机器学习的模型评估(使用sklearn工具)
文章目录
- 一、sklearn.metrics中的分类模型评估方法介绍
- (1)confusion_matrix混淆矩阵
- (2)recall_score召回率
- (3)accuracy_score准确率
- (4)精确率
- (5)F1分数
- (6)classification_report函数
- (7)P-R曲线
- 二、sklearn.metrics中的回归模型评估方法介绍
- (1)平均绝对百分比误差MAPE与均方根误差RMSE
- 小结
- 三、ROC/AUC的相关概念
- (1)两个指标
- (2)ROC曲线(接受者操作特征曲线)
- (3)绘制roc曲线代码
- (4)ROC优点
- (5)使用AUC面积值来判断ROC曲线好坏
- (6)AUC两种计算方法
- (7)P-R曲线和ROC曲线区别
- 四、accuracy_score与score方法对比
- 五、使用train_error 与test_error曲线
- 六、代码示例
- 七,验证曲线与学习曲线
- 八,过拟合和欠拟合
- (1)降低“过拟合”风险的方法
- (2)降低“欠拟合”风险的方法
sklearn模型评估主要包括三种方法
- 使用scoring进行模型的性能评估
- 使用各个模型的提供的score方法来进行评估
- 使用metrics进行模型评估
一、sklearn.metrics中的分类模型评估方法介绍
(1)confusion_matrix混淆矩阵
#sklearn代码实例
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)

所以11为TP,10为FP,01为FN,00为TN。
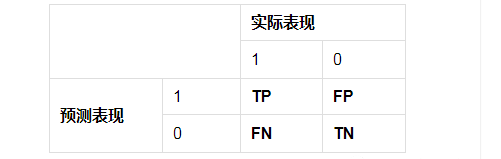
第一个字符代表预测表现,第二个字符对于实际表现来说是预测对或错。
TP:预测为1,预测正确,即实际1
FP:预测为1,预测错误,即实际0
FN:预测为0,预测错确,即实际1
TN:预测为0,预测正确即,实际0
(2)recall_score召回率
(召回率针对原样本,含义是预测正确的样本数占实际为正样本的百分比),分母为实际为正的样本数。
利用混淆矩阵表示就是recall_score=TP/(TP+FN)
#sklearn代码实例
recall_score=recall_score(y_true, y_pred,labels=None,pos_label=1,average='binary', sample_weight=None)
多分类时候指定参数average : string, [None, ‘micro’, ‘macro’(default), ‘samples’, ‘weighted’]
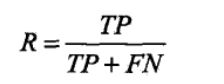
(3)accuracy_score准确率
(准确率是指预测正确的样本数占总样本百分比)
利用混淆矩阵表示就是accuracy_score=(TP+TN)/(TP+TN+FP+FN)
#sklearn代码实例
accuracy_score=accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
准确率是分类问题中最简单也是最直观的评价指标, 但存在明显的缺陷。 比
如, 当负样本占99%时, 分类器把所有样本都预测为负样本也可以获得99%的准确
率。 所以, 当不同类别的样本比例非常不均衡时, 占比大的类别往往成为影响准
确率的最主要因素。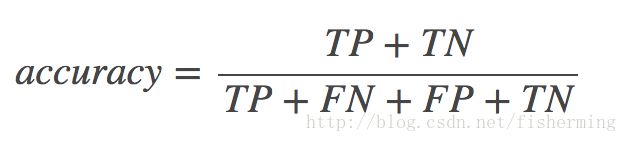
(4)精确率
它是针对预测结果而言的,它的含义是预测正确的样本数占预测为正样本的百分比,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,即预测的有多少个为正样本。分母为预测为正的样本数
精确率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本,和样本比例有很大关系。
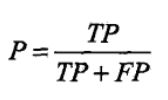
#sklearn代码实例
precision_score=precision_score(y_true, y_pred[, labels, …])
(5)F1分数
F1-score是精准率和召回率二者的评估,F1分数同时考虑了精准率和召回率,让二者同时达到最高,取一个平衡。F1分数的公式为 = 2精准率召回率 / (精准率 +召回率)。
#sklearn代码实例
f1_score=f1_score(y_true, y_pred)
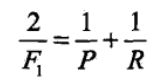
(6)classification_report函数
classification_report函数会输出包含召回率,精确率,F1值的表
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
(7)P-R曲线
P-R曲线综合考虑了精确率和召回率,P-R曲线的横轴是召回率, 纵轴是精确率。 对于一个排序模型来说, 其P-R曲线上的一个点代表着, 在某一阈值下, 模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本, 此时返回结果对应的召回率和精确率。整条P-R曲线是通过将阈值从高到低移动而生成的。
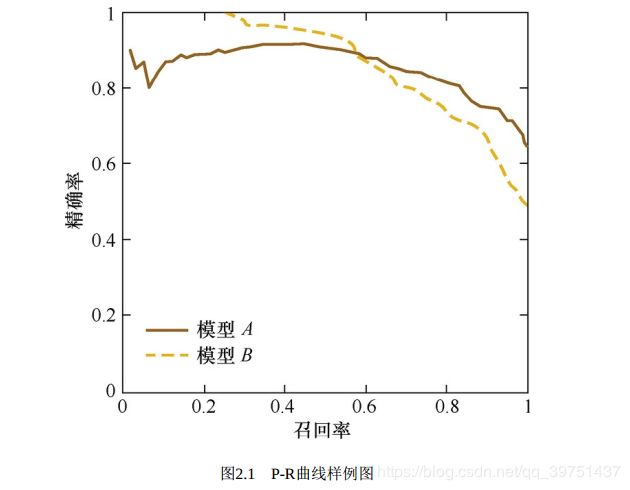
曲线分析:
当召回率接近于0时, 模型A的精确率为0.9, 模型B的精确率是1,这说明模型B得分前几位的样本全部是真正的正样本, 而模型A即使得分最高的几个样本也存在预测错误的情况。 并且, 随着召回率的增加, 精确率整体呈下降趋势。 但是, 当召回率为1时, 模型A的精确率反而超过了模型B。
二、sklearn.metrics中的回归模型评估方法介绍
(1)平均绝对百分比误差MAPE与均方根误差RMSE
RMSE经常被用来衡量回归模型的好坏,一般情况下, RMSE能够很好地反映回归模型预测值与真实值的偏离程度。 但在实际问题中, 如果存在个别偏离程度非常大的离群点 时, 即使离群点数量非常少, 也会让RMSE指标变得很差。
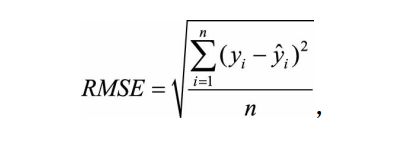
存在离群点解决办法:
- 第一, 如果我们认定这些离群点是“噪声点”的话, 就需要在数据预处理的阶段把这些噪声点过滤掉。
- 第二, 如果不认为这些离群点是“噪声点”的话, 就需要进一步提高模型的
预测能力, 将离群点产生的机制建模进去。 - 第三, 可以找一个更合适的指标来评估该模型。
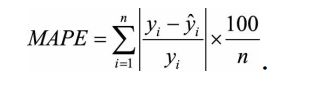
相比RMSE, MAPE相当于把每个点的误差进行了归一化, 降低了个别离群点带来
的绝对误差的影响。
小结
-
Precision值和Recall值是既矛盾又统一的两个指标, 为了提高Precision值, 分
类器需要尽量在“更有把握”时才把样本预测为正样本, 但此时往往会因为过于保 守而漏掉很多“没有把握”的正样本, 导致Recall值降低。 -
Precision值代表对正样本结果中的预测准确程度,而accuracy_score则代表整体的预测准确程度,既包括正样本,也包括负样本,和样本比例有很大关系。
-
Precision值和Recall值是既矛盾又统一的两个指标, 为了提高Precision值, 分 类器需要尽量在“更有把握”时才把样本预测为正样本, 但此时往往会因为过于保 守而漏掉很多“没有把握”的正样本,导致Recall值降低。
-
每个评估指标都有其价值, 但如果只从单一的评估指标出发去评估模型, 往往会得出片面甚至错误的结论; 只有通过一组互补的指标去评估模型,
才能更好地发现并解决模型存在的问题, 从而更好地解决实际业务场景中遇到的问题。
三、ROC/AUC的相关概念
(1)两个指标
TPR和FPR都主要关注正样本
真正率FPR为有多少负样本被错误预测为正样本
假正率TPR为有多少正样本被正确预测为正样本
所以无论样本是否平衡,都不会被影响。

(2)ROC曲线(接受者操作特征曲线)
- ROC曲线中的主要两个指标就是真正率和假正率,其中横坐标为真正率(FPR),纵坐标为假正率(TPR)
- ROC曲线也是通过遍历所有阈值来绘制整条曲线的,改变阈值只是不断地改变预测的正负样本数,曲线是不会变的。
- FPR表示模型虚报的响应程度,而TPR表示模型预测响应的覆盖程度。
- 使用ROC曲线评估分类模型是非常通用的手段,但是,使用它的时候要注意两点:
(1)分类的类型,必须为数值型。
(2) 且只针对二分类问题。
二分类的时候,可以利用roc_curve计算fpr,tpr,和阈值thresholds;,并画出roc曲线,利用roc_auc_score计算auc的值
(3)绘制roc曲线代码
fpr,tpr,thresholds=roc_curve(y_test,y_pred, pos_label=None, sample_weight=None, drop_intermediate=True)
print (tpr,fpr,thresholds)
roc_auc = auc(fpr, tpr)#计录auc的值,在(0,1)之间
plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))
plt.xlabel("FPR (False Positive Rate)")
plt.ylabel("TPR (True Positive Rate)")
plt.title("Receiver Operating Characteristic, ROC(AUC = %0.2f)"% (roc_auc))
plt.show()
(4)ROC优点
(1)ROC曲线能很容易的查出任意阈值对学习器的泛化性能影响。
(2)有助于选择最佳的阈值。ROC曲线越靠近左上角,模型的查全率就越高。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。
(3)可以对不同的学习器比较性能。将各个学习器的ROC曲线绘制到同一坐标中,直观地鉴别优劣,靠近左上角的ROC曲所代表的学习器准确性最高
(5)使用AUC面积值来判断ROC曲线好坏
AUC面积的一般判断标准,面积在0到1之间,AUC越高,模型区分能力越好
0.5 - 0.7:效果较低,但用于预测股票已经很不错了
0.7 - 0.85:效果一般
0.85 - 0.95:效果很好
0.95 - 1:效果非常好,但一般不太可能
(6)AUC两种计算方法
(1)roc_auc_score
根据预测值和真实值确定AUC的值
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
AUC=roc_auc_score(y_true, y_pred)
print (AUC)
(2)roc_curve(二分类有效)
根据曲线上的值确定AUC的值
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
print (fpr,tpr,thresholds)
print (auc(fpr, tpr))
roc_curve返回这三个变量:fpr,tpr,和阈值thresholds;
(7)P-R曲线和ROC曲线区别
- ROC曲线有一个特点, 当正负样本的分布发生变化时, ROC曲线的形状能够基本保持不变, 而P-R曲线的形状一般会发生较剧烈的变化。
- ROC曲线也是通过遍历所有阈值来绘制整条曲线的,改变阈值只是不断地改变预测的正负样本数,曲线是不会变的,这让ROC曲线能够尽量降低不同测试集带来的干扰, 更加客观地衡量模型本身的性能,实际场景中样本一般不均衡,所以ROC曲线更加稳定。
四、accuracy_score与score方法对比
from sklearn.metrics import accuracy_score
score方法是模型在训练集上训练,可以得到测试集上测试得分和训练集上训练得分,适用于train_test_split划分数据集后看模型得分,适用于交叉验证,或者用cross_val_score
clf.fit(x_data_train,y_data_train)
test_acc = clf.score(x_data_test,y_data_test)
train_acc = clf.score(x_data_train,y_data_train)
print(train_acc)#训练得分
print(test_acc)#测试得分
accuracy_score方法是将模型预测的标签与真实标签进行对比,预测得分
clf.fit(x_data_train,y_data_train)
y_pred=clf.predict(x_data_test)
print (accuracy_score(y_data_test, y_pred))
五、使用train_error 与test_error曲线
绘制train_error 与test_error曲线
from sklearn import tree
import numpy as np
from sklearn import datasets,model_selection
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
iris=datasets.load_iris()
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.3,random_state=0)
maxdepth = 40
depths=np.arange(1,maxdepth)
training_scores=[]
testing_scores=[]
for depth in depths:
clf = tree.DecisionTreeClassifier(max_depth=depth)
clf.fit(X_train, y_train)
training_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(depths,training_scores,label="traing score",marker='o')
ax.plot(depths,testing_scores,label="testing score",marker='*')
ax.set_xlabel("maxdepth")
ax.set_ylabel("score")
ax.set_title("Decision Tree Classification"
ax.legend(framealpha=0.5,loc='best')
plt.show()
六、代码示例
from sklearn import tree
import numpy as np
import pandas as pd
import pydotplus
from sklearn.metrics import accuracy_score
from sklearn import datasets,model_selection
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score,cross_val_predict,cross_validate
from sklearn.model_selection import validation_curve
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.metrics import recall_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.metrics import roc_auc_score
iris=datasets.load_iris() # scikit-learn 自带的 iris 数据集
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.3,random_state=0)
clf = tree.DecisionTreeClassifier(criterion='gini').fit(X_train, y_train)
y_pred=clf.predict(X_test)
print (accuracy_score(y_test,y_pred))
print (recall_score(y_test, y_pred, average='macro'))
print (recall_score(y_test, y_pred, average='micro'))
print (recall_score(y_test, y_pred, average='weighted'))
print (recall_score(y_test, y_pred, average=None))#none 返回每一类别的召回率
print (confusion_matrix(y_test, y_pred))
print (classification_report(y_test, y_pred))#F1分数,很好平衡了召回率和精准率,让二者同时达到最高,取一个平衡。
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
print (fpr,tpr,thresholds)
print (auc(fpr, tpr))
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
AUC=roc_auc_score(y, scores)
print (AUC)
七,验证曲线与学习曲线
验证曲线和学习曲线详见我的另一篇博客
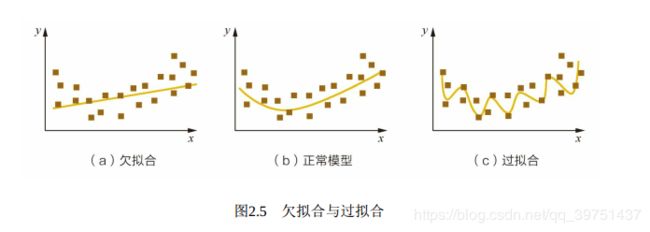
八,过拟合和欠拟合
过拟合是指模型对于训练数据拟合呈过当的情况, 反映到评估指标上, 就是
模型在训练集上的表现很好, 但在测试集和新数据上的表现较差。 欠拟合指的是
模型在训练和预测时表现都不好的情况。 图2.5形象地描述了过拟合和欠拟合的区
别。
(1)降低“过拟合”风险的方法
数据+模型+正则+集成
- 从数据入手, 获得更多的训练数据。 使用更多的训练数据是解决过拟合
问题最有效的手段, 因为更多的样本能够让模型学习到更多更有效的特征, 减小
噪声的影响。 可以通过一定的规,则来扩充训练数据。 比如, 在图像分类的问题上, 可以通过图像的平移、 旋转、缩放等方式扩充数据; 更进一步地, 可以使用生成式对抗网络来合成大量的新训练数据。 - 从模型入手,降低模型复杂度。 在数据较少时, 模型过于复杂是产生过拟合的主要因 素, 适当降低模型复杂度可以避免模型拟合过多的采样噪声。例如, 在神经网络模型中减少网络层数、 神经元个数等; 在决策树模型中降低树的深度、 进行剪枝等。
- 正则化方法。 给模型的参数加上一定的正则约束, 比如将权值的大小加入到损失函数中。
- 集成学习方法。 集成学习是把多个模型集成在一起, 来降低单一模型的过拟合风险, 如Bagging方法。
(2)降低“欠拟合”风险的方法
- 添加新特征。 当特征不足或者现有特征与样本标签的相关性不强时, 模 型容易出现欠拟合。通过挖掘“上下文特征”“ID类特征”“组合特征”等新的特征, 往 往能够取得更好的效果。 在深度学习潮流中, 有很多模型可以帮助完成特征工程, 如因子分解机、 梯度提升决策树、 Deep-crossing等都可以成为丰富特征的方 法。
- 增加模型复杂度。 简单模型的学习能力较差, 通过增加模型的复杂度可以使模型拥有更强的拟合能力。 例如, 在线性模型中添加高次项, 在神经网络模型中增加网络层数或神经元个数等。
- 减小正则化系数。 正则化是用来防止过拟合的, 但当模型出现欠拟合现象时, 则需要有针对性地减小正则化系数。
参考资料
神经网络中欠拟合和过拟合的优化详见此博客
欠拟合和过拟合的一般解决方法一
欠拟合和过拟合的一般解决方法二