机器学习算法笔记——KNN算法k近邻详解
一、什么是KNN(k近邻)算法?
简单来说KNN算法就是通过在训练数据中找到最接近预测数据的均值,比如现在有一个人想要知道他的房子在某同城能租到的价格,他拿到了最近一年的所有租房记录(模拟训练数据)
| accommodates(容纳人数) | bedrooms(卧室数量) | bathrooms(卫生间数量) | price(价格) |
|---|---|---|---|
| 3 | 1 | 1 | 85 |
| 4 | 2 | 1 | 100 |
| 4 | 2 | 2 | 108 |
| 1 | 1 | 1 | 60 |
| 2 | 1 | 1 | 79 |
| 10 | 4 | 3 | 280 |
他的房子数据是(测试数据)
| accommodates(容纳人数) | bedrooms(卧室数量) | bathrooms(卫生间数量) | price(价格) |
|---|---|---|---|
| 2 | 2 | 1 | ? |
在不考虑其他因素(有时候同样数据却因为某些原因租出了不同的价格)
他的房子租价范围是79-100,这个范围我相信大家肯定是通过寻找最接近他房子数据的租房记录也就是训练数据得到的
实际生活中我们的租房记录会有上亿条,我们的评价标准也不可能只有人数、卧室、卫生间,所以我们需要用机器来预测
二、KNN算法思想?
我们通过计算测试数据与训练数据集每个样本的差异,找到差异最小的前K条数据,并对前K预测列求平均值
本案例 通过 accommodates(容纳人数) bedrooms(卧室数量) bathrooms(卫生间数量) 等指标 找到训练数据中与他最相似的K条数据的price 我们对这K条数据price求平均值
三、KNN算法实现?
环境: Anaconda
难度:★☆☆☆☆
我们需要将训练数据给我们python,同时也需要把测试数据给python
我就使用租房的数据
数据源 : 百度云:8wv0
我们只使用以下数据特征:
accommodates: 可以容纳的旅客
bedrooms: 卧室的数量
bathrooms: 厕所的数量
beds: 床的数量
price: 每晚的费用
minimum_nights: 客人最少租了几天
maximum_nights: 客人最多租了几天
number_of_reviews: 评论的数量
#1.读取数据
import pandas as pd
df = pd.read_csv("./listings.csv")

我们导入数据后我们就要开始做模型预测了,这里我们就采用KNN算法,但是如果我们直接把df作为训练集,训练出来的模型不能保证这个模型一定是拟合的(好用的),好不好用就是我预测出来的与真是值差异,当然是差异越小模型约好用
我们暂时认为模型拟合决定因素有两点:
- 数据源是否正确
- 你的算法
首先我们的数据是正确的,算法KNN也是可行的,那么我们是不是应该拿一部分数据用来评测我的模型呢
我们可以从df中拿出一部分数据用来测试模型,因为拿出来数据已经有实际的price 我们用拿出来的数据进行预测,预测出的price和实际price进行对比就可以看出我的模型是否好用
既然我们要对df切分,一般的数据拿到后每条数据都会有分布规律,有的数据是price从小到大排序的,如果不对数据洗牌的话
我们的训练集有可能全部价格是这个区间(0,200)而测试集都是(200,500) ,如果打乱后我们的数据将不再有规律分布
#现选取我用到的列
features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
features_data = df[features]
#数据洗牌 下面会讲解为什么要对数据进行洗牌
features_data = features_data.sample(frac=1,random_state=0)
现在我们有了数据,我们在做算法前应该对数据预处理
我们本次数据有3个地方需要进行预处理
- price列我们需要从object类型转换到float64
- 我们需要对数据进行标准化处理
- 分为训练集和测试集
#1.price数据类型转换 我们需要去掉 $ ,
features_data["price"] = features_data["price"].str.replace("\$|,",'').astype(float)
#2.标准化 我们下面详细讲解标准化 我们暂且先去掉含有NaN的样本
features = features.dropna()
#2.将df分割成两部分一部分为train_data一部分为test_data
train_data = features_data.iloc[:3000]
test_data = features_data.iloc[3000:]
我们在评测数据的时候我们采用欧式距离来表示 训练集和测试集数据之间的差异

d代表欧式距离 两个样本之间的差异大小
其中Q1到Qn是一条数据的所有特征信息,P1到Pn是另一条数据的所有特征信息
我们最后要取前d最小的前K条price 求平均值
如果我的训练数据是
![]()
测试数据是
![]()
这两条数据的欧式距离是很大的 因为maximum_nights相差巨大但是maxmaximum_nights却不是影响价格的最直接的因素,而其他列都无明显差异,如果不预处理数据,一旦某列数据出现极值就会出现单列对整体欧式影响过大
数据标准化(normalization)
1.z-score 标准化
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。
x* = (x - μ ) / σ
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
2.归一化
把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
x = (x−min)/(max−min)
#实现标准化 这里采用z-score 标准化
def normalize(col_series):
#求出每列平均值
col_mean = col_series.mean()
#求出每列的标准差
col_std = col_series.std()
#求出标准化后的值
col_series = (col_series-col_mean)/col_std
return col_series
stand_features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
features_data[stand_features] = features_data[stand_features].apply(normalize,axis="rows")
标准化后每列的数据都在小区间范围上,这样即使我的有极端值对整体的影响也不会很大
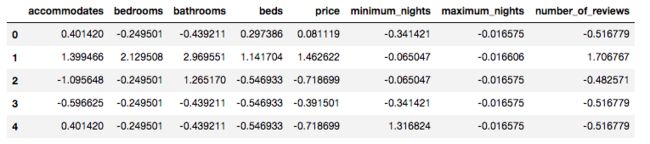
下一步我们就要求出每条测试集对应每条训练集的欧式距离,并且取前K个最小距离求平均值得出预测price
#欧式距离计算比较复杂我们用scipy库来求欧式距离
from scipy.spatial import distance
#4.预测price
def ass_price(row_series,feature,k):
#拿到每行测试数据
test_series = row_series[feature]
#我们将训练数据拷贝一份
temp_train_data = train_data.copy()
#求出测试数据对应每条训练数据的欧式距离 并赋值给distance新列 注意:每一次新测试数据都会覆盖上一次训练数据的欧式距离
#只要求出当前的price 下一次预测对于上一次没有依赖所以覆盖无影响
temp_train_data["distance"] = temp_train_data[feature].apply(distance.euclidean,args=(test_series,),axis="columns")
#将欧洲距离排序
temp_train_data.sort_values("distance",inplace=True)
#提取前k条
temp_price = temp_train_data.price.iloc[0:k+1]
#求平均值
mean_price = temp_price.mean()
return mean_price
#指定参加评测的列
ass_features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
#求出每条测试数据的预测price 通过args参数指定k值args=(ass_features,5,) 此时k值为5
test_data["train_price"] = test_data.apply(ass_price,args=(ass_features,5,),axis="columns")
现在我们的KNN算法就已经实现了
我们的test_data中多了一个train_price列,里面就是我们预测的价格,让我们来看看和实际价格的差异吧
print(test_data.loc[:,["price","train_price"]])
"""
price train_price
1104 0.008407 0.062932 看到输出的结果应该是出错了
307 3.054571 3.056994 但是并没有出错第一列为索引 第二列为实际价格 第三列为模型给出的价格
2818 -0.435068 -0.353886 因为我们的price和train_price列都是经过标准化处理的值
2059 -0.173345 0.152597 如果想更直观,标准化的时候stand_features可以不指定price列 毕竟price列没有参与ass_price模型评估
872 3.279943 2.841315 我们的训练集是[0:3000] 测试集是[3000:]
3115 -0.246046 -0.270280 通常训练集的量要大与测试集
86 1.825927 1.796847
2826 -0.464148 -0.185462
3108 -0.449608 -0.421740
2753 0.008407 -0.055812
3130 -0.136995 -0.243623
3113 0.190159 0.407050
2830 -0.609550 -0.373272
1435 -0.391448 -0.395083
2610 -0.427798 -0.422951
209 1.062569 0.946247
3220 -0.216966 -0.093374
2787 -0.864003 -0.762222
1966 -0.718601 -0.465360
2642 -0.064294 -0.256951
1987 0.917167 0.794787
2171 -0.209696 -0.301783
2782 -0.427798 -0.399929
931 -0.282396 -0.264221
2146 -0.318747 -0.347827
2425 -0.355097 -0.339345
130 0.371911 0.244684
1723 -0.609550 -0.487170
2071 -0.435068 -0.402353
3455 0.008407 -0.230294
... ... ...
"""
我们已经得到了预估房价的模型,但是我们的模型是否好用,我们需要给模型打分
模型评估
root mean squared error (RMSE)均方根误差

求出实际价格与预测价格的均方根误差就可以了
import numpy as np
temp = (test_data["train_price"]-test_data["price"])**(2)
temp = temp.mean()
grades = np.sqrt(temp)
print(grades)
0.2565267099411877
我们模型评估结果0.2565267099411877
总结KNN算法:
- 读取数据
- 数据预处理 -格式转换 -标准化 -分训练集和测试集
- 测试集通过系数(案例采用欧式距离)前K条平均值得出预测值
- 模型评估
非常欢迎各位学员学习讨论