分布式消息队列——Kafka归纳笔记
什么是Kafka:
kafka是Apache开发的一个开源流处理平台,他是一个可持久化的分布式消息队列,存储数据流时可以以一种容错的方式来存储,可以类比副本冗余机制(一条消息可以设置多副本)。数据发生时还可以处理数据。
kafka特点
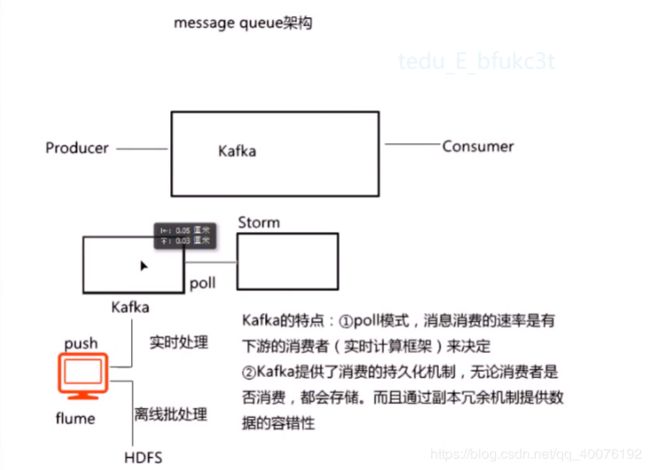
1.kafka可以用来构建实时流处理系统(结合Storm)
2.消息的消费速度是由下游消费者决定的,俗称poll模式。
3.kafka提供了持久化机制,不管你消不消费,我数据都存着。
4.kafka是一种分布式结构,保证吞吐海量数据且数据不丢失。
kafka的整体结构图:
Kafka配置:
在配置Kafka之前,要先启动zookeeper集群。
1.进入kafka的config目录,编辑server.properties ,设置broker.id=0,zookeeper.connect=master:2181,slave1:2181,slave2:2181,
log.dirs=/usr/utils/kafka_2.10-0.10.2.1/kafka-logs
保存退出。
2.启动kafka:
指定以哪个配置文件启动。
sh kafka-server-start.sh ../config/server.properties
出现以下信息表示成功。

3.我们进入zookeeper客户端,进入borkers节点:

再进入ids节点:
![]()
我们可以看到0这个数字,当我们主动停止kafka时,0消失。这也就是说,kafka在启动时会向该节点注射自己的临时节点,关闭时自己的节点消失。
Kafka的使用
1.创建自定义的topic:
执行命令:
sh kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partition 1 --topic jbook
这里的replication-factor我们设置为1,因为我们只启动了一台broker,如果写大于brokers的数量会报larger than available brokers 错误,partition数量也定为1,主题名称叫做jbook。如果创建成功,会出现下图:

2.现在我们来看下kafka到底有多少个topic。使用命令:
sh kafka-topics.sh --list --zookeeper master:2181
从上述指令可以看到输入了zookeeper,那也就是说topic的信息除了kafka自己有一份,zookeeper也有一份。先来看kafka的topic信息(如果第一次用kafka,就只有刚才创建的topic)

再来看下zookeeper中的信息:
进入zookeeper客户端查看,有以下信息:

3.往刚才创建的主题中生产数据:
我们输入生产者线程指令:
sh kafka-console-producer.sh --broker-list master:9092 --toc jbook
我们启动一个produce线程模拟生产者往jbook主题中生产数据,然后向kafka发送一个hello kafka信息。

我们前面说过kafka提供了消息的持久化机制,那就是说这个hello kafka字符串被持久化到某一个文件中了。我们找一下,进入kafka-logs文件夹查看,可以看到我们jbook-0文件夹,进入该目录,我们可以看到三个文件:

我们查看.log文件会有如下数据:

刚才的hello kafka字符串被持久化到该文件中。
有人肯定会问zookeeper有这数据吗?答案是没有,因为zookeeper不是设计来存数据的,它只存储少量元数据做协调服务,而且每个znode存储的元数据不超过1M。
就像刚才我们看到的,那个目录叫做jbook-0,后边的这个0代表什么呢?他明明可以直接叫做jbook。还记得我们创建的topic命令吗?我们设计了partitions 为1,意思是分区数为1。
那我们重新创建一个主题,其他信息不变,只是把partitions改为2,topic名字改为cnbook即可。
我们再次进入kafka-logs目录,可以看到如下:
![]()
生成了两个目录。那就是说,partitions的数量对应着所生成topic的目录个数,它就是个目录。
现在也许有人会问,kafka引入这个分区机制到底有什么用?
kafka是一个分布式消息队列,那也就是说在实际情况中kafka集群有多台主机,kafka可以将存储数据的分区存储在其他主机上,做到了数据的分布式存储。
也许还有人问,刚才创建topic时还有一个参数,叫做replication-factor,我们给它设置为1,这个属性就是用来设置副本数量的,也就是分区的副本数量,,设置为1,那它存储的分区就放在一台主机上,如果改为2,kafka就会以一种自动负载均衡的方式将分区放在另一个主机上,副本数再累加也是同理但是不能超过brokers数量。
4.启动消费者来消费我们刚才生产的数据:
使用命令:
sh kafka-console-consumer.sh --zookeeper master:2181 --topic jbook --from-beginning
运行后会有如下图:

很显然,数据被消费者线程找到并打印。
现在我们再使用producer线程生产数据:

只要一生产数据,consumer线程就会立即消费一条。
现在做一下kafka的小概括:

Topic和Partition
生产者生产数据的本质是往分区里写数据:

这种写数据属于追加方式,而追加属于磁盘顺序写,所以kafka写入性能很高。
Offset(偏移量)
kafka在写入每条消息时都会添加一个offset(偏移量)
consumer从broker读到数据后,可以选择commit,该操作会在kafka中保存该cousumer在分区中读到消息的offset,该consumer下次再读取这分区时,会从下一条开始读取。这一特性可以保证消费者不会在kafka中重复读取数据。