HBase知识点总结(面试)
阅读摘记,更新中...
目录
LSM-Tree是什么?
为何HBase速度很快?
HBase与Hive区别?
HBase与传统关系型数据库区别?
HBase的读写流程?
Rolling WAL?
Hbase memstore 的刷写时机?
为什么不建议在 HBase 中使用过多的列族?
HRegionServer 宕机如何处理?
HBase合并机制?
HBase读性能优化?
客户端优化
服务端优化
列族设计优化
HDFS优化
HBase写性能优化?
RowKey如何设计?
LSM-Tree是什么?
Log-structured(日志结构) Merge(合并)-Tree, 日志可理解为一页一页往下写,而且系统写日志不会写错,所以不需要更改,只需要在后边追加就好了。LSM-tree 是专门为 key-value 存储系统设计的,key-value 类型的存储系统最主要的就两个个功能,put(k,v)、get(k)。LSM-tree 最大的特点就是写入速度快,主要利用了磁盘的顺序写,优于需要随机写入的 B-tree。
下图是 LSM-tree 的组成部分,是一个多层结构,就更一个树一样,上小下大。首先是内存的 C0 层,保存了所有最近写入的 kv对,这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。剩下的 C1 到 Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构。

写入流程
kv对首先追加到WAL,接下来加到 C0 层。当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,类似归并排序,这个过程就是Compaction。合并出来的新的 new-C1 会顺序写磁盘,替换掉原来的 old-C1。当 C1 层达到一定大小,会继续和下层合并。合并之后所有旧文件都可以删掉,留下新的。注意数据的写入可能重复,新版本需要覆盖老版本,并且老版本的清理是在合并的时候进行的。写入过程基本只用到了内存结构,Compaction 可以后台异步完成,不阻塞写入。
查询流程
最新的数据在 C0 层,最老的数据在 Ck 层,所以查询也是先查 C0 层,如果没有要查的 k,再查 C1,逐层查。一次查询可能需要多次单点查询,稍微慢一些。所以 LSM-tree 主要针对的场景是写密集、少量查询的场景。
摘自:https://cloud.tencent.com/developer/news/340271
为何HBase速度很快?
HBase能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-Structured Merge-Tree) + HTable(region分区) + Cache决定
- 写快
HBase会将数据保存到内存中,在内存中的数据是有序的,如果内存空间满了,会刷写到HFile中,而在HFile中保存的内容也是有序的。当数据写入HFile后,内存中的数据会被丢弃。
HFile文件为磁盘顺序读取做了优化,按页存储。在内存中多个块存储并归并到磁盘的过程中,合并写入会产生新的结果块,最终多个块被合并为更大块。HBase的写入速度快是因为它其实并不是真的立即写入文件中,而是先写入内存,随后异步刷入HFile。所以在客户端看来,写入速度很快。另外,磁盘的数据是有序的,这是利用预写日志和内存把随机写数据进行排序后写入,将随机写入转换成顺序写,数据写入速度也很稳定。
- 读快
客户端可以直接定位(zookeeper中meta表)到要查数据所在的HRegion server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。并且多次刷写后会产生很多小文件,后台线程会合并小文件组成大文件,这样磁盘查找会限制在少数几个数据存储文件中。
使用了LSM树型结构(LSM的优点:能快速进行数据的合并和拆分),而不是B或B+树(随机读,B+树的应用场景:主要用在传统的行数据库中,因为查询速度快。但是如有有大量的数据需要查询时就暴露出其弊端)。磁盘的顺序读取速度很快,而相比较寻道时间慢一些。HBase的存储结构导致它需要磁盘寻道时间在可预测范围内,比如有5个HFile,那么最多需要5次磁盘寻道。
HBase读取首先会在读缓存(BlockCache)中查找,它采用了LRU(最近最少使用算法),如果缓存中没找到,会从内存中的MemStore中查找,只有这两个地方都找不到时,才会加载HFile中的内容,而上文也提到了读取HFile速度也会很快,因为节省了寻道开销。
摘自:https://blog.csdn.net/keda8997110/article/details/50916800
https://www.cnblogs.com/parent-absent-son/p/10462272.html
HBase与Hive区别?
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
- Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种分布式的基于列式存储的NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询。Hbase适合存储半结构化或非结构化数据。
- Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
数据流一般如下
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
HBase与传统关系型数据库区别?
| Mysql | Hbase |
|---|---|
| 行存储 | 列式存储 |
| 适用于OLTP业务 | 平衡了OLTP、OLAP业务 |
| 单机、可扩展性差 | 水平扩展 |
| 支持事务 | 不支持事务 |
| 强一致性 | 强一致性,时间线一致性 |
| 支持二级索引 | 不支持二级索引 |
| 支持全文索引 | 不支持全文索引 |
1)数据类型:HBase只有简单的字节数组,所有的类型都是交由用户自己处理,它只保存字符串;而关系数据库有丰富的类型和存储方式。
2)数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,不支持条件查询,只支持按照Row key来查询("多条件"可以通过过滤器实现);而传统数据库通常有各式各样的函数和连接操作。
3)存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的
4)数据维护:HBase的更新操作不应该叫更新,它实际上是插入了新的数据,因为hdfs只支持追加;而传统数据库是替换修改
5)可伸缩性:Hbase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
HBase的读写流程?
读
1)HRegionServer 保存着 meta 表以及表数据,若内存中无缓存meta表,首先 Client 先去访问zookeeper,从 zookeeper 里面获取 meta 表所在的位置信息,即找到这个 meta 表在哪个HRegionServer 上保存着。
2)接着 Client 通过刚才获取到的 HRegionServer 的 IP 来访问 Meta 表所在的HRegionServer,从而读取到 Meta,进而获取到 Meta 表中存放的元数据,并会将meta表缓存在内存中。
3)Client 通过元数据中存储的信息,访问对应的 HRegionServer,然后直到找到数据前依次扫描所在HRegionServer 的 BlockCache、Memstore 和 HFile 来查询。
4)最后 HRegionServer 把查询到的数据响应给 Client。
写
1)若内存中没缓存meta表,Client 会先访问 zookeeper,并获取 Meta 表元数据。确定当前将要写入的数据所对应的 HRegion 和 HRegionServer 服务器。
2)Client 向该 HRegionServer 服务器发起写入数据请求,然后 HRegionServer 收到请求并响应。
3)Client 先把数据写入到 WAL,以防止数据丢失。
4)然后将数据写入到 Memstore。如果 HLog 和 Memstore 均写入成功,则这条数据写入成功
5) 如果 Memstore 达到阈值,会把 Memstore 中的数据 flush 到 Storefile 中。
6)当 Storefile 越来越多,会触发 Compact 合并操作,把过多的 Storefile 合并成一个大的 Storefile。
7)当 Storefile 越来越大,Region 也会越来越大,达到阈值后,会触发 Split 操作,将Region 一分为二。
Rolling WAL?
当 WAL 文件越来越大,这个文件最终是会被关闭的,然后再创建一个新的 active WAL 文件用于存储后面的更新。这个操作称为 rolling WAL 文件。一旦 WAL 文件发生了 Rolled,这个文件就不会再发生修改。因为WAL是hdfs上的文件而不是内存,只能通过常见新的WAL文件来达到非阻塞的效果。
默认情况下,WAL 文件的大小达到了 HDFS 块大小的 90%(HBase 2.0.0 之后是 50%),这个 WAL 文件就会发生 roll 操作。 可以通过 hbase.regionserver.logroll.multiplier 参数控制达到块大小的多少百分比就发生 roll;也可以通过 hbase.regionserver.hlog.blocksize 参数来控制块大小(注意,这个块大小不是 HDFS 的块大小,默认512M)。除了文件大小能触发 rolling,HBase 也会定时去 Rolling WAL 文件,这个时间是通过 hbase.regionserver.logroll.period 参数实现的,默认是一小时。
摘自:https://www.iteblog.com/archives/2502.html
Hbase memstore 的刷写时机?
注意:MemStore的最小flush单元是HRegion而不是单个MemStore。所以如果一个HRegion中Memstore过多,每次flush的开销必然会很大,因此我们也建议在进行表设计的时候尽量减少ColumnFamily的个数。
刷写的时机有6种:
1)Memstore级别限制:当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB)
2)Region级别限制:当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier *hbase.hregion.memstore.flush.size,默认 2*128M = 256M)
3)Region Server级别限制:当一个Region Server中所有Memstore的大小总和达到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认40%的JVM内存使用量)。Flush顺序是按照Memstore由大到小执行,先Flush Memstore最大的Region,直至总体Memstore内存使用量低于阈值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM内存使用量)。
4)当一个Region Server中HLog数量达到上限(参数hbase.regionserver.maxlogs,默认32),系统会选取最早的一个 HLog对应的Region进行flush
5)HBase定期刷新Memstore:默认周期为1小时(参数hbase.regionserver.optionalcacheflushinterval),确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000ms左右的随机延时。
6)手动执行flush:用户可以通过shell命令 flush 'tablename' 或 flush 'regionname'分别对一个表或者一个Region进行flush
也可以总结为3种:
1)put/delete引起了memstore的变化的
2)region的split,merge,compact引起region变化的
3)有一个定时线程(PeriodiaMemStoreFlusher)轮询每一个region是否需要flush。
摘自:https://cloud.tencent.com/developer/article/1005744
为什么不建议在 HBase 中使用过多的列族?
HBase官方文档中提到,每张表的列族个数建议设在1~3之间。
- Flush
在HRegion中每个列族对应了一个HStore,HStore中存在MemStore和HFile;越多的列族,将会导致内存中存在越多的 MemStore;而储存在 MemStore 中的数据在满足一定条件的时候将会进行 Flush 操作;每次 Flush 的时候,每个 MemStore 将在磁盘生产一个 HFile 文件,这样会导致越多的列族最终持久化到磁盘的 HFile 越多。而Flush 操作是 Region 级别的,当表有很多列族,而且列族之间数据不均匀,这样会导致持久化到磁盘的文件数很多,同时有很多小文件,而且每次 Flush 操作也涉及到一定的 IO 操作
MemStore级别刷新:为了解决每次 Flush 都对整个 Region 中 MemStore 进行的,引入了对 Flush 策略进行选择的功能(hbase.regionserver.flush.policy),可以仅对超过阈值(hbase.hregion.percolumnfamilyflush.size.lower.bound.min)的 MemStore 进行 Flush 操作
此外,如果我们的列族数过多,这可能会导致触发 RegionServer 级别的 Flush 操作;这将会导致落在该 RegionServer上的更新操作被阻塞,而且阻塞时间可能会达到分钟级别
- Split
Region 中某个最大的 HFile 大于 hbase.hregion.max.filesize(1G) 会触发 Region 拆分的,会被拆分成两个。若列族之间数据不均匀,在 Region Split 的时候会导致原本数据量很小的 HFile 文件进一步被拆分,从而产生更多的小文件。Region Split 是针对所有的列族进行的,这样做的目的是同一行的数据即使在 Split 后也是存在同一个 Region 的
- Compaction
与 Flush 操作一样,目前 HBase 的 Compaction 操作也是 Region 级别的
- HDFS
HDFS 对一个目录下的文件数有限制的(dfs.namenode.fs-limits.max-directory-items 默认1048576)。如果我们有 m 个列族,n 个 Region,那么我们持久化到 HDFS 至少会产生 mn 个文件;而每个列族对应底层的 HFile 文件可能不止一个,我们假设为 K 个,那么最终表在 HDFS 目录下的文件数将是 mnk,这可能会超出 HDFS 的限制
- RegionServer 内存
HBase 从 0.90.1 版本开始引入了 MSLAB(Memstore-Local Allocation Buffers,即MemStore本地配置缓冲区),这个功能默认是开启的(hbase.hregion.memstore.mslab.enabled),这使得每个 MemStore 在内存占用了 2MB (通过hbase.hregion.memstore.mslab.chunksize 配置)的 buffer。如果有多个列族,而且一般一个 RegionServer 上会存在很多个 Region,这样光 MemStore 的缓存就会占用很多的内存。
摘自:https://www.iteblog.com/archives/2474.html
HRegionServer 宕机如何处理?
1)ZooKeeper 会监控 HRegionServer 的上下线情况,当 ZK 发现某个 HRegionServer 宕机之后会通知 HMaster 进行失效备援;
2)该 HRegionServer 会停止对外提供服务,就是它所负责的 region 暂时停止对外提供服务;
3)HMaster 会将该 HRegionServer 所负责的 region 转移到其他 HRegionServer 上,并且会对 HRegionServer 上存在 memstore 中还未持久化到磁盘中的数据进行恢复;
4)这个恢复的工作是由 WAL 重播来完成,这个过程如下:
- wal 实际上就是一个文件,存在/hbase/WAL/对应 RegionServer 路径下。
- 宕机发生时,读取该 RegionServer 所对应的路径下的 wal 文件,然后根据不同的region 切分成不同的临时文件 recover.edits。
- 当 region 被分配到新的 RegionServer 中,RegionServer 读取 region 时会进行是否存在 recover.edits,如果有则进行恢复。
HBase合并机制?
HBase Compaction 主要有如下几个作用:文件合并;对于删除、过期、多余版本的数据进行清除
Compaction 方式又分为两种:
- Minor Compaction:只合并小文件,对TTL过期数据设置过期清理,不会对文件内容进行清除操作
- Major Compaction:对 Region 下同一个 CF 的 HFile 合并为一个大文件,并且清除删除、过期、多余版本的数据。
Compaction 触发时机:
- 通过 CompactionChecker 线程来定时检查是否需要执行 compaction(RegionServer 启动时在 initializeThreads() 中初始化),每隔10000秒(可配置)检查一次
- 每当 RegionServer 发生一次 Memstore flush 操作之后也会进行检查是否需要进行 Compaction 操作
- 手动触发,执行命令major_compact 、 compact
Minor Compaction相关参数:
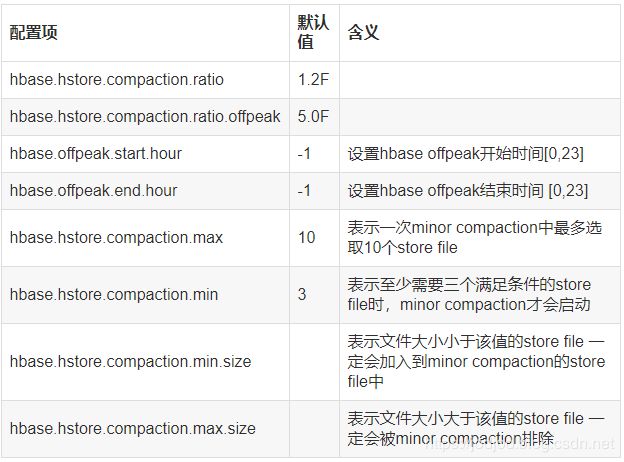
1)如果是高峰时段,使用 hbase.hstore.compaction.ratio.offpeak 参数,否则使用 hbase.hstore.compaction.ratio。
2)将 StoreFile 按照文件年龄排序,minor compaction 总是从 older store file 开始选择。
3)如果该文件的 size 小于 hbase.hstore.compaction.max 个 store file size 之和乘以 ratio 的值,那么该 store file 将加入到 minor compaction 中。
4)如果满足 minor compaction 条件的文件数量大于 hbase.hstore.compaction.min,才会启动
hbase.hstore.compaction.min.size 和 hbase.hstore.compaction.max.size 参数用于控制特殊大小的文件直接判断是否加入 minor compaction。
Major Compaction
Major Compaction与HFile的最早更新时间有关。Major Compaction 时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。线上业务可以通过设置 hbase.hregion.majorcompaction = 0 可以关闭CompactionChecke 触发 major compaction,但是无法关闭用户调用的 major compaction。
摘自:https://www.jianshu.com/p/4595ded4055a
HBase读性能优化?
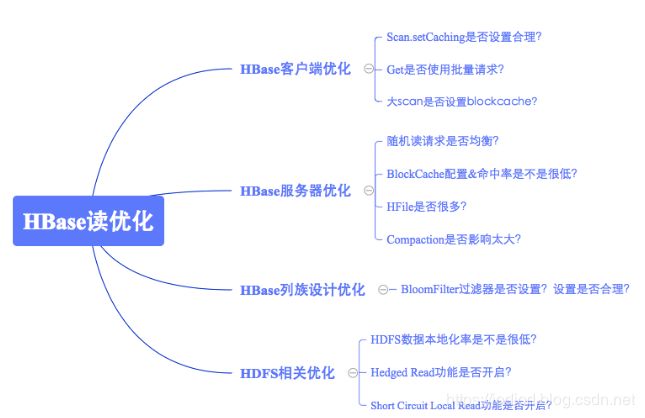
客户端优化
1)scan缓存
客户端发起一次scan请求,实际并不会一次就将所有数据加载到本地,而是分成多次RPC请求进行加载。默认100条数据一次rpc,缓存数可理解为一次rpc拿多少条数据;通过setCacheing()可以有效地减少rpc数,降低scan请求的总体延迟。
2)批量get
使用批量get接口可以减少客户端到RegionServer之间的RPC连接数,提高读取性能。另外,批量get请求要么成功返回所有请求数据,要么抛出异常(HBase中的原子性是针对单条或多条数据的)
3)读时指定列族或列
HBase是典型的列族数据库,意味着同一列族的数据存储在一起,只是根据Rowkey而不指定列族进行检索的话不同列族的数据需要独立进行检索,性能必然会比指定列族的查询差很多。
4)离线批量读取请求设置禁止缓存
通常离线批量读取数据会进行一次性全表扫描,一方面数据量很大,另一方面请求只会执行一次。这种场景下如果使用scan默认设置,就会将数据从HDFS加载出来之后放到缓存。导致其他业务不得不从HDFS加载,进而会造成明显的读延迟毛刺。通过scan.setBlockCache(false)设置禁止缓存。
服务端优化
1)读请求均衡
极端情况下假如所有的读请求都落在一台RegionServer的某几个Region上,这一方面不能发挥整个集群的并发处理能力,另一方面势必造成此台RegionServer资源严重消耗。RowKey必须进行散列化处理(比如MD5散列),同时建表必须进行预分区处理
2)BlockCache的设置
BlockCache作为读缓存,默认情况下BlockCache和Memstore的配置相对比较均衡(各占40%),可以在读多写少业务中将BlockCache占比调大。BlockCache策略选择LRUBlockCache,不同策略对GC的影响却相当显著。
3)HFile数量
文件数量通常取决于Compaction的执行策略,一般和两个配置参数有关:hbase.hstore.compactionThreshold(默认3),表示一个store中的文件数超过多少就应该进行minor合并;hbase.hstore.compaction.max.size,表示参数合并的文件大小最大是多少,超过此大小的文件不能参与合并。
4)Compaction消耗系统资源
正常配置情况下Minor Compaction并不会带来很大的系统资源消耗,除非因为配置不合理导致Minor Compaction太过频繁,或者Region设置太大情况下发生Major Compaction。
Minor Compaction设置:hbase.hstore.compactionThreshold设置不能太小,又不能设置太大,因此建议设置为5~6;hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
Major Compaction设置:大Region读延迟敏感业务( 100G以上)通常不建议开启自动Major Compaction,手动低峰期触发。小Region或者延迟不敏感业务可以开启Major Compaction,但建议限制流量;
5)regionserver中响应用户表级请求的线程数
hbase.regionserver.handler.count 定义regionserver上用于等待响应用户表级请求(读或写)的线程数
列族设计优化
1)Bloomfilter过滤器
Bloomfilter主要用来过滤不存在待检索RowKey或者Row-Col的HFile文件,避免无用的IO操作。它会告诉你在这个HFile文件中是否可能存在待检索的KV,如果不存在,就可以不用消耗IO打开文件进行查询。通过设置Bloomfilter可以提升随机读写的性能。
Bloomfilter取值有两个,row以及rowcol;如果业务大多数随机查询仅仅使用row作为查询条件,通常设置为row就可以,除非确认业务随机查询类型为row+cf,可以设置为rowcol。如果不确定业务查询类型,设置为row。
HDFS优化
1)Short-Circuit Local Read 短路读
当前HDFS读取数据都需要经过DataNode,客户端会向DataNode发送读取数据的请求,DataNode接受到请求之后从硬盘中将文件读出来,再通过TPC发送给客户端(即使是数据在本地的情况下)。Short Circuit策略允许客户端绕过DataNode直接读取本地数据。
2)Hedged Read功能
补偿重试机制。客户端发起一个Short-Circuit Local Read本地读,一旦一段时间之后还没有返回(可能会出现因为磁盘问题或者网络问题引起的失败),客户端将会向其他DataNode发送相同数据的请求。哪一个请求先返回,另一个就会被丢弃。
3)数据本地率
数据本地率低的原因一般是因为Region迁移(自动balance开启、RegionServer宕机迁移、手动迁移等)。因此一方面可以通过避免Region无故迁移来保持数据本地率,另一方面如果数据本地率很低,也可以通过执行major compact提升数据本地率到100%。
总结
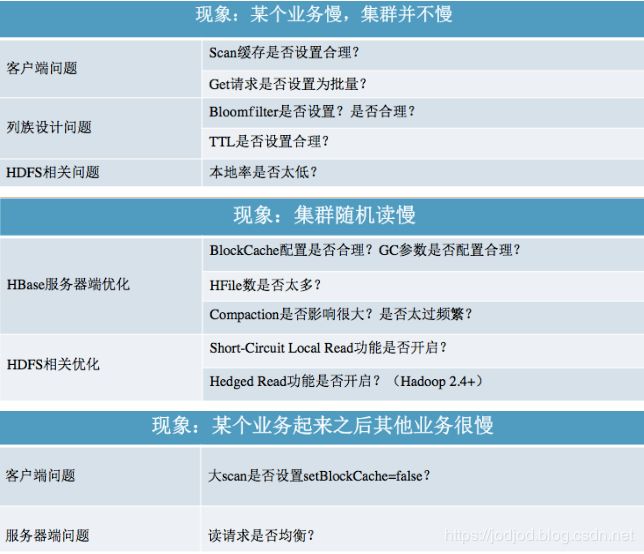
摘自:http://hbasefly.com/2016/11/11/hbase%e6%9c%80%e4%bd%b3%e5%ae%9e%e8%b7%b5%ef%bc%8d%e8%af%bb%e6%80%a7%e8%83%bd%e4%bc%98%e5%8c%96%e7%ad%96%e7%95%a5/
HBase写性能优化?
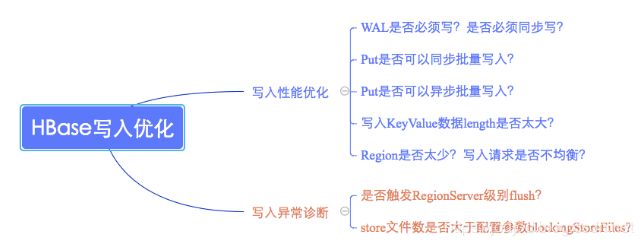
1)WAL
通常情况下大多数业务都会默认开启WAL机制默认,但是对于部分业务可能并不特别关心异常情况下部分数据的丢失,而更关心数据写入吞吐量,可以考虑关闭WAL写入
2)Put同步/异步批量写入
同步:使用批量put接口可以减少客户端到RegionServer之间的RPC连接数,提高写入性能。另外需要注意的是,批量put请求要么全部成功返回,要么抛出异常。
异步:如果可以接受异常情况下少量数据丢失的话,还可以使用异步批量提交的方式提交请求,setAutoFlush(false)。用户提交写请求之后,数据会写入客户端缓存,并返回用户写入成功;当客户端缓存达到阈值(默认2M)之后批量提交给RegionServer。
3)KeyValue过长
KeyValue太大会导致HLog文件写入频繁切换、flush以及compaction频繁触发,写入性能急剧下降。HBase 2.0.0之前没有直接的解决方案。
4)Region过少
当前集群中表的Region个数如果小于RegionServer个数,即Num(Region of Table) < Num(RegionServer),可以考虑切分Region并尽可能分布到不同RegionServer来提高系统请求并发度。
5)写均衡
与读均衡相同,检查RowKey设计以及预分区策略,保证写入请求均衡
6)HFile数量与配置参数blockingStoreFile
hbase.hstore.blockingStoreFiles 表示如果当前hstore中文件数大于该值,系统将会强制执行compaction操作进行文件合并,合并的过程会阻塞整个hstore的写入。hbase.hstore.compactionThreshold 表示启动compaction的最低阈值。
摘自:http://hbasefly.com/2016/12/10/hbase-parctice-write/?dshebu=jpk321
RowKey如何设计?
设计原则
1)唯一原则
由于在HBase中数据存储是Key-Value形式,若HBase中同一表插入相同Rowkey,则原先的数据会被覆盖掉(如果表的version设置为1的话),所以务必保证Rowkey的唯一性
2)排序原则
HBase的Rowkey是按照ASCII有序(字典排序)设计的,在设计Rowkey时要充分利用这点。比如设计的Rowkey要和时间顺序相关,可以使用"Long.MAX_VALUE - 时间"的 long 值作为 Rowkey 的前缀
3)散列原则
Rowkey应均匀的分布在各个HBase节点上,否则大量数据会在一个RegionServer上堆积的热点现象,也就是通常说的Region热点问题。 热点发生在大量的client直接访问集中在个别RegionServer上,导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用
4)长度原则
RowKey 可以是任意的字符串,最大长度64KB(因为 Rowlength 占2字节)。建议越短越好
- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
- MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率;
- 目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
如何避免热点问题?
1)Salting
在rowkey 的前面增加随机数。具体就是给 rowkey 分配一个随机前缀 以使得它和之前排序不同。分配的前缀种类数量应该和你想使数据分散到不同的 region 的数量一致。
因为分配是随机的,所以如果你想要以字典序取回数据,你需要做更多工作。加盐这种方式增加了写时的吞吐量,但是当读时有了额外代价。
2)Hashing
Hashing 的原理是计算 RowKey 的 hash 值,然后取 hash 的部分字符串和原来的 RowKey 进行拼接。这里说的 hash 包含 MD5、sha1、sha256或sha512等算法。
可以一定程度打散整个数据集,但是不利于 Scan;比如我们使用 md5 算法,来计算Rowkey的md5值,然后截取前几位的字符串。subString(MD5(设备ID), 0, x) + 设备ID,其中x一般取5或6。
3)Reversing
Reversing 的原理是反转一段固定长度或者全部的键。以手机举例,可以将手机号反转后的字符串作为Rowkey,这样的就避免了以手机号那样比较固定开头(13x、15x等)导致热点问题,这样做的缺点是牺牲了Rowkey的有序性。
但比如rowkey为url时,通过反转可以让同一域名的URL存放在一起(因为url中前面的数据可能不一致)
摘自:https://blog.csdn.net/young_0609/article/details/85373487
https://mp.weixin.qq.com/s?__biz=MzA5MTc0NTMwNQ==&mid=2650716225&idx=1&sn=a5f64dfeb5e7cd42913bc8e8e955b472&chksm=887da537bf0a2c2173b815a25acc5c11b1120830b8592408d950caeef54672728500044b7437&scene=21#wechat_redirect