大数据与机器学习 基础篇 分类 隐马尔可夫模型
分类算法是机器学习中的一个重点,也是人们常说的“有监督的学习”。这是一种利用一系列已知类别的样本来对模型进行训练调整分类器的参数,使其达到所要求性能的过程,也成为监督训练或有教师学习。
注:本文中用到的Python及其模块安装教程参见
隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)最初由L. E. Baum发表在20世纪70年代一系列的统计学论文中,随后在语言识别,自然语言处理以及生物信息等领域体现了很大的价值。
首先提出马尔可夫链的概念:
- 在观察一个系统变化的时候,它下一个状态(第n+1个状态)如何的概率只需要观察和统计当前状态(第n个状态)即可正确得出。
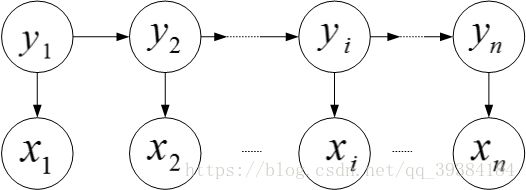
如果在一个完整的观察过程中有一些状态的转换,如下图中的 y1 y 1 到 yn y n 。在观察中 y1 y 1 到 yn y n 的状态存在一个客观的转化规律,但是没办法直接观测到,观测到的是每个 y y 状态下的输出 x x ,即 x1 x 1 到 xn x n 。需要通过 x1 x 1 到 xn x n 这些输出值来进行模型建立和计算状态转移概率。
- 隐马尔可夫链示意图:
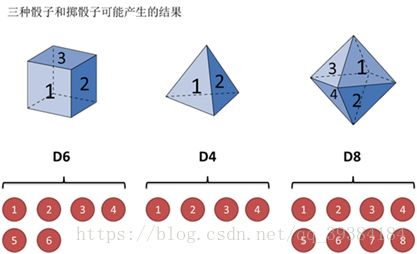
为了比较容易理解整个过程,下面举一个例子,假设有3中不同的骰子:
.
第一个骰子是常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是 16 1 6 。
.
第二个骰子是一个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是 14 1 4 。
.
第三个骰子有8个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是 18 1 8 。
- 三种骰子和掷骰子可能产生的结果:
先随机选择一个骰子,然后再用它掷出一个数字,并记录下这个选择和数字。先从三个骰子里挑一个,挑到每个骰子的概率都是 13 1 3 。然后掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停地重复上述过程,会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。
.
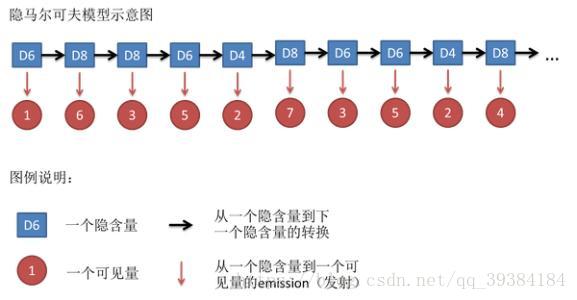
例如,投掷骰子10次,可能得到这么一串数字:1,6,3,5,2,7,3,5,2,4,这串数字叫做可见状态链,也就是记录的这组数字,可是前面介绍的 xn x n 。但是在隐马尔可夫模型中,不仅有可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是选出的骰子的序列。例如本次中,隐含状态链是:D6,D8,D8,D6,D4,D8,D6,D6,D4,D8,如下图所示:
- 隐马尔可夫模型示意图:
一般来说,HMM中的马尔科夫链就是指隐含状态链,因为实际是隐含状态之间存在转换概率(Transition Probability)。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,进行模拟是相当容易的。但应用HMM模型时,往往缺失一部分信息,有时候知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候只是看到了很多次掷骰子的结果,剩下的什么都不知道。如何应用算法去估计这些缺失的信息,就成了一个很重要的问题。
和HMM模型相关的算法主要分为3类,分别解决3中问题:
- 问题1:知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题在语音识别领域叫做解码问题。这个问题其实有两种解法,会给出两个不同的答案。每个答案都正确,只是这些答案的意义不一样。第一种解法求最大似然状态路径,通俗地说,就是求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法不是求一组骰子序列,而是求每次掷出的骰子分别是某种骰子的概率。
例如,看到结果后,可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2。
- 问题2:知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),想知道掷出这个结果的概率。
这个问题看似意义不大,因为掷出来的结果很多时候都对应了一个比较大的概率。这个问题的目的其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么说明已知的模型很有可能是错的,有人偷偷把骰子换了。
- 问题3:知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),想反推出每种骰子是什么(转换概率)。这个问题很重要,因为这是最常见的情况。很多时候只有可见结果,不知道HMM模型中的参数,需要从可见结果估计出这些参数,这是建模的一个必要步骤。
维特比算法
维特比算法用于解决前面提到的问题1的解最大似然路径的问题。
还是考虑上面的例子:
首先掷一次骰子,结果为1,此时对应的最大概率骰子序列就是D4,因为D4产生1的概率是 14 1 4 ,高于 16 1 6 和 18 1 8 。
.
把这个情况扩展,掷两次骰子,结果分别为1,6。这是问题变得复杂起来,要计算3个值,分别是第二个骰子是D4,D6,D8的最大概率。显然,要取得最大概率,第一个骰子必须为D4,此时,第二个骰子取到D6的最大概率如下:
P2(D6) P 2 ( D 6 )
=P(D4)∗(1|D4)∗(D6|D4)∗P(6|D6) = P ( D 4 ) ∗ ( 1 | D 4 ) ∗ ( D 6 | D 4 ) ∗ P ( 6 | D 6 )
=13∗14∗13∗16=1216 = 1 3 ∗ 1 4 ∗ 1 3 ∗ 1 6 = 1 216
同样的,可以计算第二个骰子是D4或D8时的最大概率。发现,第二个骰子取到D6的概率最大。而使这个概率最大时,第一个骰子为D4。所以最大概率骰子序列就是D4,D6。
.
继续扩展,掷三次骰子,计算第三个骰子分别是D4,D6,D8的最大概率。再次发现,要取到最大概率,第二个骰子必须为D6。这时,第三个骰子取到D4的最大概率如下:
P3(D4) P 3 ( D 4 )
=P2(D6)∗P(D4|D6)∗P(3|D4) = P 2 ( D 6 ) ∗ P ( D 4 | D 6 ) ∗ P ( 3 | D 4 )
=1216∗13∗14=12592 = 1 216 ∗ 1 3 ∗ 1 4 = 1 2592
和计算两个骰子序列概率的方法一样,还可以计算第三个骰子是D6或D8时的最大概率。可以发现,第三个骰子取D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。
.
既然掷骰子1到3次可以算,掷多少次都可以,以此类推。
- 可以发现,要求最大概率骰子序列时要做下面几件事情:
首先,不管序列多长,要从序列长度为1算起,算序列的长度为1时取到每个骰子的最大概率。然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下取到每个骰子的最大概率都算过了,重新计算其实不难。当算到最后一位时,就知道最后一位哪个骰子的概率最大了。然后,要把对应这个最大概率的序列从后往前推出来。这就是在刚刚掷骰子的例子中展示出的完整维比特算法。
维特比算法应用——打字提示功能
维比特算法研究的是一种链的可能性问题。现在应用最广的领域是打字提示功能。
在Windows中能够使用的输入法有很多种,在这里以全拼为例。在使用输入法时,输入的是英文字母,在这个应用中,隐藏的序列时真实要输入的中文字符和词汇,显示的部分是输入的英文字符。

在输入jin时,输入法软件会猜测想要输入“近”,“斤”,“今”等。而这种排序不是瞎猜的,通常是根据统计数据而来。也就是说“近”,“斤”,“今”这样的顺序一般是根据使用人的输入习惯形成的——在平时打字聊天的过程中“近”出现在词汇或句子输入开始的概率大于“斤”,而“斤”大于“今。
但是输入了tian时就不一样了。“今天”作为一个词汇,比其他任何一个被拼作jintian的词汇都使用得更为高频。也可以理解为,当输入tian时,由jin(今)到tian(天)这条路径的概率是最高的,这是把“今天”这个词汇放在第一个的原因。
后面输入了几个其他的完整词汇:“我们”,“应该”,“做些”,“什么”,输入法也会继续对这些词汇在句子中的路径概率进行计算,每次输入都会猜测一次到目前的输入状态为止最有可能的那条路径,那么看到的这个第一顺位的词汇,准确说是一个句子——“今天我们应该做些什么”就是猜测到的最优的结果,它比任何一种路径产生的概率都要高。
在具体操作的时候,这个马尔可夫模型的训练(拼音串的输入与最终产生汉字串的输出)应该来源于本地的输入者的习惯和互联网的结合。
下面模拟输入法的猜测方法给出一个算法示例,先给出各级转换矩阵,如下表:
- 表1 jin概率矩阵:
| jin | 概率 |
|---|---|
| 近 | 0.3 |
| 斤 | 0.2 |
| 今 | 0.1 |
| 金 | 0.06 |
| 尽 | 0.03 |
- 表2 jin-tian转移矩阵:
| jin-tian | 天 | 填 | 田 | 甜 | 添 |
|---|---|---|---|---|---|
| 近 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| 斤 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| 今 | 0.990 | 0.001 | 0.001 | 0.001 | 0.001 |
| 金 | 0.001 | 0.001 | 0.850 | 0.001 | 0.001 |
| 尽 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
- 表3 wo概率矩阵:
| wo | 概率 |
|---|---|
| 我 | 0.400 |
| 窝 | 0.150 |
| 喔 | 0.090 |
| 握 | 0.050 |
| 卧 | 0.030 |
- 表2 wo-men转移矩阵:
| wo—men | 们 | 门 | 闷 | 焖 | 扪 |
|---|---|---|---|---|---|
| 我 | 0.970 | 0.001 | 0.003 | 0.001 | 0.001 |
| 窝 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| 喔 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| 握 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| 卧 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
在输入一个完整拼音后,用户就会按回车或数字把输入备选框中的汉字输出,当单字词输出时就会由统计产生“jin概率矩阵”和“wo概率矩阵”这样的统计结果,而当用户输入的是一个双字词是就会产生“jin-tian转移矩阵”和“wo-men转移矩阵”这样的统计结果。而且每个双字词,三字词等的输入统计都用这种方法。在输入双字词汉字拼音时会根据转移概率表进行计算。多个词相连就是多个转移矩阵的概率相乘计算,从而得到概率最大的输入可能项。
.
示例代码如下:
#维特比算法模拟输入法
import numpy as np
jin=['近','斤','今','金','尽']
jin_per=[0.3,0.2,0.1,0.06,0.03]
jintian=['天','填','田','甜','添']
jintian_per=[
[0.001,0.001,0.001,0.001,0.001],
[0.001,0.001,0.001,0.001,0.001],
[0.099,0.001,0.001,0.001,0.001],
[0.002,0.001,0.085,0.001,0.001],
[0.001,0.001,0.001,0.001,0.001]
]
wo=['我','窝','喔','握','卧']
wo_per=[0.400,0.150,0.090,0.050,0.030]
women=['们','门','闷','焖','扪']
women_per=[
[0.970,0.001,0.003,0.001,0.001],
[0.001,0.001,0.001,0.001,0.001],
[0.001,0.001,0.001,0.001,0.001],
[0.001,0.001,0.001,0.001,0.001],
[0.001,0.001,0.001,0.001,0.001]
]
N=5
def found_from_oneword(oneword_per):
index=[]
values=[]
a=np.array(oneword_per)
for v in np.argsort(a)[::-1][:N]:
index.append(v)
values.append(oneword_per[v])
return index,values
def found_from_twoword(oneword_per,twoword_per):
last=0
for i in range(len(oneword_per)):
current=np.multiply(oneword_per[i],twoword_per[i])
if i==0:
last=current
else:
last=np.concatenate((last,current),axis=0)
index=[]
values=[]
for v in np.argsort(last)[::-1][:N]:
index.append([v//5,v%5])
values.append(last[v])
return index,values
def perdict(word):
if word=='jin':
for i in found_from_oneword(jin_per)[0]:
print(jin[i])
elif word=='jintian':
for i in found_from_twoword(jin_per,jintian_per)[0]:
print(jin[i[0]]+jintian[i[1]])
elif word=='wo':
for i in found_from_oneword(wo_per)[0]:
print(wo[i])
elif word=='women':
for i in found_from_twoword(wo_per,women_per)[0]:
print(wo[i[0]]+women[i[1]])
elif word=='jintianwo':
index1,values1=found_from_oneword(wo_per)
index2,values2=found_from_twoword(jin_per,jintian_per)
last=np.multiply(values1,values2)
for i in np.argsort(last)[::-1][:N]:
print(jin[index2[i][0]]+jintian[index2[i][1]]+wo[i])
elif word=='jintianwomen':
index1,values1=found_from_twoword(jin_per,jintian_per)
index2,values2=found_from_twoword(wo_per,women_per)
last=np.multiply(values1,values2)
for i in np.argsort(last)[::-1][:N]:
print(jin[index1[i][0]]+jintian[index1[i][1]]+wo[index2[i][0]]+women[index2[i][1]])
else:
pass
if __name__=='__main__':
print('jin:')
perdict('jin')
print('jintian:')
perdict('jintian')
print('wo:')
perdict('wo')
print('women:')
perdict('women')
print('jintianwo:')
perdict('jintianwo')
print('jintianwomen:')
perdict('jintianwomen')根据算法,示例输入“jin”,“jintian”,“wo”,“women”,“jintianwo”和“jintianwomen”时的排序输出为:
jin:
近
斤
今
金
尽
jintian:
今天
金田
近天
近填
近田
wo:
我
窝
喔
握
卧
women:
我们
我闷
我门
我焖
我扪
jintianwo:
今天我
金田窝
近天喔
近填握
近田卧
jintianwomen:
今天我们
金田我闷
近田我扪
近填我焖
近天我门
在实际应用过程中,这个概率矩阵会是一个系数矩阵。而且转移概率足够小,如小于0.001时可以认为是输入统计中的噪声点,不进行词汇输入推荐,这样输入备选框的前面也只会出现高频输入词汇,这样备选框比较简洁。
想了解更多关于大数据和机器学习:大数据与机器学习专栏