显著性检测2019(ICCV, CVPR)【part-2】
1.《Attentive Feedback Network for Boundary-Aware Salient Object Detection》
网络结构如下:
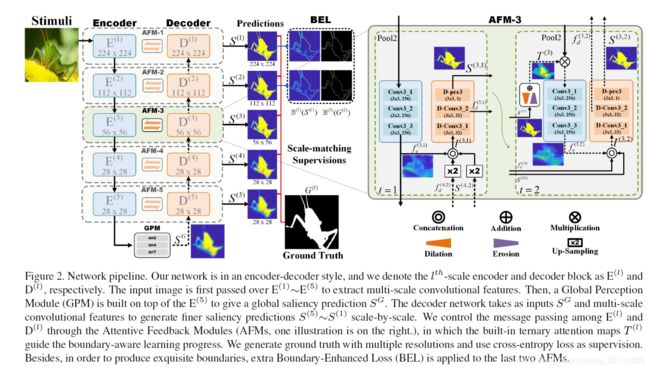
同样是FCN-based (或 Encoder-Decoder)网络模型。 Encoder给出基于全局信息的预测(由GPM模块实现),之后Decoder不断修正优化输出。创新点依然在特征融合的方式,采用Attentive Feedback Module(AFM)更加关注边界,也给模型更多自我修正的机会和能力。 同时提出Boundary Enhanced Loss(BEL)强化对边界信息的学习。
(1)Global Perception Module
如图所示:将编码器的最后输出的feature map 划为 n × n 的小块。每次同时对所有小块的相应位置做卷积融合特征,相当于将所有小块沿着channel拼接起来做一次卷积。这样提取特征获得了更多的全局信息(类似于空洞卷积),同时也包含了更紧密的局部信息。
通过该模块融合特征后生成全局的显著预测图。

(2)Attentive Feedback Moudle

采用两步走的循环方式
第一阶段产生修正图后,送入第二阶段
第二阶段利用膨胀和腐蚀算法,基于第一阶段的修正图,产生三元组的注意力图(注意力机制),具体的,通过对第一阶段的显著修正图做膨胀和腐蚀,其实现方式如下:
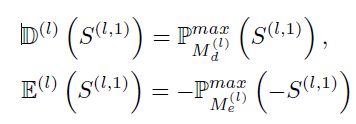
然后对二者得到的结果取平均值,这样,显著内部趋近于1,非显著区趋近于0,边界趋近于0.5(所以称为三元注意力图)。该注意力图相当于权重,weight 上一层编码器的编码特征。然后再结合一阶段的相应输出送入解码器得到二次修正的显著图。
之所以参用两阶段是因为 a.单阶段包含上采样操作,会引入不准确值,尤其在边界处。 b. 模型没有自我修正的能力,一旦上一模块没能给出完整物体预测,模型后面也很难给出完整的显著性检测。
两阶段方案给了模型基于三元注意力图的修正错误的能力,更好的关注边界信息。
(3)Ground Truth 监管方案(loss函数设计)

第一项为基本显著性检测的交叉熵损失。
第二项为关注边界的BEL损失,该损失使用欧式损失计算Ground Truth的边界和预测图边界的损失。而边界是通过下式相减得到的:
其中:

后一项代表对X做average pooling以平滑图像,通过相减,抽取边界。
lamda 1 : lamda 2 = 1: 10 以强化对边界的学习。
注意:对3,4,5层仅仅使用第一项损失,即交叉熵损失,因为这些层已经无可以帮助学习边界的底层信息。仅仅对1,2两层使用完整的一二两项损失优化显著图。
Decoder第1层第2阶段的显著预测图S(1,2)为模型给出的最终的显著预测图。
2.《BASNet: Boundary-Aware Salient Object Detection》
网络结构如下:

创新点主要在于:使用混合loss。包括:普通二值交叉熵(BCELoss)和Structural SIMilarity (SSIM) Loss 和 IoU losses,分别对应于pixel级别,patch级别,map级别。


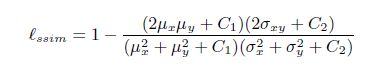

BCELoss平等的对待每个像素,给每个像素一个平滑的训练梯度;IOULoss 聚焦于前景,SSIM关注于图像的结构性,即每个像素的局部(邻居部分),所以更加会更针对于边界。
混合loss 的使用更有利于给出完整的,边界清晰的显著物体预测。
3.《Selectivity or Invariance: Boundary-aware Salient Object Detection》
同样关注边界问题。 作者认为当前显著性检测面临2个问题:1是对大物体,尤其内部尺寸,颜色变化性的大的物体,如何检测出完整的显著物体-----这就需要提取特征具有不变性invariance;2.是如何准确给出显著物体与非显著物体的边界,而这就需要参考二者之间的变化性------selectivity。 1,2问题是对立的。即要 无视显著物体内部的变化,从而检测出完整物体;又要敏感关注边界变化,找准边界信息。 -----selectivity–invariance dilemma问题。针对以上问题,作者提出BAS网络模型。
(BASNet)网络结构图如下:

通过Skip-Connection 融合Multi-level的特征(尤其是为了引入低层边缘特征),送入边界定位模块检测显著图边界。 通过对特征提取模块包括丰富全局语义信息的最后一层特征再进行一系列的空洞卷积(integrated successive dilation (ISD) module),继续扩大感受野,融合语义信息,送入内部感知模块和过渡转换模块。内部感知模块检测显著图内部。过渡转换模型用来补充修正边界与内部融合时的错误。
(1) 边界定位模块:
input : 所有层的特征信息 output :通过sigmoid给出边界信息
通过交叉熵损失学习预测边界与Ground Truth边界差距。 输入复杂,网络简单。

(2) 内部感知模块:
input:最后一层语义特征信息 output: 通过sigmoid给出显著图
通过交叉熵损失学习预测显著图与Ground Truth差距。输入简单,网络复杂
![]()
(3) 过渡融合模块:
input: 第二层低层边缘信息和最后一层高级语义信息,通过element_sum 融合。 output: 过渡的特征表示图,包含selectivity 和 Invariance。 输入中等,网络中等
(4) 内部感知模块和过渡融合模块 都是由空洞卷积模块(Integrated Successive Dilation Module (ISD)) 实现。

通过不同rate的空洞卷积以及intra- 和 inter- 的short-connection, 融合获取含有丰富的文本信息,语义信息的特征。 内部感知模块使用ISD-5. 过渡融合模块使用ISD-3.
(4) 三个模块的输出整合
三个模块的输出不是通过简单相加或者concate得到,这样会引入不必要的噪声。而是通过边界和内部两个模块的confidence map 得到权重并与对应特征图相乘(element_wise product)完成融合。


最后通过sigmoid给出显著预测图,并使用交叉熵损失函数学习与Ground Truth 的损失。

(5) 网络整体损失函数如下:
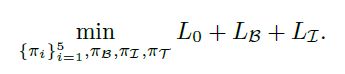
注意:由网络连接图可看出:
基本特征提取模块和过渡融合模块的参数 受三个损失的监管进行更新。
边界定位模块受 L0 和 LB 监管进行更新
内部感知模块受 L0 和 LI 监管进行更新
4.《EGNet: Edge Guidance Network for Salient Object Detection》
与 3.类似,网络同时提取边缘特征信息和显著物体信息,完成边界预测与显著物体检测,两个模块,两种特征相融合,实现更优的显著物体检测效果。
(EGNet)网络结构图如下:

1个边缘预测图,9个显著预测图, 一律使用交叉熵损失函数实现Ground Truth 监管。
5.《Stacked Cross Refinement Network for Edge-Aware Salient Object Detection》
(SCRN)网络结构图如下:
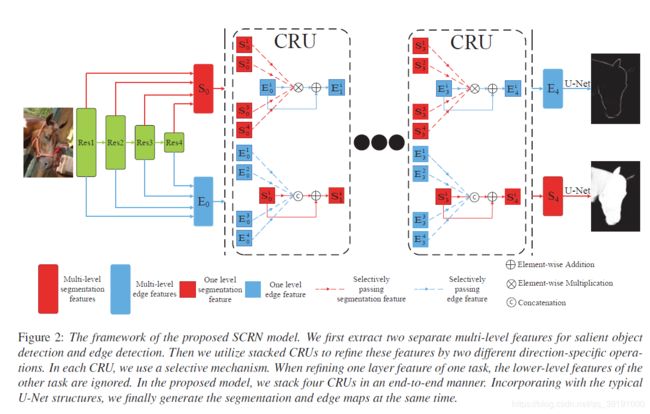
真正意义上完成边缘检测和显著性检测两大任务的融合。
通过级联CRU(Cross Refinement Unit),不断完成两个任务的特征融合,最后借助U-Net 预测边缘和显著图,并使用交叉熵损失计算边缘和显著预测图与对应Ground Truth的差异。
特征融合的思路来源于:
Feature(edge) and Feature(saliency) = Featurenew(edge) (and 求交集)
Feature(edge) or Feature(saliency) = Featurenew(saliency) (or 求并集)
基于该原理,用concat近似 or 操作, 用element_wise product 近似 and 操作, 借助残差学习 (residual learning )的方式,即在原有特征基础上再加上两大任务基于or 或 and融合后的特征,得到更新后的特征送入下一个CRU,继而重复执行上述操作
两大任务之间采用 选择性的集合-点的对应方式执行and 或 or 操作。即and 或者 or 操作的对象分别是一个任务的每一个点(each-level feature)和 另一个任务的有选择的集合(all-level feature)至此,基于and 和 or 的融合操作可分别表示为:
and 操作:
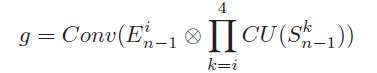
or 操作:
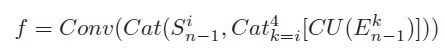
基于残差学习方式的进行更新的整体操作可分别表示为:

6.《Salient Object Detection with Pyramid Attention and Salient Edges》
网络结构图如下:
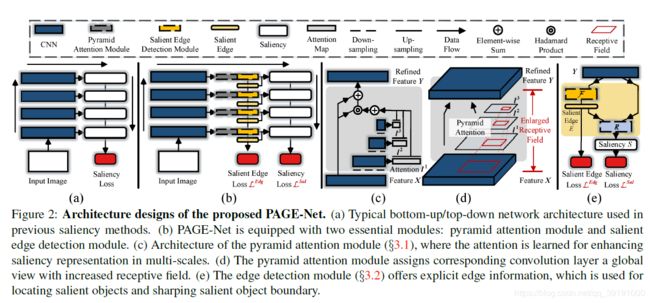
同样是基于传统的bottom-up前行传播,top-down 完成修正的架构模型,创新点包括:
(1)top-down 修正过程中对横向传来的低层特征使用注意力机制------对每一层卷积特征均采用Pyramid Attention 机制,通过对特征做Scale transform,每个Scale 都得到一个attention map,然后相加并与原始特征相乘,得到注意力后的特征。参用Residual learning, 即原始特征与注意力后的特征相加,得到最终更新后的特征。这样做相当于扩大了感受野,包含了Multi-Scale 的信息。
(2) 在显著图预测前加入 边缘edge的预测,在原有特征基础上强制加入边缘特征信息,达到更好的显著图预测效果。 并且采用Dense Connection, L 层 的特征 融合前面所有层 (L-1,L-2,……2,1) 的显著预测信息图和边缘信息,以到达更好预测效果。
使用Deep Supervision,对每层的边缘预测和显著图预测都计算loss, 施加监管。
其中,边缘损失采用L2 norm loss ,如下:
![]() 显著图损失采用 weighted cross-entropy loss.如下:
显著图损失采用 weighted cross-entropy loss.如下:

整体损失如下:累计5个 side-output 。 5个层对应VGG16。

7.《A Mutual Learning Method for Salient Object Detection with intertwined Multi-Supervision》
之前显著性研究的不足:
a. 无法提取完整的显著性物体,因为其内部结构过于复杂。
b. 显著物体的边缘轮廓检测不准确。
基于此不足,提出新的网络和训练策略,针对3个不同任务-----显著性检测,前景轮廓检测, 边缘检测。
网络结构图如下:

输入包括 显著性待检测图和边缘待检测图,监管包括对应的Salience Ground Truth(S-gt) 和 Edge Ground Truth(E-gt) 以及通过Canny 算法提取的Foreground Contour Ground Truth(FC-gt), 以此驱动三大任务的训练和学习。

(1)显著性检测和前景轮廓检测都需要准确的前景检测。所以二者可以相互协作促进。
在Encoder阶段,前3个block使用前景轮廓Ground Truth 监管,后3个block使用显著性Ground Truth。在Decoder阶段,交替使用二者的Ground Truth监管,迫使网络在不断融合encoder的MLM模块传来的特征基础上,一会“fill”前景完成显著性检测,一会“extract”轮廓完成前景轮廓检测。这样做可以不断过滤噪声影响,交互提升两个任务的效果。
(2)前3个block还保留有丰富的边缘信息。所以加入 Edge Module, 完成边缘的检测,辅助前景轮廓检测任务。
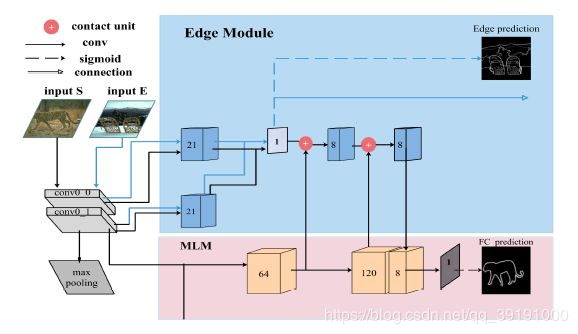
当输入边缘图时,给出边缘检测的预测图,当输入是显著图时,边缘检测模块为MLM前景轮廓检测模块提供边缘特征,辅助检测前景轮廓。
(3)Mutual Learning Module
在Encoder 部分 采用MLM模块提取前景轮廓和显著性特征并完成预测(受Ground Truth监管)

该模块启发于Deep Mutual Learning. 设立多个分支,执行同一个任务,对每个分支的预测结果采用Sub-Supervision互相监管(Mimicry loss)和Ground Truth loss 监管.各个分支互相辅助训练,但可以独立使用,训练时仅随机选取一个分支测试。不同于DML使用KL散度计算Mimicry loss, MML使用L2 loss 计算 Mimicry loss. Mimicry loss 为每个分支子网络提供了更soft 的损失,更有利于收敛于局部最小值。
(4)训练方式(Training)
损失函数:
Encoder部分:
![]()
第一项为 前景轮廓和显著图损失

第二项为边缘损失

第三项为 MLM Mimicry loss

解码器部分:
显著图和前景轮廓图损失

训练策略:
采用交替训练
Step.1 We first train the encoder network, i.e. the backbone
network with MLMs and EMs, with LEnc(编码器损失).
Step.2 We fix the encoder and feed features in MLMs
into the decoder network then train the decoder network
alone with LDec(解码器损失).
Step.3 After training the decoder, we then fix the decoder
and fine-tune the encoder using the supervision of decoder,
i.e. LDec, to optimize the parameters of encoder.
We repeat the steps above iteratively, and in each training
step we stay for 10 epochs before switch to the next。
和前面第3篇,第4篇等Salience 和 Edge detection 融合的方式不同,不是简单的完成两大任务,然后融合特征,该篇论文参用的是深度交融方式,交替监管显著图和前景轮廓图,不断过滤噪声,优化特征,提升效果。另外,在Encoder部分就加入了Ground Truth 监管,而且是交替训练的策略,更是大大提升三大任务特征提取的能力。