语音识别数据集-TIMIT数据集-中文超详细解析
TIMIT数据集
前言
该文章会详细介绍TIMIT数据集的文件组成、内部文件格式以及如何使用TIMIT数据集。同时还会介绍TIMIT是如何组织数据以及划分训练集与测试集的,可以为今后自己构建数据集提供一种思路。
关键词:TIMIT数据集、语音识别、音素、人工音频标签;
文件
基本信息
- 大小:约650MB
- 创建时间:1986年1月至5月
组织形式
/语料库/用处/方言地区/性别+说话者ID/句子ID.文件类型
- 语料库:TIMIT
- 用处:DOC、TEST、TRAIN
- 方言地区:DR1~DR8
- 性别:F/M
- 说话者ID:3大写字母+1阿拉伯数字
- 句子ID:句子类型(SA/SI/SX)+编号
- 文件类型:wav、txt、wrd、phn
详细介绍请看下文。
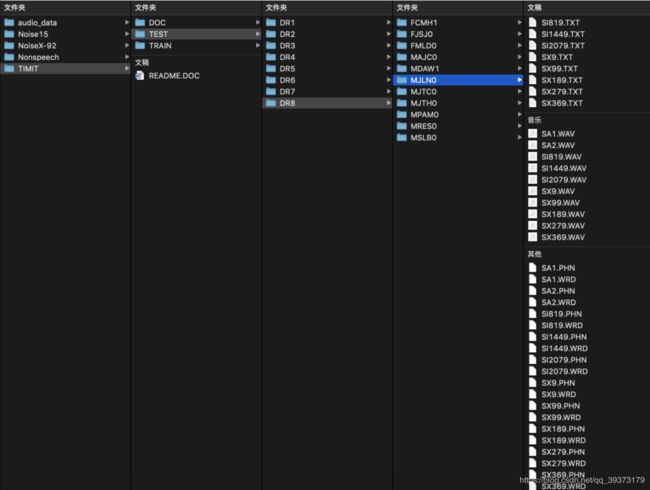
大致结构
| 一级目录 | 二级目录 | 三级目录 |
|---|---|---|
| /TIMIT | /DOC | @包含文档 |
| /TEST | /DR1~/DR8 | |
| /TRAIN | /DR1~/DR8 | |
| README.DOC |
@包含文档
prompts.txt(10/31/88):包含所有句子的文本内容+句子种类编号。eg.【She had your dark suit in greasy wash water all year. (sa1)】
spkrinfo.txt(10/15/90):包含所有说话者的信息。
spkrsent.txt(10/15/90):包含每个说话人说的句子号。
timitdic.txt(10/12/90):TIMIT句子中每个单词的音素标识符。
phonecode.doc(10/12/90):说明音素标识规则。
timitdic.doc(10/11/90):说明音素规则。
testset.doc(10/11/90):测试集&划分规则。
内容
背景&开发者
TIMIT语料库是为声学语音知识的获取(模型训练)以及自动语音识别系统(ASR)的评估(模型测试)而构建的,是由国防部赞助,在研究计划署(DARPA-ISTO)、麻省理工学院(MIT)、斯坦福研究院(SRI)、德州仪器(TI)共同努力下完成。
TIMIT= TI+MIT,德州仪器+麻省理工大学? //猜测
包含:6300个句子。
说话人信息
由来自美国8个主要方言地区的630位说话者讲10个句子构成。
说话人分布如下:
| Region(dr) | Male | Female | Total |
|---|---|---|---|
| 1 | 31 (63%) | 18 (27%) | 49 (8%) |
| 2 | 71 (70%) | 31 (30%) | 102 (16%) |
| 3 | 79 (67%) | 23 (23%) | 102 (16%) |
| 4 | 69 (69%) | 31 (31%) | 100 (16%) |
| 5 | 62 (63%) | 36 (37%) | 98 (16%) |
| 6 | 30 (65%) | 16 (35%) | 46 (7%) |
| 7 | 74 (74%) | 26 (26%) | 100 (16%) |
| 8 | 22 (67%) | 11 (33%) | 33 (5%) |
| Total | 438 (70%) | 192 (30%) | 630 (100%) |
区域代号:
- dr1: New England
- dr2: Northern
- dr3: North Midland
- dr4: South Midland
- dr5: Southern
- dr6: New York City
- dr7: Western
- dr8: Army Brat (moved around)
地图:
说话人详细信息
位置:TIMIT/DOC/spkrinfo.txt
- ID:三个大写字母+一位阿拉伯数字
- 性别Sex:M男/F女
- 地区DR:DR1~DR8,见上文。
- 用途Use:
- TRN:用于系统训练
- TST:用于系统测试
- 录制日期RecDate:月/日/年
- 生日BirthDate:月/日/年
- 身高Ht:x’y"-x英尺y英寸
- 人种Race:
- WHT-白种人
- BLK-黑种人
- AMR(American Indian)-美洲印第安人
- SPN(Spanish-American)-西班牙裔美国人
- ORN(Oriental)-东方人
- ???-未知
- 受教育水平Edu
- HS-高中
- AS(Associate Degree)-大专
- BS-学士
- MS-硕士
- PHD-博士
- ??-未知
- 其他Comment:一些个性介绍,eg.【CONCIOUS ATTEMPT TO CHANGE ACCENT,有意识地改变口语】
通过统计可发现,TIMIT数据集的说话人大部分为白人男性。
句子信息
TIMIT设计了三类句子供说话者读:
- SA-方言句子(Dialect sentence):由SRI设计,总共2句。每个人都会读SA1、SA2这两个句子,体现不同地区方言的差别。(因此可用于方言判断算法的数据集,而其他情况一般不用该类句子)
- SX-音素紧凑的句子(Phondtically-compact sentence):由MIT设计,总共450句,目的是让句子中的音素分布平衡,尽可能的包含所有音素对。每个人读5个SX句子,并且每个SX句子被7个不同的人读。
- SI-音素发散的句子(Phonetically-diverse sentence):由TI在现有语料库Brown Corpus与剧作家对话集(the Playwrights Dialog)挑选的,总共1890句。目的是增加句子类型和音素文本的多样性,使之尽可能的包括所有的等位语境(Allophonic context)。每个人读三个SI句子,并且每个SI句子仅被一个人读一次。
| 句子种类 | 句子个数 | 单句/人 | 总读句子数 | 句子数/人 |
|---|---|---|---|---|
| SA | 2 | 630 | 1260 | 2 |
| SX | 450 | 7 | 3150 | 5 |
| SI | 1890 | 1 | 1890 | 3 |
音素(Phone)
是根据语音的自然属性划分出的最小语音单位。
汉语中对应拼音:eg【我:wo-w、o】两个音素。
英语中对应音标:eg【she:sh、iy】两个音素。
TIMIT在设计之初为了充分考虑发音的多样性,以及向下兼容性,所以推出了含有52个音素、6个闭包以及5个标识符的音素表示。
下面按照音素符号、样例词、以及可能的音素标签来展示。
Stops爆破音:
b bee BCL B iy
d day DCL D ey
g gay GCL G ey
p pea PCL P iy
t tea TCL T iy
k key KCL K iy
dx muddy, dirty m ah DX iy, dcl d er DX iy
q bat bcl b ae Q
Affricates破擦音:
jh joke DCL JH ow kcl k
ch choke TCL CH ow kcl k
Fricatives摩擦音:
s sea S iy
sh she SH iy
z zone Z ow n
zh azure ae ZH er
f fin F ih n
th thin TH ih n
v van V ae n
dh then DH e n
Nasals:鼻音
m mom M aa M
n noon N uw N
ng sing s ih NG
em bottom b aa tcl t EM
en button b ah q EN
eng washington w aa sh ENG tcl t ax n
nx winner w ih NX axr
Semivowels and Glides半元音与滑音:
l lay L ey
r ray R ey
w way W ey
y yacht Y aa tcl t
hh hay HH ey
hv ahead ax HV eh dcl d
el bottle bcl b aa tcl t EL
Vowels元音:
iy beet bcl b IY tcl t
ih bit bcl b IH tcl t
eh bet bcl b EH tcl t
ey bait bcl b EY tcl t
ae bat bcl b AE tcl t
aa bott bcl b AA tcl t
aw bout bcl b AW tcl t
ay bite bcl b AY tcl t
ah but bcl b AH tcl t
ao bought bcl b AO tcl t
oy boy bcl b OY
ow boat bcl b OW tcl t
uh book bcl b UH kcl k
uw boot bcl b UW tcl t
ux toot tcl t UX tcl t
er bird bcl b ER dcl d
ax about AX bcl b aw tcl t
ix debit dcl d eh bcl b IX tcl t
axr butter bcl b ah dx AXR
ax-h suspect s AX-H s pcl p eh kcl k tcl t
Closure闭包:
b b clouse
d d clouse
g g clouse
p p clouse
t t clouse
k k clouse
Others其他:
pau pause
epi epenthetic silence
h# begin/end marker (non-speech events)
1 primary stress marker(重音1)
2 secondary stress marker(重音2)
而实际上研究者发现所使用的音素过于复杂,因而会简化一些,因而在训练时有些研究者整合为48个音素,当评估模型时,李开复在他的成名作(Lee & Hon, 1989)所提出的将61个音素合并为39个音素方法被广为使用。
以下是基于TIMIT数据库上进行语音识别实验的研究成果。

TIMIT文件种类
.WAV文件
TIMIT里的波形文件虽然是WAV文件后缀,但其实不是真正的wav文件,所以不能够直接打开。
实际文件格式:NIST SPHERE 16bit PCM文件
采样率:16kHz
比特位数:16bits
通道数:mono单通道
SPHERE介绍:该文件设计的意义是能够在各种设备直接传输语音信号数据,尤其是CD-ROM。文件前有1024Byte的文件头
并且NIST提供了C语音函数来对SPHERE文件进行操作。
现在也可以用Audition软件或者Matlab Audioread函数来进行文件读取。

.TXT文件
记录了音频文件的开始样本点,结束样本点以及句子文本。
eg【0 63488 She had your dark suit in greasy wash water all year.】
.PHN文件
手工标定的音素标签,定位每一个音素开始边界、语结束边界的样本点。
eg【
0 9640 h#
9640 11240 sh
11240 12783 iy
12783 14078 hv
14078 16157 ae
16157 16880 dcl
…
52378 54500 ao
54500 55461 l
55461 57395 y
57395 59179 iy
59179 60600 axr
60600 63440 h#
】
TIMIT开发者也在免责声明(Disclaimer)里说:“Phonetic transcriptions are inherently extremely subjective;” 但由于该标签是他们投入了大量人力、广泛接受各方建议以及经过MIT使用SPIRE system检查后得出的。所以是高度可信的。但他们同样建议可以针对自己需要开发的项目自己做标签。
.WRD
以音素的标签为输入,使用自动词标签标注程序进行词标签的标注。实验表明使用程序标注的词边界在4000个相同样本下获得了与人工标签96%的默契度。说明该标签是可用的。
eg【
9640 12783 she
12783 17103 had
17103 18760 your
18760 24104 dark
24104 29179 suit
29179 31880 in
31880 38568 greasy
38568 45119 wash
45624 51033 water
52378 55461 all
55461 60600 year
】
可以看出词的边界是由音素的边界合成的,比如she:[9640-12783] = sh:[9640-11240] + iy: [11240-12783]
边界标定细节可看我这篇文章:TIMIT数据集-语音人工标签-波形频谱可视化展示
训练集&测试集的划分
划分原则
1、大约20%~30%为测试集、70%~80%为训练集。
2、不能有说话者既出现在训练集又出现在测试集中。
3、在测试集与训练集中至少存在每个方言区的1男1女。
4、测试集与训练集的交集必须最小,最好没有交集。
5、测试集中必须涵盖所有音素,并且最好在不同语境中出现多次。
根据上述原则,TIMIT划分出了核心测试集(Core Test Set),8个地区,每个地区选择2男1女,每个说话者说5个不同的SX句子,3个IS句子。总共3人x8句x8地区=192句子。
地区 男性 女性
1 DAB0, WBT0 ELC0
2 TAS1, WEW0 PAS0
3 JMP0, LNT0 PKT0
4 LLL0, TLS0 JLM0
5 BPM0, KLT0 NLP0
6 CMJ0, JDH0 MGD0
7 GRT0, NJM0 DHC0
8 JLN0, PAM0 MLD0
由于核心测试集的数据量太少,官方不建议是用该测试集对系统进行性能测试。
进一步地,利用核心测试集构建完全测试集(Complete Test Set)。构建原则是:将所有与核心测试集里的人读过相同SX句子的人纳入完全测试集中,这样可避免同一个句子既出现在测试集中,又出现在训练集中。而因为一个SX句子被7个人读,所以其他6人必须被放入完全测试集中。
最终构建的完全测试集的分布为:
| 地区 | 男性 | 女性 | 总计 |
|---|---|---|---|
| 1 | 7 | 4 | 11 |
| 2 | 18 | 8 | 26 |
| 3 | 23 | 3 | 26 |
| 4 | 16 | 16 | 32 |
| 5 | 17 | 11 | 28 |
| 6 | 8 | 3 | 11 |
| 7 | 15 | 8 | 23 |
| 8 | 8 | 3 | 11 |
| 总计 | 112 | 56 | 168 |
该测试集占全体说话人的27%,有120句不同的SX句子,504个不通的SI句子,共1344个句子。官方推荐使用完全测试集进行性能测试。
语音时长分布:
| 类别 | 说话人个数 | 句子个数 | 总时长 |
|---|---|---|---|
| 训练集 | 462 | 3696 | 3.14 |
| 核心测试集 | 24 | 192 | 0.16 |
| 完全测试集 | 168 | 1344 | 0.81 |
结语
TIMIT数据集至今已有30余年的历史了,已然成为语音识别领域的标准,并运用甚广。
原因是:
1、TIMIT的数据库手动标注详细到音素,说话人来自美国各个地方,并且提供了详细的说话人信息比如人种、学历甚至于身高。
2、数据集相对较小,可以短时间完成实验,同时测试系统性能。
参考资料
TIMIT官方文档
TIMIT官网
DARPA TIMIT文档
CSDN博客:TIMIT数据库