一步步解读pytorch实现BiLSTM CRF代码
pytorch实现BiLSTM+CRF
网上很多教程都是基于pytorch官网例子进行的解读,所以我就决定看懂官网例子后自己再进行复现,这一篇是我对于官方代码的详细解读。
理解LSTM
参考:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
这一篇英文的LSTM文章写得真的很好,看了一遍以后就很轻松的捡起了遗忘的知识点
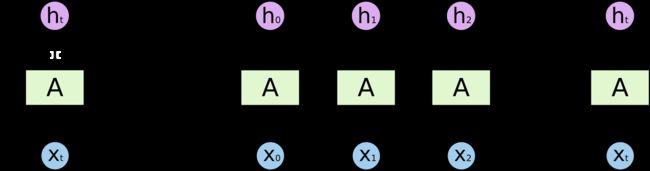
RNN
RNN虽然可以帮我们联系之前的信息,但是相关信息之间的距离很大时RNN就不能那么有效的工作,这时就需要LSTM,LSTM的结构如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WFVGTFNr-1579522756021)(http://colah.github.io/posts/2015-08-Understanding-LSTMs/img/LSTM3-chain.png)]
The repeating module in an LSTM contains four interacting layers.
LSTM的核心
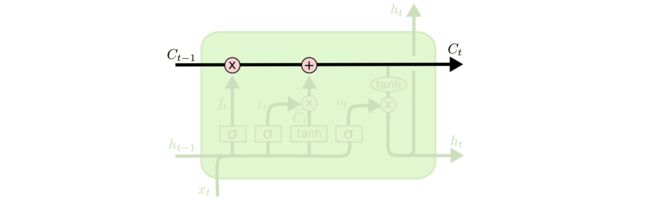
LSTM的关键是单元状态,有点像传送带,它沿整个链条一直沿直线延伸,只有一些较小的线性相互作用,因此信息不加改变地流动非常容易,LSTM中门只是在这个直线的基础上做一些控制。
一步步解读LSTM
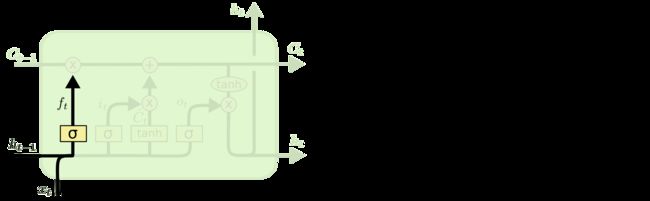
LSTM的第一步是遗忘门,它决定了我们在这一步丢掉什么信息。遗忘门的值为1表示完全保留,值为0表示完全遗忘。
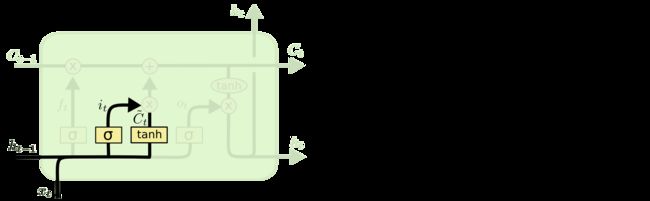
LSTM的第二步是确定要在单元状态下存储哪些新信息,包括两个部分。首先,输入层采用sigmoid计算决定将更新哪些值;接下来,tanh层创建一个新候选值 C ~ t \tilde C_t C~t的向量。
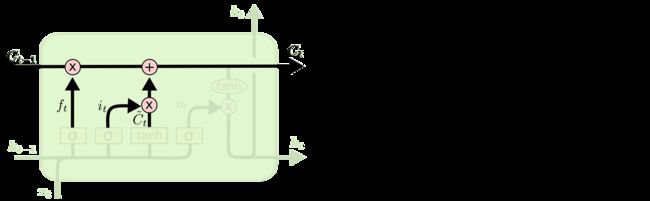
接下来就是更新单元状态,根据图示可以很轻松的列出表达式。
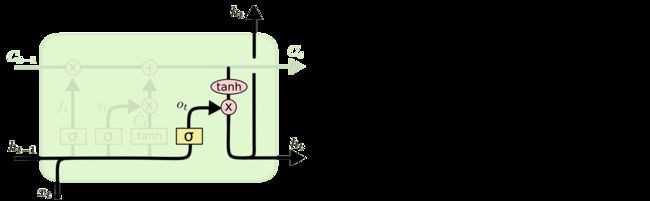
最后就是决定LSTM的输出,首先我们用一个sigmoid函数决定输出单元状态的哪一个部分,然后将单元状态穿过tanh层并与sigmoid值相乘从而使我们只输出我们想要的部分。
理解BiLSTM与CRF
参考:https://www.jianshu.com/p/97cb3b6db573

BiLSTM层的输出为每一个标签的预测分值,然后将BiLSTM的输出值作为CRF层的输入,最后结果就是每个词的标签。
CRF层的作用
虽然BiLSTM就可以完成标注工作,但是没有办法添加约束条件,通过CRF层就可以添加约束从而使预测的标签是合法的。
理解损失函数
假设我们的标签一共有tag_size个,那么BiLSTM的输出维度就是tag_size,表示的是每个词 w i w_i wi映射到tag的发射概率值(feats),设BiLSTM的输出矩阵为 P P P,其中 P i , j P_{i,j} Pi,j代表词 w i w_i wi映射到$ tag_j 的 非 归 一 化 概 率 。 对 于 C R F 来 说 , 我 们 假 定 存 在 一 个 转 移 矩 阵 的非归一化概率。对于CRF来说,我们假定存在一个转移矩阵 的非归一化概率。对于CRF来说,我们假定存在一个转移矩阵A , 则 ,则 ,则A_{i,j} 代 表 代表 代表tag_i 转 移 到 转移到 转移到tag_j$的转移概率。
对于输入序列 X X X对应的输出 t a g tag tag序列 y y y,定义分数为:
s ( X , y ) = ∑ i = 0 n A y i , y i + 1 + ∑ i = 1 n P i , y i s(X,y)=\sum_{i=0}^nA_{y_i,y_{i+1}}+\sum_{i=1}^nP_{i,y_i} s(X,y)=i=0∑nAyi,yi+1+i=1∑nPi,yi
对上式进行softmax处理,我们都知道softmax可以帮助我们把一些输入映射为0-1之间的实数,并且可以归一化保证和为1,因此对于一个词到每个tag的概率之和为1。现在我们利用softmax函数为每一个正确的 t a g tag tag序列 y y y定义一个概率值( Y X Y_X YX代表所有的 t a g tag tag序列,包括不可能出现的)
p ( y ∣ X ) = e s ( X , y ) ∑ y ~ ∈ Y X e s ( X , y ~ ) p(y|X)=\frac{e^{s(X,y)}}{\sum_{\tilde y\in Y_X}e^{s(X,\tilde y)}} p(y∣X)=∑y~∈YXes(X,y~)es(X,y)
使用对数最大似然估计
log ( p ( y ∣ X ) ) = S ( X , y ) − l o g ( ∑ y ~ ∈ Y X e s ( X , y ~ ) ) \log(p(y|X))=S(X,y)-log(\sum_{\tilde y\in Y_X}e^{s(X,\tilde y)}) log(p(y∣X))=S(X,y)−log(y~∈YX∑es(X,y~))
所以Loss可以为:
L o s s = log ( ∑ y ~ ∈ Y X e S ( X , y ~ ) ) − S ( X , y ) Loss=\log(\sum_{\tilde y\in Y_X}e^{S(X,\tilde y)})-S(X,y) Loss=log(y~∈YX∑eS(X,y~))−S(X,y)
其中 log ( ∑ y ~ ∈ Y X e S ( X , y ~ ) ) \log(\sum_{\tilde y\in Y_X}e^{S(X,\tilde y)}) log(∑y~∈YXeS(X,y~))的计算较为复杂,因为需要计算每一条可能路径的分数,可以采用一种简便的方法,对于到词 w i + 1 w_{i+1} wi+1的路径,可以先把到 w i w_i wi的值算出来,因为:
log ( ∑ e log ( ∑ e x ) + y ) = log ( ∑ ∑ e x + y ) \log(\sum e^{\log(\sum e^x)+y})=\log(\sum\sum e^{x+y}) log(∑elog(∑ex)+y)=log(∑∑ex+y)
解读代码
首先先来看一下代码的整体思路是什么,先不看模型的实现,先从模型的训练开始。
训练模型
这里采用的是BIO标注,但是多添加了两个标签
BIO标注:B表示实体名称的开始,I表示实体名称的中间字,O表示非实体字
'''在训练过程中需要用到的函数'''
def prepare_sequence(seq, to_ix):
#seq是分词后语料,to_ix是语料库每个词对应的编号
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
START_TAG = ""
STOP_TAG = ""
EMBEDDING_DIM = 5 # 由于标签一共有B\I\O\START\STOP 5个,所以embedding_dim为5
HIDDEN_DIM = 4 # 这其实是BiLSTM的隐藏层的特征数量,因为是双向所以是2倍,单向为2
# 训练数据
training_data = [(
"the wall street journal reported today that apple corporation made money".split(), #['the','wall','street','journal',...]
"B I I I O O O B I O O".split() #['B','I','I',...]
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
# 给每一个不重复的词进行编码,比如‘HELLO WORLD’就是{'HELLO':0,'WORLD:1'}
word_to_ix = {} # 训练语料的字典,语料中的每一个字对应的编码(index)
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
tag_to_ix = {"B": 0, "I": 1, "O": 2, START_TAG: 3, STOP_TAG: 4}# tag的字典,每个tag对应一个编码
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM) #模型
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4) #优化器,采用随机梯度下降
# Check predictions before training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long)
print(model(precheck_sent)) #(tensor(2.6907), [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1])
# Make sure prepare_sequence from earlier in the LSTM section is loaded
for epoch in range(300): #循环次数可以自己设定
for sentence, tags in training_data:
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Step 2. Get our inputs ready for the network, that is,
# turn them into Tensors of word indices.
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. Run our forward pass.
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss.backward()
optimizer.step()
# Check predictions after training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
# We got it!
创建模型
一步步解读模型中的函数,首先是初始化
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
'''
初始化模型
parameters:
vocab_size:语料的字典的长度
tag_to_ix:标签与对应编号的字典
embedding_dim:标签的数量
hidden_dim:BiLSTM的隐藏层的神经元数量
'''
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
#输出为一个mini-batch*words num*embedding_dim的矩阵
#vocab_size表示一共有多少词,embedding_dim表示想为每个词创建一个多少维的向量来表示
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
#创建LSTM(每个词的特征数量,隐藏层的特征数量,循环层的数量指堆叠的层数,是否是BLSTM)
self.lstm = nn.LSTM(embedding_dim,hidden_dim//2,num_layers=1,bidirectional=True)
# 将LSTM的输出映射到标签空间
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 转移矩阵,transitions[i][j]表示从label j转移到label i的概率,虽然是随机生成的但是后面会迭代更新
# 这里特别要注意的是transitions[i]表示的是其他标签转到标签i的概率
self.transitions = nn.Parameter(torch.randn(self.tagset_size,self.tagset_size))
# 这两个语句强制执行了这样的约束条件:我们永远不会转移到开始标签,也永远不会从停止标签转移
self.transitions.data[tag_to_ix[START_TAG], :] = -10000#从任何标签转移到START_TAG不可能
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000#从STOP_TAG转移到任何标签不可能
self.hidden = self.init_hidden()
def init_hidden(self):
#(num_layers*num_directions,minibatch_size,hidden_dim)
# 实际上初始化的h0和c0
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
解释一下里面几个重要的函数,对于理解程序会有较大的帮助。
nn.Embedding()
参考:https://blog.csdn.net/david0611/article/details/81090371
这个函数的作用就是创建一个词嵌入模型,形式上是nn.Embedding(vocab_size,embedding_dim),vocab_size表示提供的语料库一共有多少词,embedding_dim表示想用一个每个词创建一个多少维的向量来表示(一般是标签数量)。生成的模型可以读取多个向量,输入为两个维度(batch的大小,每个batch的单词个数),输出则是在两个维度加上词向量的大小。
embedding = nn.Embedding(10, 3)
# 每批取两组,每组四个单词,每个词用3维向量表示
input = Variable(torch.LongTensor([[1,2,4,5],[4,3,2,9]]))
a = embedding(input) # 输出2*4*3
nn.LSTM()
参考:https://blog.csdn.net/rogerfang/article/details/84500754
LSTM()一共有7个参数,这里只介绍用到的参数,input_size是指输入特征的维度(在这里指每个词编码后的维度也就是tag数量),hidden_size是指隐藏状态的维度,num_layers指的是LSTM堆叠的层数就是说是否要多个LSTM重复,bidirectional设置为True则表示创建的是一个双向LSTM。
模型创建好之后输入和输出如下图所示:
| nn.LSTM( | (Input_size | Hidden_size | Num_layers) |
|---|---|---|---|
| x | Seq_len | batch | Input_size |
| h0 | Num_layers*num_directions | batch | Hidden_size |
| c0 | Num_layers*num_directions | batch | Hidden_size |
| output | Seq_len | batch | Num_directions*hidden_size |
| hn | Num_layers*num_directions | batch | Hidden_size |
| cn | Num_layers*num_directions | batch | Hidden_size |
模型创建好之后来看一下运行模型的过程中做的事情
def forward(self, sentence): #sentence是已经编码的句子
# Get the emission scores from the BiLSTM
lstm_feats = self._get_lstm_features(sentence)
# Find the best path, given the features.
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
解读一下就是把语料先交给BiLSTM处理,然后得到的结果进行维特比解码(就是对标签进行预测),这里就需要先讲解一下维特比解码。
维特比算法
参考:https://www.zhihu.com/question/294202922/answer/489485567
参考链接里面已经很详细的讲解了维特比算法的思想,放在这里就可以解读为:通过维特比算法要求出一个序列的可能性的值最大,然后输出我们的序列和可能性的值。
def argmax(vec):
# 得到最大的值的索引
_, idx = torch.max(vec, 1) # 返回每行中最大的元素和最大元素的索引
return idx.item()
def _viterbi_decode(self, feats):
#预测序列的得分,维特比解码,输出得分与路径值
backpointers = []
# Initialize the viterbi variables
init_vvars = torch.full((1, self.tagset_size), -10000.)#这就保证了一定是从START到其他标签
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var at step i holds the viterbi variables for step i-1
forward_var = init_vvars
for feat in feats:
bptrs_t = [] # holds the backpointers for this step
viterbivars_t = [] # holds the viterbi variables for this step
for next_tag in range(self.tagset_size):
# 其他标签(B,I,E,Start,End)到标签next_tag的概率
next_tag_var = forward_var + self.transitions[next_tag]#forward_var保存的是之前的最优路径的值
best_tag_id = argmax(next_tag_var) #返回最大值对应的那个tag
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# Now add in the emission scores, and assign forward_var to the set
# of viterbi variables we just computed
# 从step0到step(i-1)时5个序列中每个序列的最大score
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)# bptrs_t有5个元素
# 其他标签到STOP_TAG的转移概率
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # Sanity check
best_path.reverse()# 把从后向前的路径正过来
return path_score, best_path
然后就是计算损失函数的部分
# 计算log部分的值
def log_sum_exp(vec): #vec维度为1*5
max_score = vec[0, argmax(vec)]#max_score的维度为1
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) #维度为1*5
return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
#等同于torch.log(torch.sum(torch.exp(vec))),防止e的指数导致计算机上溢
def neg_log_likelihood(self, sentence, tags):# loss function
feats = self._get_lstm_features(sentence) # 经过LSTM+Linear后的输出作为CRF的输入
forward_score = self._forward_alg(feats) # loss的log部分的结果
gold_score = self._score_sentence(feats, tags)# loss的后半部分S(X,y)的结果
return forward_score - gold_score #Loss
def _get_lstm_features(self, sentence):#仅仅是BiLSTM的输出没有CRF层
self.hidden = self.init_hidden() # 一开始的隐藏状态
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden) #最后输出结果和最后的隐藏状态
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
下面的函数计算的是 log ( ∑ y ~ ∈ Y X e S ( X , y ~ ) ) \log(\sum_{\tilde y\in Y_X}e^{S(X,\tilde y)}) log(∑y~∈YXeS(X,y~))
def _forward_alg(self, feats):#预测序列的得分,就是Loss的右边第一项
#feats表示发射矩阵(emit score),实际上就是LSTM的输出,意思是经过LSTM的sentence的每个word对应于每个label的得分
# Do the forward algorithm to compute the partition function
init_alphas = torch.full((1, self.tagset_size), -10000.) #用-10000.来填充一个形状为[1,tagset_size]的tensor
# START_TAG has all of the score.
# 因为start tag是4,所以tensor([[-10000., -10000., -10000., 0., -10000.]]),
# 将start的值为零,表示开始进行网络的传播,
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# 包装到一个变量里面以便自动反向传播
forward_var = init_alphas # 初始状态的forward_var,随着step t变化
# 遍历句子,迭代feats的行数次
for feat in feats:
alphas_t = [] # 当前时间步的正向tensor
for next_tag in range(self.tagset_size):
# broadcast the emission score: it is the same regardless of the previous tag
#LSTM的生成矩阵是emit_score,维度为1*5
emit_score = feat[next_tag].view(1, -1).expand(1, self.tagset_size)
# the i_th entry of trans_score is the score of transitioning to
# next_tag from i
trans_score = self.transitions[next_tag].view(1, -1)#维度是1*5
# 第一次迭代时理解:
# trans_score是所有其他标签到B标签的概率
# 由lstm运行进入隐层再到输出层得到标签B的概率,emit_score维度是1*5,5个值是相同的
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is logsumexp of all the scores.
alphas_t.append(log_sum_exp(next_tag_var).view(1))
# 此时的alphas t 是一个长度为5,例如:
# [tensor(0.8259), tensor(2.1739), tensor(1.3526), tensor(-9999.7168), tensor(-0.7102)]
forward_var = torch.cat(alphas_t).view(1, -1)
# 最后只将最后一个单词的forward var与转移 stop tag的概率相加
# tensor([[ 21.1036, 18.8673, 20.7906, -9982.2734, -9980.3135]])
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)# alpha是一个0维的tensor
return alpha
对于_forward_alg()这个函数的解释比较好的可以参考:https://blog.csdn.net/cuihuijun1hao/article/details/79405740
下面的函数计算的是: s ( X , y ) = ∑ i = 0 n A y i , y i + 1 + ∑ i = 1 n P i , y i s(X,y)=\sum_{i=0}^nA_{y_i,y_{i+1}}+\sum_{i=1}^nP_{i,y_i} s(X,y)=∑i=0nAyi,yi+1+∑i=1nPi,yi
def _score_sentence(self, feats, tags):# 求Loss function的第二项
# 这与上面的def _forward_alg(self, feats)共同之处在于:两者都是用的随机转移矩阵算的score,不同地方在于,上面那个函数算了一个最大可能路径,但实际上可能不是真实的各个标签转移的值 例如:真实标签是N V V,但是因为transitions是随机的,所以上面的函数得到其实是N N N这样,两者之间的score就有了差距。而后来的反向传播,就能够更新transitions,使得转移矩阵逼近真实的“转移矩阵”得到gold_seq tag的score 即根据真实的label 来计算一个score,但是因为转移矩阵是随机生成的,故算出来的score不是最理想的值
score = torch.zeros(1)
# 将START_TAG的标签3拼接到tag序列最前面
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
for i, feat in enumerate(feats):
# self.transitions[tags[i + 1], tags[i]] 实际得到的是从标签i到标签i+1的转移概率
# feat[tags[i+1]], feat是step i 的输出结果,有5个值,
# 对应B, I, E, START_TAG, END_TAG, 取对应标签的值
# transition【j,i】 就是从i ->j 的转移概率值
score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score