基于情感词典进行情感态度分析
情感分析是指挖掘文本表达的观点,识别主体对某客体的评价是褒还是贬,褒贬根据进态度行倾向性研究。文本情感分析可以分为基于机器学习的情感分类方法和基于语义理解的情感分析。基于机器学习进行语义分析的话需要大量的训练集,同时需要人工对其进行分类标注。我所使用的方法是基于语义理解中的使用情感词典进行情感态度分析。
下面是我所使用的情感词典:
链接:HTTPS://pan.baidu.com/s/1xC9mcZcHZbVWwF3YO8yqOA
提取码:t0vv
情感词典有很多种,比如哈工大整理的,知网情感词典以及台湾大学NTUSD简体中文情感词典等,但并不是每个词典对于我们来说都是有用的,我们要根据自己的文本内容来选择合适的情感词典。
进行情感分析,我们不能按照自己怎么想就去怎么进行分析,需要一定的支撑条件。我所用的算法是根据北京交通大学杨立月和王移芝两位所写的“微博情感分析的情感词典构造及分析方法研究”这篇论文所编写的,这论文的地址http://kns.cnki.net/kcms/detail/61.1450.tp.20181115.1046.008.html
进行情感分析的大致流程如下图:
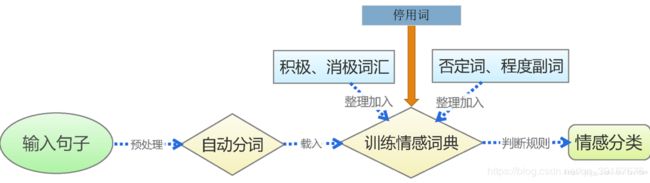
第一步先对文本进行预处理:
这里对文本进行预处理就是对句子进行分词,分词工具有很多,我选择的是使用python中的结巴分词,这个分词工具很好用,可以在分词的同时将词性也分析出来。不过在分词之前,对于一段文本内容来说,并不是所有的内容都对情感分析有帮助,比如一本书的书名,微博文本的标题以及一些非中文内容等,时候这个就我们可以用正则表达式只匹配我们需要的内容
import jieba.posseg as pseg #包括了词性(词语,词性)
def seg_word(sentenct):
d = ""
sentenct = re.sub(u"\\#.*?\\#|\\@.*?\\ |\\《.*?\\》|【.*?】", "", sentenct) # 处理#...#和@... (空格)间的数据
s = re.compile(r'http://[a-zA-Z0-9.?/&=:]*', re.S)
sentenct = s.sub("", sentenct)
segList = pseg.cut(sentenct) #分词
segResult = []
data_c = []
data_p =[]
for word,flag in segList:
if ('\u4e00' <= word <= '\u9fa5'): #判断字符串是否为中文
if len(word)>1:
data_p.append(word)
segResult.append(word)
s = word + "/" + flag
d=d+s+" "
data_c.append(d)
return data_c #带有词性的列表
第二步就是将分词后的词向量通过情感词典进行训练了:
英汉词典情感包括情感词,否定词,副词程度以及停用词
情感词:是主体对某一客体表示内在评价的词语,带有强烈的感情色彩。
程度副词:本身没有情感倾向,但能够增强或减弱情感强度
否定词:本身也没有情感倾向,但能改变情感的极性
停用词:完全没有用或者没有意义的词
首先我们可以利用停用词去掉一些没有意义的词语,比如这,那,是等词语,将一些没有意义的词语过滤掉后,剩下的大部分就是对情感分析有用的词语了。在去除了停用词后,我们就可以利用情感词,程度副词以及否定词来运用一定的算法进行情感分析了
下面是通过停用词典匹配的代码
def stopchineseword(segResult):
file = open("f:\\chineseStopWords.txt","r")
data = []
new_segResult=[]
for i in file.readlines(): #从文件中读取数据并将其添加到列表中
data.append(i.strip())
for i in segResult:
if i in data: #比较是否为停用词
continue
else:
new_segResult.append(i)
return new_segResult在做完上面两步后,我们就可以开始利用情感词典来进行分析了
有人会问知道了情感词后如何进行分析呢,这只是词语啊?在这里,我们就需要给情感词进行打分了。情感词分为正面情感词和负面情感词,也可能会多分几类,但在这只讨论正反两面。有些情感词典可能会给出情感词对应的分值(怎么算的我就不知道了)。根据上面说的论文中所写,我们对情感词进行赋值,正面情感词分值为1,负面情感词分值为-1,中性词则为0程度副词也可以根据词典中所给出的不同程度基于不同等级的分值,否定词则全部置为 - 1。
语义是语句进行情感分类的重要特征,文档分类判断应按照词汇,句子,微博短文的步骤进行判断。情感倾向情感词前经常有程度副词修饰。当情感词前有程度副词修饰时,则会使情感词的情感倾向加强或减弱。而情感词前有否定词修饰时会使情感词的情感倾向反转。但在这里需要注意一个问题,就是对于否定词和程度词的不同位置可能会有两种结果。一是“否定词+程度副词+情感词”,还有就是“程度副词+否定词+情感词”。
对于“否定词+程度副词+情感词”的计算方式是
w = t *( - 1)* a * 0.5
对于“程度副词+否定词+情感词”的计算方式是
w = t *( - 1)* a * 2
其中w表示计算得到的情感词语的情感强度值,t表示情感词的权值,表示该情感词t前的程度副词的权值
在求得词向量中所有情感词的权值后进行求和,若得到的分值大于0,则为正面情感;若分值小于0,则为负面情感;若分值为0,则为中性情感。
大致算法的就跟下图所示一样,但我这张图还存在一些缺陷,就是在判断词语词性时没有将循环展示出来

求情感词的代码如下(重点在于计算整句话中情感词的权值)
def classify_words(dict_data):
positive_words = []
positive_word = open("f:\\正面情绪词.txt","r",encoding="utf-8").readlines()
for i in positive_word:
positive_words.append(i.strip())
negative_words = []
negative_word = open("f:\\负面情绪词.txt","r",encoding="utf-8").readlines()
for i in negative_word:
negative_words.append(i.strip())
privative_words = []
privative_word = open("f:\\否定词.txt","r",encoding="utf-8").readlines()
for i in privative_word:
privative_words.append(i.strip())
adverb_of_degree_words1 = []
adverb_of_degree1 = open("f:\\2倍.txt","r").readlines()
for i in adverb_of_degree1:
adverb_of_degree_words1.append(i.strip())
adverb_of_degree_words2 = []
adverb_of_degree2 = open("f:\\1.5倍.txt","r").readlines()
for i in adverb_of_degree2:
adverb_of_degree_words2.append(i.strip())
adverb_of_degree_words3 = []
adverb_of_degree3 = open("f:\\1.25倍.txt","r").readlines()
for i in adverb_of_degree3:
adverb_of_degree_words3.append(i.strip())
adverb_of_degree_words4 = []
adverb_of_degree4 = open("f:\\1.2倍.txt","r").readlines()
for i in adverb_of_degree4:
adverb_of_degree_words4.append(i.strip())
adverb_of_degree_words5 = []
adverb_of_degree5 = open("f:\\0.8倍.txt","r").readlines()
for i in adverb_of_degree5:
adverb_of_degree_words5.append(i.strip())
adverb_of_degree_words6 = []
adverb_of_degree6 = open("f:\\0.5倍.txt","r").readlines()
for i in adverb_of_degree6:
adverb_of_degree_words6.append(i.strip())
z = 0
data = []
for k,v in enumerate(dict_data):
w = 0
if v in positive_words: #为正面情感词
w += 1
for i in range(z, int(k)):
if dict_data[i] in privative_words:
for j in range(z, i): #程度词+否定词+情感词
if dict_data[j] in adverb_of_degree_words6 or dict_data[j] in adverb_of_degree_words5 or \
dict_data[j] in adverb_of_degree_words4 or dict_data[j] in adverb_of_degree_words3 or \
dict_data[j] in adverb_of_degree_words2 or dict_data[j] in adverb_of_degree_words1:
w = w * (-1) * 2
break
for j in range(i, int(k)): #否定词+程度词+情感词
if dict_data[j] in adverb_of_degree_words6 or dict_data[j] in adverb_of_degree_words5 or \
dict_data[j] in adverb_of_degree_words4 or dict_data[j] in adverb_of_degree_words3 or \
dict_data[j] in adverb_of_degree_words2 or dict_data[j] in adverb_of_degree_words1:
w = w * 0.5
break
elif dict_data[i] in adverb_of_degree_words1:
w =w * 2
elif dict_data[i] in adverb_of_degree_words2:
w =w * 1.5
elif dict_data[i] in adverb_of_degree_words3:
w =w * 1.25
elif dict_data[i] in adverb_of_degree_words4:
w =w * 1.2
elif dict_data[i] in adverb_of_degree_words5:
w =w * 0.8
elif dict_data[i] in adverb_of_degree_words6:
w =w * 0.5
z = int(k) + 1
if v in negative_words: #为负面情感词
w -= 1
for i in range(z, int(k)):
if dict_data[i] in privative_words:
for j in range(z, i): #程度词+否定词+情感词
if dict_data[j] in adverb_of_degree_words6 or dict_data[j] in adverb_of_degree_words5 or \
dict_data[j] in adverb_of_degree_words4 or dict_data[j] in adverb_of_degree_words3 or \
dict_data[j] in adverb_of_degree_words2 or dict_data[j] in adverb_of_degree_words1:
w = w * (-1)*2
break
for j in range(i,int(k)): #否定词+程度词+情感词
if dict_data[j] in adverb_of_degree_words6 or dict_data[j] in adverb_of_degree_words5 or \
dict_data[j] in adverb_of_degree_words4 or dict_data[j] in adverb_of_degree_words3 or \
dict_data[j] in adverb_of_degree_words2 or dict_data[j] in adverb_of_degree_words1:
w = w*0.5
break
if dict_data[i] in adverb_of_degree_words1:
w *= 2
elif dict_data[i] in adverb_of_degree_words2:
w *= 1.5
elif dict_data[i] in adverb_of_degree_words3:
w *= 1.25
elif dict_data[i] in adverb_of_degree_words4:
w *= 1.2
elif dict_data[i] in adverb_of_degree_words5:
w *= 0.8
elif dict_data[i] in adverb_of_degree_words6:
w *= 0.5
z = int(k)+1
data.append(w)
return data