Python/打响2019年第四炮-Python爬虫入门(四)
打响2019年第四炮-Python爬虫入门(四)
在第三炮中对多页商品进行了爬取,结果如下:


本章主要内容,对前几炮的代码及爬虫进行优化,改写成类如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 完善爬虫安全措施(headers,proxies,retries,delay, timeout)
import json
import re
import time
import csv
from urllib.parse import urlparse
from datetime import datetime, timedelta
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
class Throttle:
"""阀门类,对相同域名的访问添加延迟时间,避免访问过快
"""
def __init__(self, delay):
# 延迟时间,避免访问过快
self.delay = delay
# 用字典保存访问某域名的时间
self.domains = {}
def wait(self, url):
"""对访问过的域名添加延迟时间
"""
domain = urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
class Phone:
def __init__(self, headers=None, num_retries=3, proxies=None, delay=5, timeout=30):
self.headers = headers
self.num_retries = num_retries
self.throttle = Throttle(delay)
self.timeout = timeout
self.proxies = proxies
def download(self, url, is_json=False):
print('下载页面:', url)
self.throttle.wait(url)
try:
response = requests.get(url, headers=self.headers, proxies=self.proxies, timeout=self.timeout)
print(response.status_code)
if response.status_code == 200:
if is_json:
return response.json()
else:
return response.content
return None
except RequestException as e:
print('error:', e.response)
html = ''
if hasattr(e.response, 'status_code'):
code = e.response.status_code
print('error code:', code)
if self.num_retries > 0 and 500 <= code < 600:
# 遇到5XX 的错误就重试
html = self.download(url)
self.num_retries -= 1
else:
code = None
return html
def write_csv(self, all_list):
""""""
with open("yk.csv", 'w', newline='') as f:
writer = csv.writer(f)
fields = ('phone_ID', '名称', '价格', '累计评价', '好评率')
writer.writerow(fields)
for row in all_list:
writer.writerow(row)
def find_all(self, url):
""""""
r = self.download(url)
soup_all = BeautifulSoup(r, 'lxml')
sp_all_items = soup_all.find_all('li', attrs={'class': 'gl-item'})
print(f"共找到{len(sp_all_items)}件商品....".center(50, "-"))
data_list = []
for soup in sp_all_items:
# 取手机名称
phone_name = soup.find('div', attrs={'class': 'p-name p-name-type-2'}).find('em').text
print(phone_name)
# 取手机价格
phone_price = soup.find('div', attrs={'class': 'p-price'}).find('i').text
print(phone_price)
# 取手机ID
item_id = soup['data-sku']
print('item-id', item_id)
ID_URL = f"https://club.jd.com/comment/productCommentSummaries.action?referenceIds={item_id}"
comment_count, good_rate = self.get_json(ID_URL)
print('评价人数:', comment_count)
print('好评率:', good_rate)
row = []
row.append(item_id)
row.append(phone_name)
row.append(str(phone_price) + "¥")
row.append(comment_count)
row.append(str(good_rate) + "%")
data_list.append(row)
return data_list
def get_json(self, id_url):
data = self.download(id_url, is_json=True)
result = data['CommentsCount']
for i in result:
return i["CommentCountStr"], i["GoodRateShow"]
def fetch_data(self, jd_url, page_start, page_end, page_offset):
all_list = []
for page in range(page_start, page_end, page_offset):
data_list = self.find_all(jd_url.format(page))
all_list += data_list
self.write_csv(all_list)
def main():
""""""
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://www.jd.com"
}
jd_html = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&suggest=1.def.0.V06&wq=sho&cid2=653&cid3=655&page={}&s=113&click=0'"
# start = time.time()
spider = Phone(headers=headers)
spider.fetch_data(jd_html, 1, 5, 2)
# stop = time.time()
# print(f'抓取结束,一共用时时间为:{(start - stop)}秒......')
if __name__ == "__main__":
main()
本章将会对以上代码进行解释如下:
一、main函数
def main():
""""""
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://www.jd.com"
}
jd_html = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&suggest=1.def.0.V06&wq=sho&cid2=653&cid3=655&page={}&s=113&click=0'"
# start = time.time()
spider = Phone(headers=headers)
spider.fetch_data(jd_html, 1, 5, 2)
# stop = time.time()
# print(f'抓取结束,一共用时时间为:{(start - stop)}秒......')
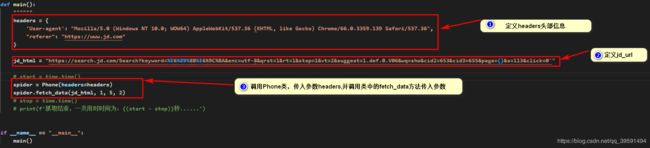
在main()函数中定义了headers头部信息,在请求的过程中模仿是通过"浏览器“访问的网站,提高安全措施定义如下:
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://www.jd.com"
}
在main()函数中定义了网站url地址,在网站地址中定义page={},提供后期format传入数据
![]()
同时调用了phone类传入值为:headers并生成对象spider,使用spider对象调用phone类中的方法fetch_data如下:
spider = Phone(headers=headers)
spider.fetch_data(jd_html, 1, 5, 2)
二、Phone类
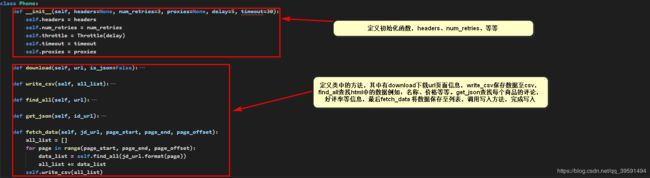
在运行main()函数时,第一步调用Phone类中的fetch_data方法 传入的值为jd_url, page_start, page_end, page_offset:

2.1、Phone类中的fetch_data方法
def fetch_data(self, jd_url, page_start, page_end, page_offset):
all_list = []
for page in range(page_start, page_end, page_offset):
data_list = self.find_all(jd_url.format(page))
all_list += data_list
self.write_csv(all_list)
在fetch_data中的参数为:jd_url=https://www.jd.com/xxxxx page_start=1,page_end=5 ,page_offset=2
def fetch_data(self, jd_url, page_start, page_end, page_offset):
all_list = []
for page in range(1, 5, 2):
data_list = self.find_all(jd_url.format(page))
all_list += data_list
self.write_csv(all_list)

2.2、Phone类中的find_all方法
def find_all(self, url):
""""""
r = self.download(url)
soup_all = BeautifulSoup(r, 'lxml')
sp_all_items = soup_all.find_all('li', attrs={'class': 'gl-item'})
print(f"共找到{len(sp_all_items)}件商品....".center(50, "-"))
data_list = []
for soup in sp_all_items:
# 取手机名称
phone_name = soup.find('div', attrs={'class': 'p-name p-name-type-2'}).find('em').text
print(phone_name)
# 取手机价格
phone_price = soup.find('div', attrs={'class': 'p-price'}).find('i').text
print(phone_price)
# 取手机ID
item_id = soup['data-sku']
print('item-id', item_id)
ID_URL = f"https://club.jd.com/comment/productCommentSummaries.action?referenceIds={item_id}"
comment_count, good_rate = self.get_json(ID_URL)
print('评价人数:', comment_count)
print('好评率:', good_rate)
row = []
row.append(item_id)
row.append(phone_name)
row.append(str(phone_price) + "¥")
row.append(comment_count)
row.append(str(good_rate) + "%")
data_list.append(row)
return data_list
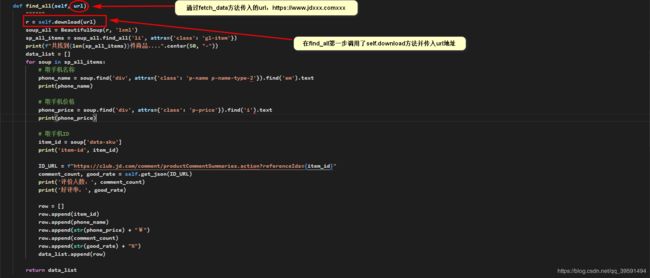
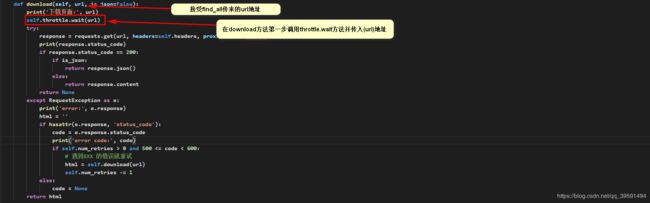
调用find_all方法传入url地址,同时调用了self.download方法,那么download方法如下:
def download(self, url, is_json=False):
print('下载页面:', url)
self.throttle.wait(url)
try:
response = requests.get(url, headers=self.headers, proxies=self.proxies, timeout=self.timeout)
print(response.status_code)
if response.status_code == 200:
if is_json:
return response.json()
else:
return response.content
return None
except RequestException as e:
print('error:', e.response)
html = ''
if hasattr(e.response, 'status_code'):
code = e.response.status_code
print('error code:', code)
if self.num_retries > 0 and 500 <= code < 600:
# 遇到5XX 的错误就重试
html = self.download(url)
self.num_retries -= 1
else:
code = None
return html
Throttle类如下:
class Throttle:
"""阀门类,对相同域名的访问添加延迟时间,避免访问过快
"""
def __init__(self, delay):
# 延迟时间,避免访问过快
self.delay = delay
# 用字典保存访问某域名的时间
self.domains = {}
def wait(self, url):
"""对访问过的域名添加延迟时间
"""
domain = urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
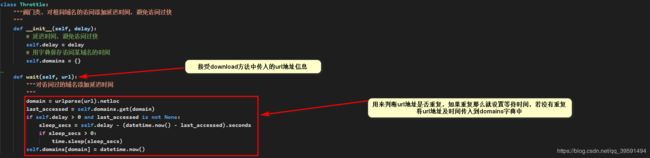
当wait方法运行结束后,只有两种结果,1:将url以及时间保存至字典中,2:等待几秒
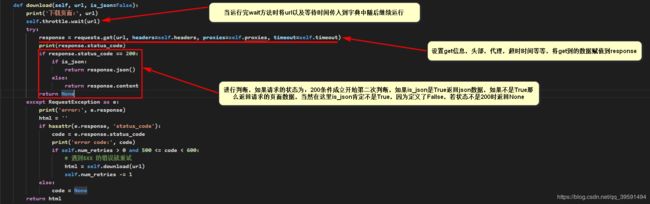
以上执行一共有两个结果,1:返回空值 2:返回页面数据,继续运行find_all方法如下:

在以上流程中调用get_json方法,get_json如下:
def get_json(self, id_url):
data = self.download(id_url, is_json=True)
result = data['CommentsCount']
for i in result:
return i["CommentCountStr"], i["GoodRateShow"]

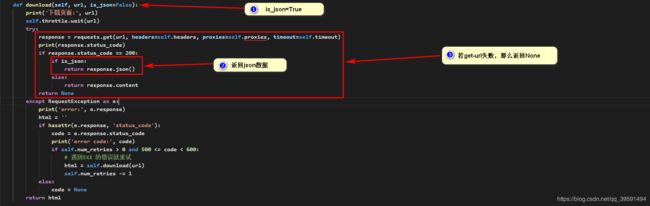

以上运行成功后返回好评率及评价等信息,继续运行find_all 方法如下:
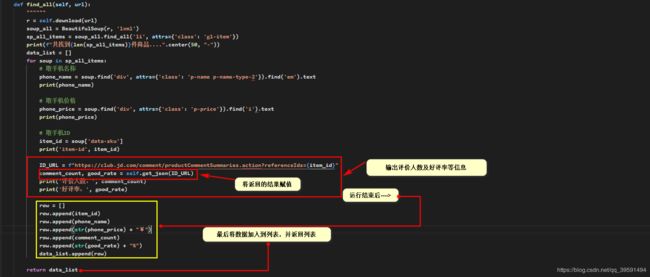
以上find_all方法运行结束后,返回一个列表,在列表中的数据为商品的名称等信息最后传入至fetch_data如下:

最后的write_csv方法如下:
def write_csv(self, all_list):
""""""
with open("yk.csv", 'w', newline='') as f:
writer = csv.writer(f)
fields = ('phone_ID', '名称', '价格', '累计评价', '好评率')
writer.writerow(fields)
for row in all_list:
writer.writerow(row)
写入完成后结束!!!
最终代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 完善爬虫安全措施(headers,proxies,retries,delay, timeout)
import json
import re
import time
import csv
from urllib.parse import urlparse
from datetime import datetime, timedelta
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
class Throttle:
"""阀门类,对相同域名的访问添加延迟时间,避免访问过快
"""
def __init__(self, delay):
# 延迟时间,避免访问过快
self.delay = delay
# 用字典保存访问某域名的时间
self.domains = {}
def wait(self, url):
"""对访问过的域名添加延迟时间
"""
domain = urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
class Phone:
def __init__(self, headers=None, num_retries=3, proxies=None, delay=5, timeout=30):
self.headers = headers
self.num_retries = num_retries
self.throttle = Throttle(delay)
self.timeout = timeout
self.proxies = proxies
def download(self, url, is_json=False):
print('下载页面:', url)
self.throttle.wait(url)
try:
response = requests.get(url, headers=self.headers, proxies=self.proxies, timeout=self.timeout)
print(response.status_code)
if response.status_code == 200:
if is_json:
return response.json()
else:
return response.content
return None
except RequestException as e:
print('error:', e.response)
html = ''
if hasattr(e.response, 'status_code'):
code = e.response.status_code
print('error code:', code)
if self.num_retries > 0 and 500 <= code < 600:
# 遇到5XX 的错误就重试
html = self.download(url)
self.num_retries -= 1
else:
code = None
return html
def write_csv(self, all_list):
""""""
with open("yk.csv", 'w', newline='') as f:
writer = csv.writer(f)
fields = ('phone_ID', '名称', '价格', '累计评价', '好评率')
writer.writerow(fields)
for row in all_list:
writer.writerow(row)
def find_all(self, url):
r = self.download(url)
soup_all = BeautifulSoup(r, 'lxml')
sp_all_items = soup_all.find_all('li', attrs={'class': 'gl-item'})
print(f"共找到{len(sp_all_items)}件商品....".center(50, "-"))
data_list = []
for soup in sp_all_items:
# 取手机名称
phone_name = soup.find('div', attrs={'class': 'p-name p-name-type-2'}).find('em').text
print(phone_name)
# 取手机价格
phone_price = soup.find('div', attrs={'class': 'p-price'}).find('i').text
print(phone_price)
# 取手机ID
item_id = soup['data-sku']
print('item-id', item_id)
ID_URL = f"https://club.jd.com/comment/productCommentSummaries.action?referenceIds={item_id}"
comment_count, good_rate = self.get_json(ID_URL)
print('评价人数:', comment_count)
print('好评率:', good_rate)
row = []
row.append(item_id)
row.append(phone_name)
row.append(str(phone_price) + "¥")
row.append(comment_count)
row.append(str(good_rate) + "%")
data_list.append(row)
return data_list
def get_json(self, id_url):
data = self.download(id_url, is_json=True)
result = data['CommentsCount']
for i in result:
return i["CommentCountStr"], i["GoodRateShow"]
def fetch_data(self, jd_url, page_start, page_end, page_offset):
all_list = []
for page in range(page_start, page_end, page_offset):
data_list = self.find_all(jd_url.format(page))
all_list += data_list
self.write_csv(all_list)
def main():
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://www.jd.com"
}
jd_html = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&suggest=1.def.0.V06&wq=sho&cid2=653&cid3=655&page={}&s=113&click=0'"
# start = time.time()
spider = Phone(headers=headers)
spider.fetch_data(jd_html, 1, 5, 2)
# stop = time.time()
# print(f'抓取结束,一共用时时间为:{(start - stop)}秒......')
if __name__ == "__main__":
main()
运行过程如下:
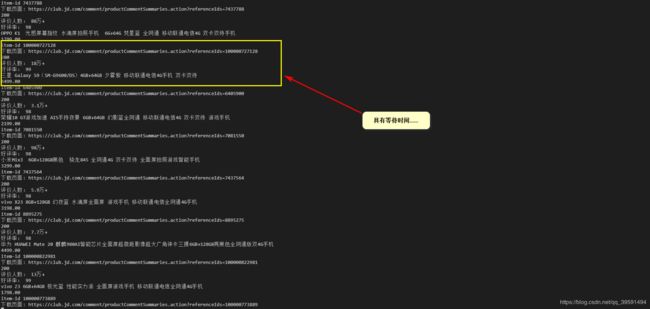
运行结果如下:
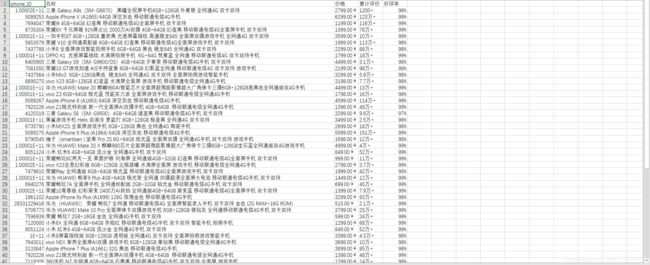
以上内容为个人笔记,希望能够对您有所帮助,再见~