初学爬虫:网页乱码问题
初学爬虫:网页乱码问题
- 问题
- 解决方案
问题
初学爬虫,按照教程Jack Cui爬虫教程 ,采用如下代码获取网页。
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
print(req.text)得到的了下图所示的乱码。
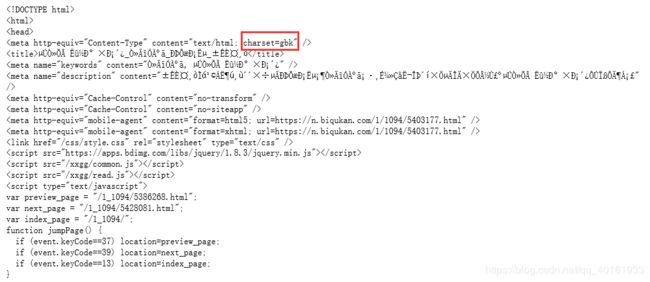
我们可以发现,该网页的字符集类型采用的是 GBK 编码格式。
这是因为 Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。Requests 推测的文本编码与网页的实际编码是不同的。我们可以利用如下函数查看推测的编码类型。
print(req.encoding) #查看网页返回的字符集类型
print(req.apparent_encoding) #自动判断字符集类型
运行结果为:
ISO-8859-1
GB2312
可以看出 Requests 推测的文本编码(也就是网页返回即爬取下来后的编码转换)与源网页编码不一致,这正是导致乱码原因。
解决方案
import requests
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
req.encoding = "gbk" #增加这一句
print(req.text)