【目标检测】【2】One-stage目标检测算法的论文阅读笔记与资料整理
把之前本地的一些论文阅读笔记和资料汇总搬上来
之前写过的相关博客:
【目标检测】【1】《SSD- Single Shot MultiBox Detector》SSD目标检测器详解
【yolov3】【2】yolov3-spp结构详解与源码解析(pytorch)
文章目录
- 目标检测
- YOLO系列与SSD对比
- SSD
- 《SSD: Single Shot MultiBox Detector》
- YOLO
- 【YOLOv1】《You only look once:Unified, Real-Time Object Detection》
- 【YOLOv2】《YOLO9000: Better, Faster, Stronger》
- 【YOLOv3】《YOLOv3: An Incremental Improvement》
- anchor-free
- 【Stacked Hourglass】《Stacked Hourglass Networks for Human Pose Estimation》
- 【cornernet左上+右下】《CornerNet: Detecting Objects as Paired Keypoints》
- 【centernet中心】《Objects as Points》
目标检测
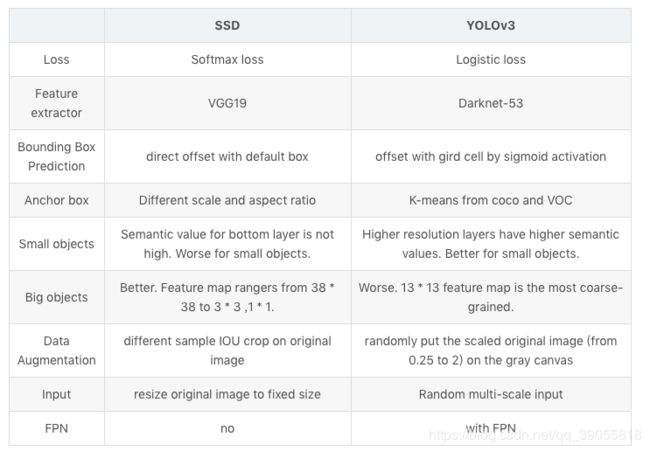
YOLO系列与SSD对比
| YOLOv1 | SSD | YOLOv2 | YOLOv3 | |
|---|---|---|---|---|
| anchor box | 没有anchor box | 有default box | 有anchor box(k-means,用σ限制在0~1以改进稳定性) | 同yolo2,k=9,均分到三个feature map |
| 结构 | 仿照googlenet,后接全连接 | 基于VGG16,后接3 * 3卷积核 | darknet-19,没有fc | darknet-53, 没有fc和pooling,有resblock |
| 使用的feature map | 最后一层feature map | 使用了6层feature map,直接在每层map上预测 | 使用了最后2层feature map;passthrough结构不损失信息,在深度上拼接后预测 | 3个不同尺度的feature map,后面的上采样和前面的concat(FPN) |
| 预测框的数目 | 预测7x7x2个框 | 预测8732个框 | 预测13x13x5/9个框 | 预测sxsx3个框(s=13,26,52) |
| 预测的内容 | 每个box预测objectness和位置,每个grid预测conditional class | 每个box预测confidence和位置 | 每个box预测objectness和conditional class和位置 | 同yolo2 |
YOLOv1与SSD
| YOLOv1 | SSD |
|---|---|
| 没有anchor box | 有default box |
| 全连接 | 3 * 3卷积核 |
| 最后一层feature map | 使用了多层feature map |
| 仅为一个cell预测一个类别 | 预测8732个类别 |
SSD
《SSD: Single Shot MultiBox Detector》
论文阅读:SSD: Single Shot MultiBox Detector
SSD笔记(引用↓两者)
目标检测|SSD原理与实现(较清晰)
CNN目标检测(三):SSD详解(详细计算)
SSD论文阅读(Wei Liu——【ECCV2016】SSD Single Shot MultiBox Detector)(原作ppt)
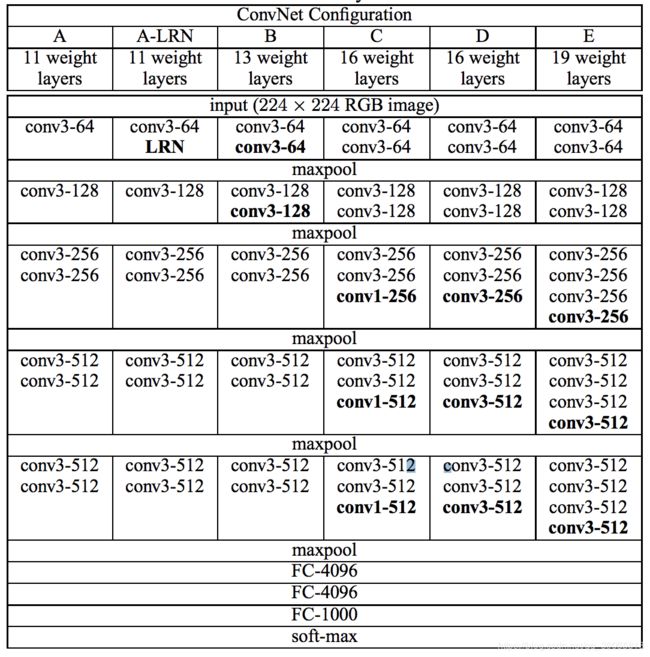
VGG16 & SSD网络结构
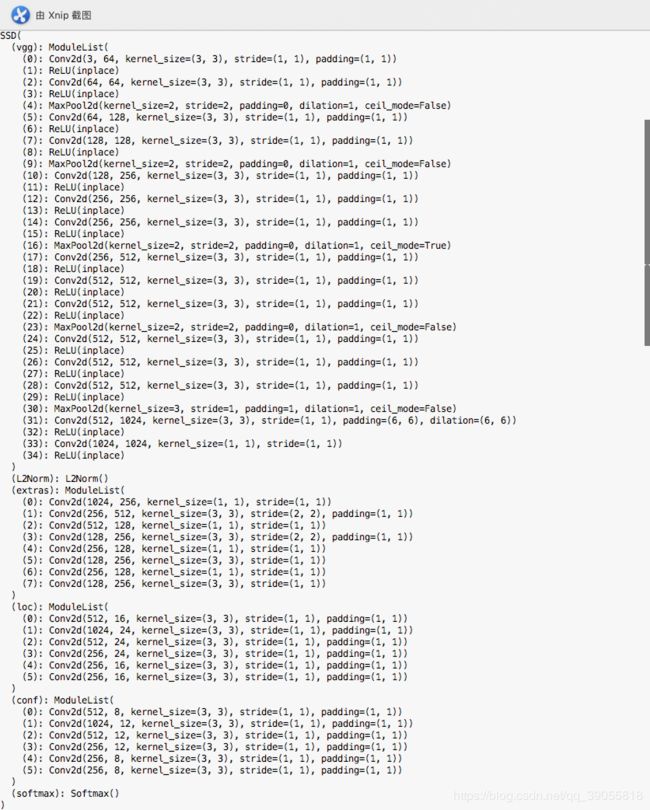
跑了一下SSD的代码,SSD网络结构(此例为二分类(包括背景)):
如何理解空洞卷积(dilated convolution)?
Standard Convolution with a 3 x 3 kernel (and padding)↓
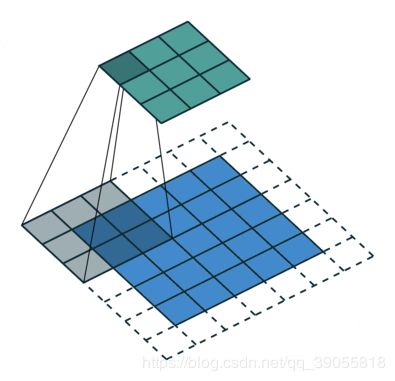
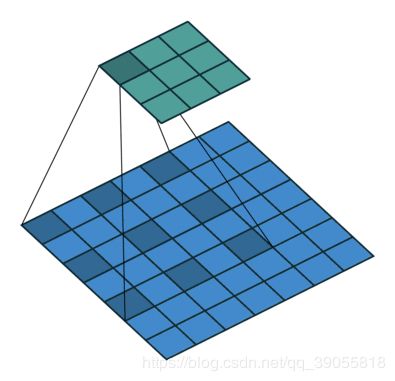
计算:
深度学习基础-卷积、池化、转置卷积、空洞卷积辨析

推导:看作是将卷积核扩大,即,k’=(k-1) * d + 1
SSD 的网络结构

SSD 的VGG16(D)以及extras
SSD的conf和loc层
- 以Conv4_3的输出为例,此时feature map为38x38x 512,论文中的“Classifier”为3x3x(4x(Classes +4)),相当于深度为4x(Classes+4)的3x3卷积核。
将其拆开:
- 对卷积核而言,conf部分为3x3x(4xClasses),loc部分为3x3x(4x4)(论文中的(c+4)k个卷积核即为这里的(Classes+4)x4);
- 对输出的feature map而言,conf部分为38x38x(4xClasses),loc部分为38x38x(4x4)(论文中的(c+4)kmn,m,n均为38)
- 对所有的6个输出层:
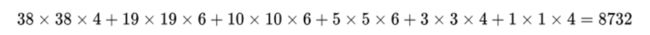
网络训练
- Matching strategy匹配策略

不仅最近的得高分,其他相近的也得高分 - Training objective训练目标
深度学习: smooth L1 loss 计算
对所有被匹配过的N个default box计算loss(包括分类和回归误差)取平均
Lloc:只针对匹配了的dbox(default box),将gt四个坐标归一化后与预测值作比较,计算smoothL1 loss
Lconf:针对所有dbox,已经匹配过的计算对应的类别,没有匹配过的按照类别0(即背景),计算softmax loss
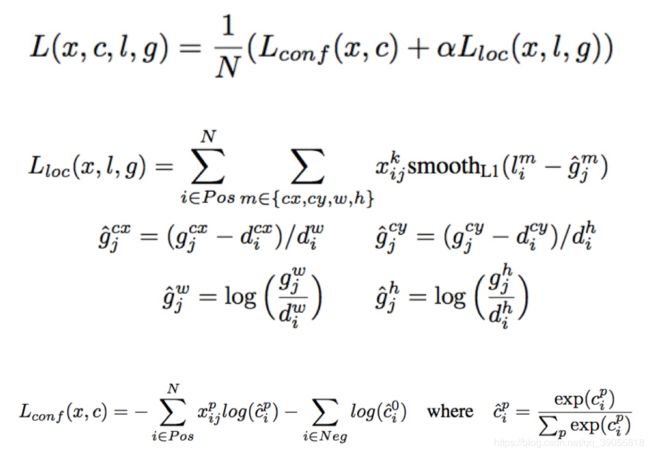
- Choosing scales and aspect ratios for default boxes 尺度和横纵比的选择
本部分解决不同深度的feature map如何对应不同尺度的目标,即每个feature map的default box的scale

SSD的default box的计算与理解
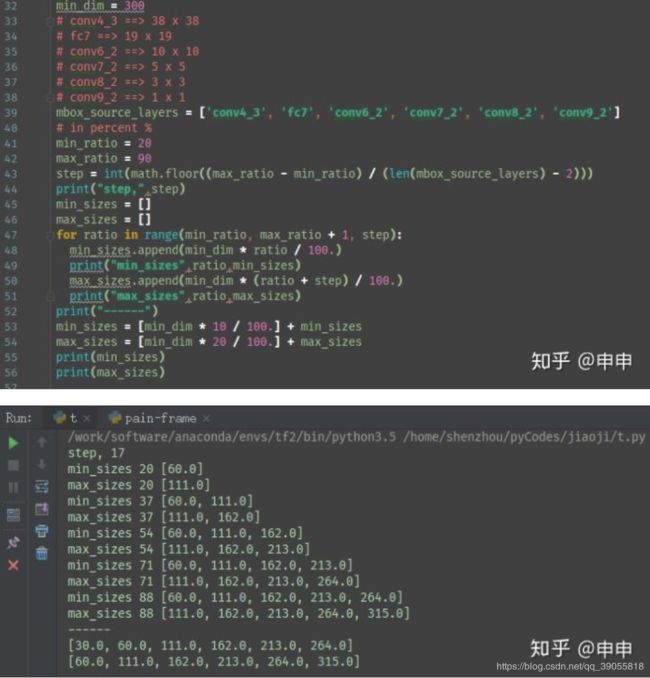
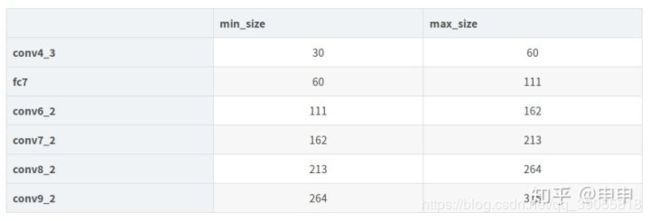
简单来讲,对于第一层feature给定了minsizes和max_size,剩余五层之间的间隔为step。step其实指定的是到feature对应到原图的一种计算中间数。min_ratio和max_ratio是原图的尺寸比例,可以理想地理解为,(对于300x300的SSD)最小的default box面积为0.2* 300* 300,最大为0.9* 300* 300。因此,对于检测较小像素比例的物体时,可以改变min_ratio和max_ratio的大小来对网络进行调整,比如调整为0.1到0.5,那么这样的网络适用于所有检测的物体的面积都不大于整副图的一半儿。当然,如果能调整对应的每层的feature map的大小效果更好。
- Hard negative mining 难分样本挖掘
最难分的一部分负样本,3:1 - Data augmentation 数据增广
sample patch,horizontally flip,others
YOLO
【YOLOv1】《You only look once:Unified, Real-Time Object Detection》
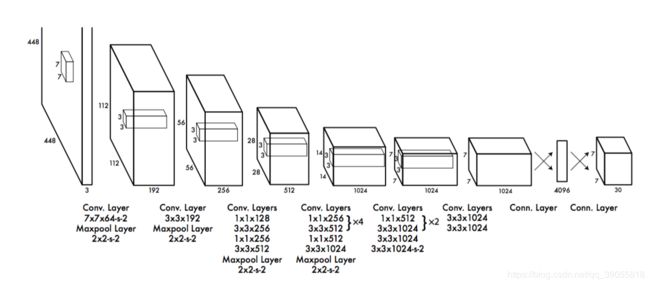
YOLO end-to-end
构架
-
理解↓图和B * 5 + C
对于每个cell,预测所有class的概率C(即图中彩色的图),同时,预测B个框(包括其位置以及其中含有object的概率)
-
借鉴了Googlenet的结构
loss function

YOLO 损失函数 loss
【YOLOv2】《YOLO9000: Better, Faster, Stronger》
<机器爱学习>YOLOv2 / YOLO9000 深入理解
Better
-
Batch Normalization
-
High Resolution Classifier
YOLO2在采用 224* 224 图像进行分类模型预训练后,再采用 448* 448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448* 448 的分辨率。然后再使用 448* 448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。
- Convolutional With Anchor Boxes
- 采用先验框(anchor)。作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置
- 移除了全连接层。另外去掉了一个池化层,使网络卷积层输出具有更高的分辨率
recall上升
-
Dimension Clusters
k-means聚类,k越高Avg IOU越高,但为了在模型复杂度和recall中trade off,选择k=5
距离度量:
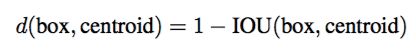
-
Direct location prediction
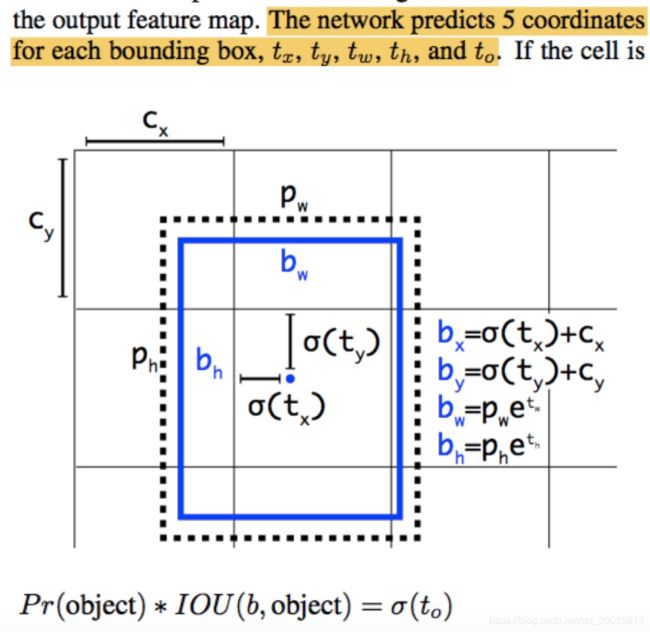
Since we constrain the location prediction the parametrization is easier to learn, making the network more stable
由于σ函数将tx,ty约束在(0,1)范围内,所以根据上面的计算公式,预测边框的蓝色中心点被约束在蓝色背景的网格内。约束边框位置使得模型更容易学习,且预测更为稳定。
-
Fine-Grained Features(passthrough)
将次深层的26x26x512的拆成13x13x2048,和最深层的13x13的map在通道上叠加,称作passthrough -
Multi-Scale Training
在多个尺度上训练
Faster
许多检测框架都基于VGG16
YOLOv1仿照googlenet,比VGG16更快但精度下降
YOLOv2使用Darknet-19↓
看一下passthrough层。图中第25层route 16,意思是来自16层的output,即26* 26* 512,这是passthrough层的来源(细粒度特征)。第26层1* 1卷积降低通道数,从512降低到64(这一点论文在讨论passthrough的时候没有提到),输出26* 26* 64。第27层进行拆分(passthrough层)操作,1拆4分成13* 13* 256。第28层叠加27层和24层的输出,得到13* 13* 1280。后面再经过3* 3卷积和1* 1卷积,最后输出13* 13* 125。
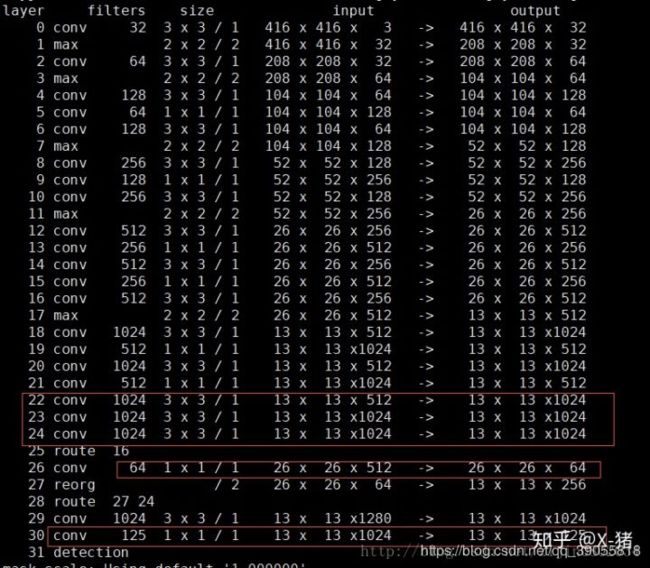
- 个人理解:在每个maxpool之间有三层(或五层)卷积,其中第一层3x3将深度加深一倍,第二层1x1将深度降低一倍,第三层3x3将深度加深一倍
Stronger
YOLO9000: BETTER, FASTER, STRONGER 论文阅读
作者提出一种在分类数据和目标检测数据下联合训练的机制。使用目标检测标签的图片来学习检测特定信息,如边界框坐标预测和objectness以及如何对常见对象进行分类。使用仅有分类标签的图片来扩展其检测的类别数量。
训练时使用混合的detection和classification数据集。当网络遇到目标检测标签的图片时,用完整的YOLOv2 loss funcion来进行back propagation。当遇到类别标签的图片时,仅对整个结构中分类的loss function进行反向传播。
【YOLOv3】《YOLOv3: An Incremental Improvement》
yolo系列之yolo v3【深度解析】
YOLOv3 Loss构建详解
重磅!YOLOv3最全复现代码合集(含TensorFlow/PyTorch和Keras等)
anchor-free
【Stacked Hourglass】《Stacked Hourglass Networks for Human Pose Estimation》
residual模块组成一阶hourglass,多阶hourglass嵌套形成整个hourglass结构,多个hourglass堆叠形成整个stacked hourglass。引入的Intermediate Supervision将中间层也加入loss,但cornernet中放弃了这种结构。
【人体姿态】Stacked Hourglass算法详解
姿态估计: Hourglass 网络
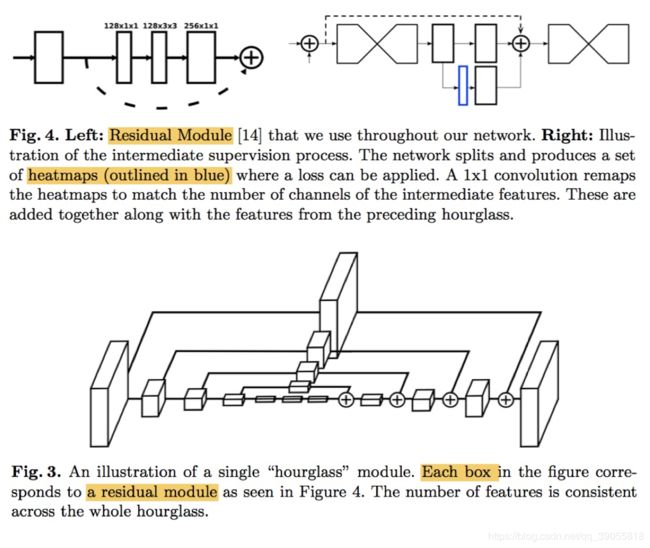
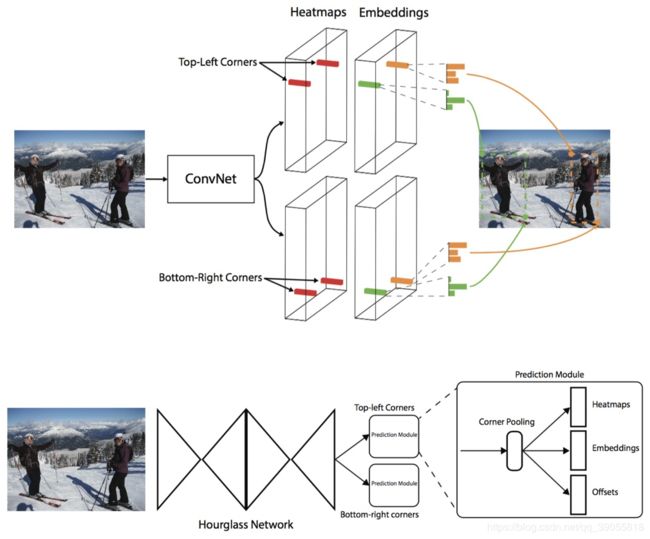
【cornernet左上+右下】《CornerNet: Detecting Objects as Paired Keypoints》
使用hourglass网络(沙漏)预测heatmap,offset(下采样造成的偏移),以及embedding(左上与右下匹配)。文章还相对应地提出了corner pooling。
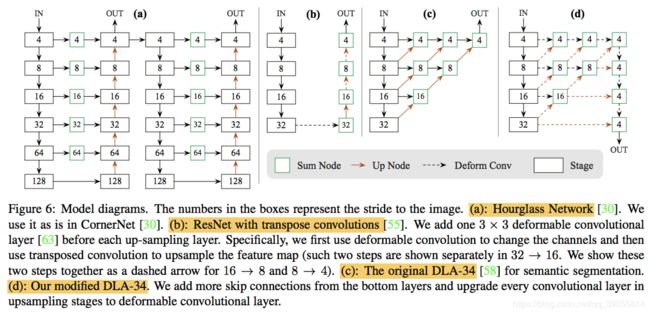
【centernet中心】《Objects as Points》
输出和原图同样大小的c+2(offset)+2(w/h)层map。backbone有几种,从resnet到DLA再到hourglass,速度越来越慢,精度越来越高。