MySQL中的关键字用法(一)
MySQL中关键字的用法(一)
Insert:增加
insert into * values()
insert into user values(‘11’,‘诸葛亮’,‘1011’);
不多解释,向表中添加一条语句,不清楚的去看MySQL的简单的增删改查
Delete:删除
delete from * where a=b;
delete from user where uuid=10
不多解释,在表中删除一条语句,不清楚的去看MySQL的简单的增删改查
Update:更新
update * set a=b where a=b;
update user a set a.username=‘我是修改后的’ where a.uuid=6;
不多解释,在表中更新一条语句,不清楚的去看MySQL的简单的增删改查
Select:查询
select * from a where a=b;
select * from user where uuid=1;
不多解释,在表中查询语句,不清楚的去看MySQL的简单的增删改查
truncate:删除表中数据
drop直接删掉表 truncate删除表中数据,再插入时自增长id又从1开始 delete删除表中数据,可以加where字句。
(1) DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2) 表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE 只能对TABLE;DELETE可以是table和view
(5) TRUNCATE 和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
Where:成立条件
涉及到数据库的带有条件的操作,基本都要有where关键字,一般用于数据库的删除和更新命令,具体用法便是“where 判断条件”;
查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
你可以在 WHERE 子句中指定任何条件。
你可以使用 AND 或者 OR 指定一个或多个条件。
WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
where a=b;
where a.uid=b.oid and a.uid=‘1011’;
where a.uid=‘1’ or b.oid=‘1’;

如果我们想在 MySQL 数据表中读取指定的数据,WHERE 子句是非常有用的。
使用主键来作为 WHERE 子句的条件查询是非常快速的。
如果给定的条件在表中没有任何匹配的记录,那么查询不会返回任何数据。
Like:模糊查找
我们知道查询数据库的时候用select关键字,我们也知道查询的条件跟在where关键字后面就可以,但是如果我们现在的查询条件比较模糊,我们想查询后缀是"mp4"的数据或者是想查询数据中含有“大大”的字眼的数据;这个时候准确查找就无法满足了,就需要用到模糊查找like关键字了;

*SQL LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 。
如果like 后没有使用%,那么和使用=作用是一样的;
select * from user a where a.username like '钟%'
执行前

执行后

我们可以看到并没有查出第11条数据,“钟%”这种形式只会查出以钟开头的字眼;“%钟”这种形式同样只会查出以钟结尾的字眼;“%钟%”则会查出在任何位置含有钟的数据;
union:联合,合并
当多个查询语句一起执行时,把这些查询的数据组合到一起时会出现重复的数据,这个时候就需要这个union关键字来进行联合查询;union关键字就是用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中,多个 SELECT 语句会删除重复的数据;
union是用来联合多条语句的,如果现在有一张用户表,每个客户都有买东西,这个时候要查出买了多少种类的东西,这个时候要单独用distinct关键字了,即
select count(distinct a.goods) from user a ;
原表:

select * from user a where a.username like ‘钟%’
union (distinct)
select * from user a where a.username like ‘%钟%’;
默认的union会去掉sql语句的相同的结果;union all会全部显示;distinct与不写结果相同;
union/union distinct 查询后的结果是

union all查询后的结果:
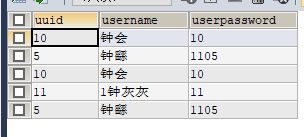
这样便会出现查询的所有结果,有重复数据;
效率问题
UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
1、对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
2、对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
distinct:不重复的
上满说到了union默认是和union distinct的作用一样,会将多个select查询语句的结果集进行合并;如果现在只有一个select语句,比如现在要统计一张商品表的商品的种类的个数,这个时候就要查询出种类这个字段不重复的记录,并计算;这个时候就要用distinct这个关键字了;
select count(distinct goods.class) from goods;
order by desc/asc :排序
将要显示的结果集进行排序,用order by关键字,末尾跟desc则是降序、跟asc则是升序;默认情况下是升序;
SELECT * FROM USER WHERE id>8891 ORDER BY id DESC;
Order by是排序;desc降序;asc升序;
SELECT field1, field2,…fieldN table_name1, table_name2…
ORDER BY field1, [field2…] [ASC [DESC]
你可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。
你可以设定多个字段来排序。
你可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
你可以添加 WHERE…LIKE 子句来设置条件。
group by:分组
group by关键字用来分组,根据一个或多个列对结果集进行分组
(count(*)计算个数的函数包含null值,count(属性)不包括null的值,
sum(属性)求和的函数
max(属性)用来求当前列的最大值)
我要只说这是用来分组的,可能有些模糊,可能很多人还是压根不懂这个到底是用来干啥的;好,那么我就按照我的理解来给大家详细的解释下这个分组group by到底该怎么用。
假如现在有这么一个人类表,我要将这个表按照男女来分开,计算一下男生多少人,女生多少人,以表格的形式显示出来?

你可能会想到select count() from people a where a.sex=1;这样分别来计算,得到的结果是这个样子的;

如果我想得到一个很友好的结果表:(如下图,查到这个样子的表是不是很友好,而且一目了然)
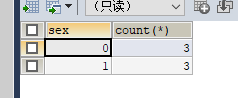
那么要怎么做呢?这个时候就要用到我们的group by关键字了;只需要一句话select people.‘sex’,count() from people group by sex就搞定了,这样就可以直接显示一个友好的结果表;
现在有这么一个需求,我有一个客户表,客户分为三个等级,需要按照客户来分类,并计算每个等级的客户的总消费量,以表格形式呈现出来;有了前面这个例子,这个便很好来实现了,只需要把函数count(*)改成函数sum(xiaofei) 便可以了;
group by x的意思就是把所有具有相同x字段的数据放在一起,比如上面的性别或者上面的客户等级,按照这个分好;
那么group by x,y的意思呢?很明显啊,就是把所有具有x和y两个字段都相同的数据放在一起;
像上面两个例子,如果我想不仅把客户按照等级来分好,而且每个等级的按照男女来分好,并计算每个等级的男女的消费总额;这个需求该如何实现呢?这个问题便用到了上面的多条件分组;
select people.level,people.sex,count(*),sum(xiaofei) from people group by level,sex;
即将具有相同的客户等级和客户性别的放到一组,并进行聚合函数(sum.count.avg.max);
总结:写了一些关键字的用法,关键字的用法很重要,熟练掌握;

/*************************************************************************
/*************************************************************************
此文章版权方是个人,目的是为自己记录学习历程的同时为大家提供一些参考;如果有不正确的地方,欢迎大家提出!
/*************************************************************************
/*************************************************************************