机器学习之路:天池智慧海洋竞赛总结
刚刚结束天池智慧海洋建设竞赛,总结一下这两个月来的感悟与收获。
1.初赛
从1月2日竞赛开始,我的队友(也是舍友)拉着我说一起打这个比赛吧,我说这个比赛奖金这么高,确定要打这个吗?队友说反正也是学习东西,再加上这个竞赛的周期 并不是很长,那么就参加吧,于是我们便一起组队了。在学校没做多久,马上便开始放寒假了,于是接下来的一个月我们便在家里参赛。前期我们两个一直在做特征,一直无脑的在做特征,疯狂的做,这里试试,那里试试,真的是无脑的试,无脑的加特征,线下好了,线上差了,便认为这个特征不好。线上好了,便认为这个特征好,真的是毫无逻辑可言,每天就在那里尝试特征,真的感觉是什么东西都没有学到,但是又没有其他的办法。就这样,时间一天一天的过,到了初赛快截至的时间了。这里因为我们没注意好时间表,导致出了大问题。
2.组队
官方说的是2月20日12点截至组队,然而我从2月20日10点30我才起床,2月20日11点发现已经快来不及了,于是我赶紧联系了舍友,让他赶紧加入我的队伍。同时,我也去联系了另外一个师兄,之前认识的一个大神。他想着反正暑假在家里也没什么事情,自己一个人做没什么动力,于是便和我们一起组队了。本来师兄还有一个还厉害的朋友,但是由于组队时间原因,很遗憾,没能和这位大神一起组队。接着因为队伍还少人,所以又去群里拉了个人,害,结果发现这个是坑坑,一点忙没帮上。组队找队友非常重要,一定要重视,还好拉上了师兄和我们一起,跟着师兄学到了很多东西,收益匪浅。
3.准备复赛
这期间我又在群里水了一波,发现水群还是有点好处的,在我们做特征做的没有进展的时候,发现一位同学用的是另一种方法做的nn,后面一聊,还是校友,两个人也交流了很多,收获了很多,或许以后还能一起组队,哈哈。我对这块的知识是似懂非懂,但是师兄正好是科班出身,而且懂一些,于是我们3人便分工了,让舍友去做特征,我跟着师兄去做基于NLP方法的nn。初赛B榜的时候我们特征还算不错,单模掉了8个千,也还是顺利的进入到了复赛,前120名,还是比较轻松的。
4.复赛
初赛我们尝试了一下nn,但是没做出来什么效果,复赛的时候我们继续做,我和师兄一起在做,用keras包做词嵌入,这个过程我是学到了很多的东西,从不动NLP,不懂搭网络,到慢慢的了解到一些知识,收获很多。实践的时候,真的很多东西会理解的深入得多,之前只是看书,什么epoch,batch_size,earlyStopping都似懂非懂,实践使用之后,理解深入多了。调的过程中,我们前期f1_score一直在84左右,上不来,后来无意中发现是滤波器设置的问题,改了滤波器之后,效果好了很多。这里贴上我们的Textcnn代码:
def textcnn(Vob_length, Vob_length1, Vob_length2, seq_size, embedding_matrix=None):
""" TextCNN: 1. embedding layers, 2.convolution layer, 3.max-pooling, 4.softmax layer. """
x_input = Input(shape=(seq_size,))
x_input1 = Input(shape=(seq_size,))
x_input2 = Input(shape=(seq_size,))
if embedding_matrix is None:
x_emb1 = Embedding(input_dim=Vob_length, output_dim=128, input_length=seq_size)(x_input)
else:
x_emb1 = Embedding(input_dim=Vob_length, output_dim=32, input_length=seq_size,
weights=[embedding_matrix], trainable=True)(x_input)
if embedding_matrix is None:
x_emb2 = Embedding(input_dim=Vob_length1, output_dim=128, input_length=seq_size)(x_input1)
else:
x_emb2 = Embedding(input_dim=Vob_length1, output_dim=32, input_length=seq_size,
weights=[embedding_matrix], trainable=True)(x_input1)
if embedding_matrix is None:
x_emb3 = Embedding(input_dim=Vob_length2, output_dim=128, input_length=seq_size)(x_input2)
else:
x_emb3 = Embedding(input_dim=Vob_length2, output_dim=32, input_length=seq_size,
weights=[embedding_matrix], trainable=True)(x_input2)
x_emb = Add()([x_emb1, x_emb2, x_emb3])
pool_output = []
kernel_sizes = [2, 3, 4]
for kernel_size in kernel_sizes:
c = Conv1D(filters=256, kernel_size=kernel_size, strides=1)(x_emb)
p = MaxPool1D(pool_size=int(c.shape[1]))(c)
pool_output.append(p)
pool_output = concatenate([p for p in pool_output])
x_flatten = Flatten()(pool_output) # (?, 6)
drop = Dropout(0.5)(x_flatten)
y = Dense(3, activation='softmax')(drop) # (?, 2)
model = Model([x_input, x_input1, x_input2], outputs=[y])
return model
评价函数及f1
class Metrics(Callback):
def __init__(self, filepath):
self.file_path = filepath
def on_train_begin(self, logs=None):
self.val_f1s = []
self.best_val_f1 = 0
self.val_recalls = []
self.val_precisions = []
def on_epoch_end(self, epoch, logs=None):
val_predict = np.argmax(np.asarray(self.model.predict([self.validation_data[0], self.validation_data[1], self.validation_data[2]])),
axis=1)
val_targ = np.argmax(self.validation_data[3], axis=1)
_val_f1 = f1_score(val_targ, val_predict, average='macro')
self.val_f1s.append(_val_f1)
print(' — val_f1:', _val_f1)
print("max f1:", max(self.val_f1s))
if _val_f1 > self.best_val_f1:
self.model.save_weights(self.file_path, overwrite=True)
self.best_val_f1 = _val_f1
print("best f1: {}".format(self.best_val_f1))
else:
print("val f1: {}, but not the best f1".format(_val_f1))
return
def f1(y_true, y_pred):
def recall(y_true, y_pred):
"""Recall metric.
Only computes a batch-wise average of recall.
Computes the recall, a metric for multi-label classification of
how many relevant items are selected.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
"""Precision metric.
Only computes a batch-wise average of precision.
Computes the precision, a metric for multi-label classification of
how many selected items are relevant.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall + K.epsilon()))
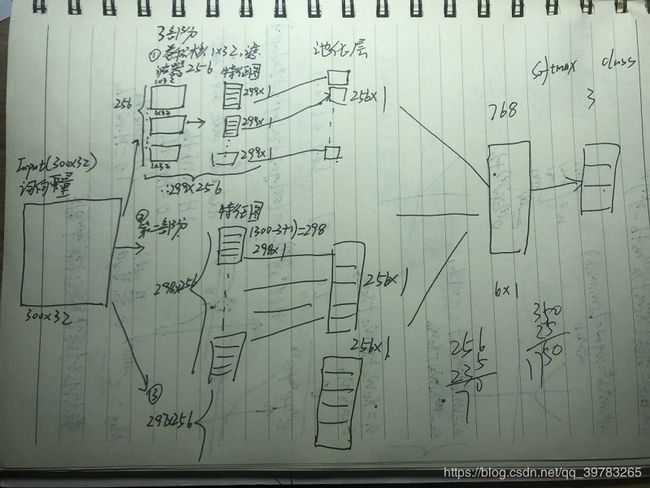
我们后面尝试做了3个Embedding,如果只是用一个Embedding,去掉其他的即可。下面是我自己画的模型框架草图。
Textcnn原理可看:
https://www.cnblogs.com/ModifyRong/p/11319301.html
5.所遇问题及一路坎坷
在我们把nn调到0.885左右,单模lgb线上调到0.889的时候,接下来便开始做模型融合了,在这里真的是遇到了大问题。上文中所提到的校友,他们的方案是用nn与lgb投票然后取概率最大方法做的融合,我们的方案和他的方案其实是差不多的,但是不管我们怎么融合,效果一直不行,反而不如单模好,连最极端的办法,给nn一个权重,来取两者概率最大,结果还是不如单模,真的是都绝望了。后面调试的时候发现,lgb中的
multi-class classification
multiclass, softmax 目标函数, 应该设置好 num_class
multiclassova, One-vs-All 二分类目标函数, 应该设置好 num_class
我们用的是multiclassova,因为舍友调的单模,一直用的OVA,预测的结果小类是要好的,因为没有深入理解这两个的输出的不同,而且网上也并没有两者用法上的区别,导致我们后面没办法去做修改了,进了死胡同。
区别:
multiclass:输出接的Softmax,直接是归一化之后的概率,不同类别概率相加为1.
multiclassova:这个函数,输出不同类别的概率竞赛不为1!!!!!!这样导致我们没办法去和nn直接比较概率
后面我们对lgb的输出做了softmax去做stacking,果然还是这个问题,直接将我们的成绩0.889提升到了0.898,进入前20,但复赛还是崩了!!如果用的multiclass去比较概率,应该是不会崩的。。
6.结果及感悟
复赛A榜我们是18名,因为后面发现了那个问题,但是B榜,我们一直掉了1.8个百,导致我们最后排名是26,还是挺遗憾的。
赛后很多前排大佬在群里开始分享经验,真的是神仙打架,本来因为没进前20还挺失望的,但是后面发现,自己B榜崩了,还是有崩的道理的,水平还不够。像群里的林有夕大佬,用了对抗验证来判断训练集与测试集的分布,真的是很厉害。总的来说,2个多月来,也算是有很大的收获了,接下来多学习大佬们的方法,继续提高自己,其中第一次打正式比赛,最终26/3275,也还不错了啊哈哈哈(强行安慰自己一波~)
希望有共同兴趣的可以给我留言,可以一起交流,或者一起打比赛!~~~