翻译为jieba工人,其实就是用来分词的工具。这是一个非常重要的参数,但是别忘了还有一个参数哦~
mod:更改默认结果类型,其实就是对jiebar的补充了,我们不妨根据examples试验一下!
library(jiebaR)
library(jiebaRD)
a <- "我是中国人,我爱我的祖国。"
engine1 <- worker()
engine2 <- worker("hmm")
segment(a,engine1)
segment(a,engine2)
我们上面分别用来两个worker,来看看结果吧!

显然,使用hmm参数worker更合理一点,其他worker详见help。
到此为止,我想我们已经完成了千里长征的第一步:分词(即得到了词向量),接下来需要做的事就是计算词频了,通常用freq(),看这个名字就知道它的作用了,这里将不做过多赘述,我们继续用上面的例子来试验,如下
b <- segment(a,engine2)
word <- freq(b)
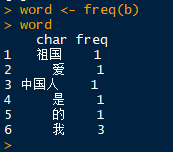
非常不错!
好了,我们已经彻底解决了这个难题,接下来就是画图了!
wordcloud()函数,名字:Plot a word cloud,唉,名字总是这么直接,都不用解释的!
语法:wordcloud(words,freq,scale=c(4,.5),min.freq=3,max.words=Inf,
random.order=TRUE, random.color=FALSE, rot.per=.1,
colors=“black”,ordered.colors=FALSE,use.r.layout=FALSE,
fixed.asp=TRUE, …)
参数简直直白的不需要解释,真是好包,看看是哪路神仙开发的吧,Ian Fellows,名字就看着很舒服,怪不得开发的包也这么好用~~
继续用上面的例子吧!
library(wordcloud)
library(RColorBrewer)
wordcloud(word$char,word$freq,min.freq = 0)

这里我设置的最小频数是0,所以把所有的都绘制上去了,对,毕竟词就这么少,ok,中文分词到此结束!算了,都到这里了,还是画的再好看一点吧!
为了好看,当然是颜色形状什么都要来一点了~形状可多了,什么星星啊,月亮啊,苹果啊!
library(wordcloud2)
wordcloud2(word,color = "random-light", backgroundColor = "grey",shape = 'apple')

不得不说,确实好看了点!
英文词云图
不得不提,segment()函数人家是对中文分词的,名字里已经写得很清楚了,不不不,我真是,忽然想到,刚刚看他的example的时候,他就是拿的英文句子给我举例子的,试了一下果不其然,那就继续用它吧!
aa <- "my name is zxn and i love my country,i love my people"
bb <- segment(aa,engine2)
wordd <- freq(bb)
wordcloud2(wordd,color = "random-light", backgroundColor = "grey",shape = 'star')

ok!上面就是基本的用R绘制中英文词云图的知识点了!