【计算机视觉】详解分类任务的视觉注意力:SENet、CBAM、SKNet (视觉注意力机制 (二))
绪论
视觉注意力机制 (一) 主要关注了视觉应用中的 Self-attention 机制及其应用 —— Non-local 网络模块 ,从最开始的了解什么是视觉注意力机制到对自注意力机制的细节把握,再到 Non-local 模块的学习。而本文主要关注视觉注意力机制在分类网络中的应用 —— SENet、SKNet、CBAM 。
通常,将软注意力机制中的模型结构分为三大注意力域来分析:空间域、通道域、混合域。
- 空间域 —— 将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。对空间进行掩码的生成,进行打分,代表是 Spatial Attention Module。
- 通道域 —— 类似于给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高。对通道生成掩码 mask,进行打分,代表是 SENet, Channel Attention Module。
- 混合域 —— 空间域的注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。
而通道域的注意力是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息,这种做法其实也是比较暴力的行为。所以结合两种思路,就可以设计出混合域的注意力机制模型。同时对通道注意力和空间注意力进行评价打分,代表的有BAM, CBAM。
下面,将主要介绍视觉注意力机制在分类网络中的应用。
一、Squeeze-and-Excitation Networks (SENet)
论文地址:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
SENet (Squeeze-and-Excitation Networks),由 Momenta 发表于 CVPR 2017,论文中的 SENet 赢得了 ImageNet 最后一届(2017) 的图像识别冠军,论文的核心点在对 CNN 中的 feature channel (特征通道依赖性) 利用和创新。提出的 SE 模块思想简单,易于实现,并且很容易可以加载到现有的网络模型框架中。SENet 主要是通过显式地建模通道之间的相互依赖关系,自适应地重新校准通道的特征响应,换句话说,就是学习了通道之间的相关性,筛选出了针对通道的注意力,整个网络稍微增加了一点计算量,但是效果比较好。

上图是 SENet 的 Block 单元,图中的 Ftr 是传统的卷积结构,X 和 U 是 Ftr 的输入 (C'×H'×W') 和输出 (C×H×W),这些都是以往结构中已存在的。
SENet 增加的部分是 U 后的结构:对 U 先做一个 Global Average Pooling(图中的Fsq(.),作者称为 Squeeze 过程),输出的 1×1×C 数据再经过两级全连接(图中的Fex(.),作者称为 Excitation 过程),最后用 sigmoid(论文中的 self-gating mechanism)限制到 [0, 1] 的范围,把这个值作为 scale 乘到 U 的 C 个通道上, 作为下一级的输入数据。
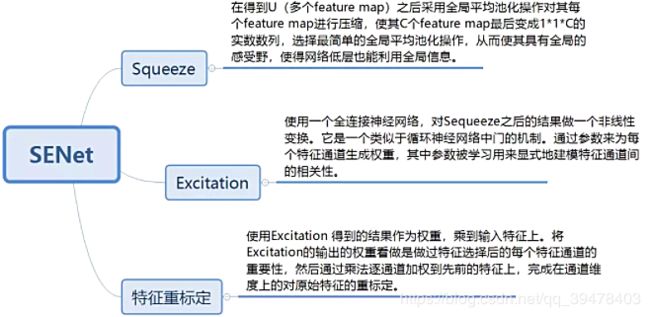
这种结构的原理是想通过控制 scale 的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
通俗的说就是:通过对卷积的到的 feature map 进行处理,得到一个和通道数一样的一维向量作为每个通道的评价分数,然后将改分数分别施加到对应的通道上,得到其结果,就在原有的基础上只添加了一个模块。

这是文中给出的一个嵌入Inception结构的一个例子。由(H×W×C)全局平均池化得到(1×1×C),即 S 步;接着利用两个全连接层和相应的激活函数建模通道之间的相关性,即 E 步。E 步中包含参数 r 的目的是为了减少全连接层的参数。输出特征通道的权重通过乘法逐通道加权到原来的特征上,得到(H×W×C)的数据,与输入形状完全相同。
以下是基于Pytorch的代码实现:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)二、Convolutional Block Attention Module (CBAM)
论文地址:http://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
在该论文中,作者研究了网络架构中的注意力,注意力不仅要告诉我们重点关注哪里,还要提高关注点的表示。目标是通过使用注意机制来增加表现力,关注重要特征并抑制不必要的特征。为了强调空间和通道这两个维度上的有意义特征,作者依次应用通道和空间注意模块,来分别在通道和空间维度上学习关注什么、在哪里关注。此外,通过了解要强调或抑制的信息也有助于网络内的信息流动。

上图为整个 CBAM 的示意图,先是通过注意力机制模块,然后是空间注意力模块,对于两个模块先后顺序对模型性能的影响,本文作者也给出了实验的数据对比,先通道再空间要比先空间再通道以及通道和空间注意力模块并行的方式效果要略胜一筹。
那么这个通道注意力模块和空间注意力模块又是如何实现的呢?
- 通道注意力模块

这个部分大体上和 SENet 的注意力模块相同,主要的区别是 CBAM 在 S 步采取了全局平均池化以及全局最大池化,两种不同的池化意味着提取的高层次特征更加丰富。接着在 E 步同样通过两个全连接层和相应的激活函数建模通道之间的相关性,合并两个输出得到各个特征通道的权重。最后,得到特征通道的权重之后,通过乘法逐通道加权到原来的特征上,完成在通道维度上的原始特征重标定。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout) - 空间注意力模块
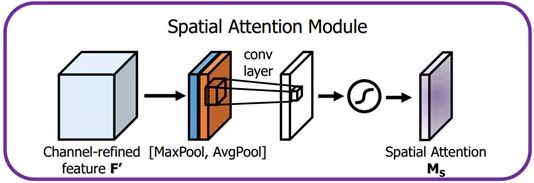
首先输入的是经过通道注意力模块的特征,同样利用了全局平均池化和全局最大池化,不同的是,这里是在通道这个维度上进行的操作,也就是说把所有输入通道池化成2个实数,由(h×w×c)形状的输入得到两个(h×w×1)的特征图。接着使用一个 7×7 的卷积核,卷积后形成新的(h×w×1)的特征图。最后也是相同的Scale操作,注意力模块特征与得到的新特征图相乘得到经过双重注意力调整的特征图。
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x) 网络整体代码:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out 三、Selective Kernel Networks (SKNet)
论文地址:https://arxiv.org/abs/1903.06586
代码地址:https://github.com/implus/SKNet
Selective Kernel Networks(SKNet)发表在 CVPR 2019,是对 Momenta 发表于 CVPR 2018 上论文 SENet 的改进,且这篇的作者中也有 Momenta 的同学参与。
SENet是对特征图的通道注意力机制的研究,之前的 CBAM 提到了对特征图空间注意力机制的研究。这里 SKNet 针对卷积核的注意力机制研究。
不同大小的感受视野(卷积核)对于不同尺度(远近、大小)的目标会有不同的效果。尽管比如 Inception 这样的增加了多个卷积核来适应不同尺度图像,但是一旦训练完成后,参数就固定了,这样多尺度信息就会被全部使用了(每个卷积核的权重相同)。
SKNet 提出了一种机制,即卷积核的重要性,即不同的图像能够得到具有不同重要性的卷积核。
据作者说,该模块在超分辨率任务上有很大提升,并且论文中的实验也证实了在分类任务上有很好的表现。
SKNet对不同图像使用的卷积核权重不同,即一种针对不同尺度的图像动态生成卷积核。整体结构如下图所示:
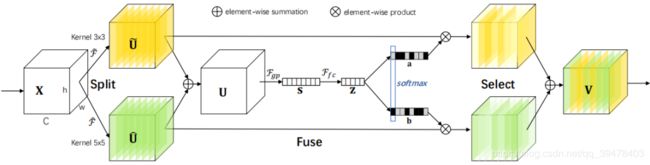

网络主要由Split、Fuse、Select三部分组成。
-
Split 部分是对原特征图经过不同大小的卷积核部分进行卷积的过程,这里可以有多个分支。
对输入X使用不同大小卷积核分别进行卷积操作(图中的卷积核 size 分别为 3x3 和 5x5 两个分支,但是可以有多个分支)。操作包括卷积、efficient grouped / depth-wise convolutions、BN。
-
Fuse 部分是计算每个卷积核权重的部分。
将两部分的特征图按元素求和
![]()
U 通过全局平均池化(GAP)生成通道统计信息。得到的 Sc 维度为 C×1

经过全连接生成紧凑的特征z(维度为 d×1), δ 是 RELU 激活函数,B 表示批标准化(BN),z 的维度为卷积核的个数,W 维度为 d×C, d 代表全连接后的特征维度,L 在文中的值为32,r 为压缩因子。
![]()
![]()
-
Select 部分是根据不同权重卷积核计算后得到的新的特征图的过程。
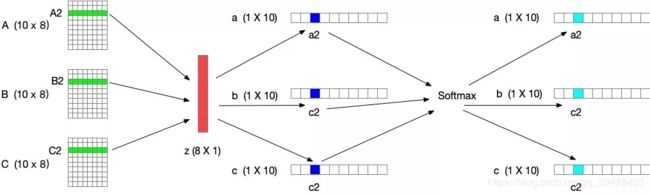
进行 softmax 计算每个卷积核的权重,计算方式如下图所示。如果是两个卷积核,则 ac + bc = 1。z的维度为(d×1)A的维度为(C×d),B的维度为(C×d),则 a = A×z 的维度为1×C。
Ac、Bc 为 A、B 的第 c 行数据(1×d)。ac 为 a 的第 c 个元素,这样分别得到了每个卷积核的权重。
![]()
将权重应用到特征图上。其中 V = [V1,V2,...,VC],Vc 维度为(H×W),如果
![]()
select 中 softmax 部分可参考下图(3个卷积核)
下图是针对 SKNet 总结的思维导图
参考地址:https://blog.csdn.net/qq_34784753/article/details/89381947?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task

基于pytorch的代码实现:
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1, L=32):
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
# 使用不同kernel size的卷积
self.convs.append(
nn.Sequential(
nn.Conv2d(features,
features,
kernel_size=3 + i * 2,
stride=stride,
padding=1 + i,
groups=G), nn.BatchNorm2d(features),
nn.ReLU(inplace=False)))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(nn.Linear(d, features))
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)
fea_s = fea_U.mean(-1).mean(-1)
fea_z = self.fc(fea_s)
for i, fc in enumerate(self.fcs):
print(i, fea_z.shape)
vector = fc(fea_z).unsqueeze_(dim=1)
print(i, vector.shape)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector],
dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v 文献来源:https://mp.weixin.qq.com/s?__biz=MzI0NDYxODM5NA==&mid=2247483866&idx=1&sn=b5502cface8c0fa92b57e5a6315beda7&chksm=e95a442fde2dcd397ebfc93e798bac76cc46fcde7bc8384bc323718202938130f292cc4b5076&mpshare=1&scene=1&srcid=&sharer_sharetime=1583075183126&sharer_shareid=0b429a7aa924e4344b9d5fd5c73b6d29&key=89c13119caee7b328f702721606c906d642d320e8d90cff01fc770b257764d8645ae04ac63a86634f67e6d31695bf7e206e3510dc4bf1ee970b377d04e5b99c188615aa2188d1f3aa730f11a39edcf25&ascene=1&uin=MTk5MDczMzUxNQ%3D%3D&devicetype=Windows+10&version=62070158&lang=zh_CN&exportkey=A2%2Byk8QLRMAcpz%2BhBXT5cjA%3D&pass_ticket=ZcygqOXDiQVxPAnTIUZ2owaEAaDvtM%2FJtdr1GWANsFucjah5SKsspKXzFeYeL2sp