【Python爬虫实例学习篇】——4、超详细爬取bilibili视频
【Python爬虫实例学习篇】——4、超详细爬取bilibili视频
由于经常在B站上学习,但无奈于家里网络太差,在线观看卡顿严重,于是萌生了下载视频的想法(如果只是单纯想下载视频,请用you-get库)。废话不多说直接开干。
(我发现好像很多人在爬bilibili视频的时候都有用到某个API然后还需要一个cid参数,这些在本文中没有用到。。。。)(另外再说明一下,第3篇文章没有通过审核,要看的话去公众号哈哈)
个人博客地址:https://www.asyu17.cn
使用工具
- python3.6
- requests库
- lxml库(xpath解析)
- json库(解析json数据获取下载链接)
- ffmpeg(合并视频和音频)
目录
- 确定视频资源地址
- 下载测试
- 下载视频和音频(两种方法)
- 合并视频和音频
- BiliBiliVideo.py
- 运行结果
1、确定视频资源地址
(1) 用Chrome随便打开一个视频,Ctrl+Shift+C选择视频框尝试获取视频的链接。结果发现获取的链接地址为:blob:https://www.bilibili.com/198785ae-c0e6-48c1-b27b-36c5af8935c6 ,这是一个blob加密的链接,不能直接访问。
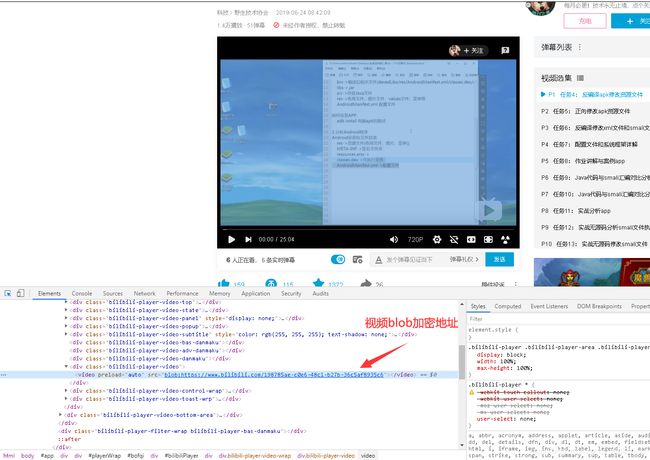
(2) 网上查找资料后,这篇文章给了我灵感,思路:对网页抓包,抓取到视频分片的链接,再利用所抓到的链接信息进行定位。
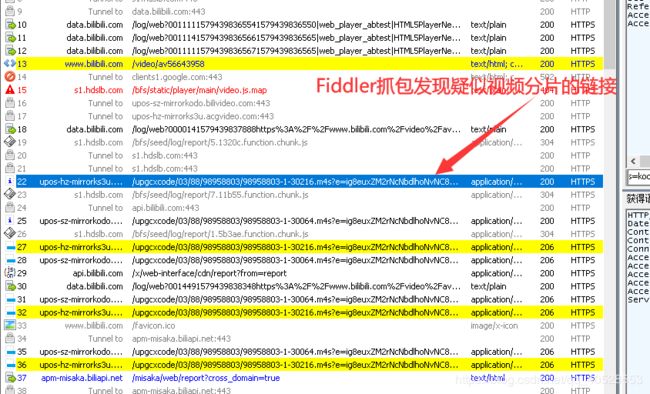
(3) 可以定位到所有视频分片的信息全部来源于 https://www.bilibili.com/video/av56643958
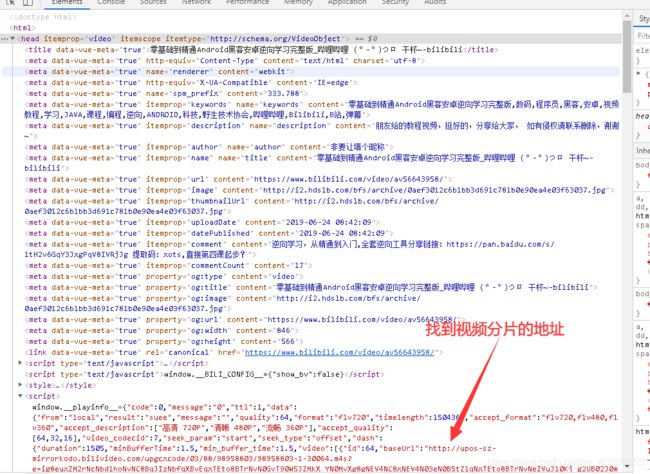
(4) 对这部分json代码进行解析(完整json数据太大,请自行去 B站 找到对应位置观看),可以发现:
quality参数是指视频清晰度,112为高清1080p+、80为高清1080p、64为高清、32为清晰、16为流畅。
duration参数是指视频长度,单位为秒。
frameRate参数为帧率。
SegmentBase参数应该是视频片初始片大小和片基址范围,单位为字节。
deadline参数是在url里的参数,指示了链接失效的时间戳。
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"from": "local",
"result": "suee",
"message": "",
"quality": 64,
"format": "flv720",
"timelength": 1504366,
"accept_format": "flv720,flv480,flv360",
"accept_description": [
"高清 720P",
"清晰 480P",
"流畅 360P"
],
"accept_quality": [
64,
32,
16
],
"video_codecid": 7,
"seek_param": "start",
"seek_type": "offset",
"dash": {
"duration": 1505,
"minBufferTime": 1.5,
"min_buffer_time": 1.5,
"video": [
{
"id": 64,
"baseUrl": "http://upos-sz-mirrorkodo.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30064.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=kodobv&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=4b952dd652c9922b546b99e44756fe0a&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151",
"base_url": "http://upos-sz-mirrorkodo.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30064.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=kodobv&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=4b952dd652c9922b546b99e44756fe0a&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151",
"backupUrl": [
"http://upos-sz-mirrorks3.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30064.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=ks3bv&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=62448ee8270504e8e729d25fc402dc7f&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151"
],
"backup_url": [
"http://upos-sz-mirrorks3.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30064.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=ks3bv&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=62448ee8270504e8e729d25fc402dc7f&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151"
],
"bandwidth": 359889,
"mimeType": "video/mp4",
"mime_type": "video/mp4",
"codecs": "avc1.64001F",
"width": 960,
"height": 534,
"frameRate": "25",
"frame_rate": "25",
"sar": "801:800",
"startWithSap": 1,
"start_with_sap": 1,
"SegmentBase": {
"Initialization": "0-995",
"indexRange": "996-4639"
},
"segment_base": {
"initialization": "0-995",
"index_range": "996-4639"
},
"codecid": 7
},
// 此处省略部分数据
{
"id": 30216,
"baseUrl": "http://upos-hz-mirrorks3u.acgvideo.com/upgcxcode/03/88/98958803/98958803-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=ks3u&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=669eccff96c56f5586d174870a496b12&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151",
"base_url": "http://upos-hz-mirrorks3u.acgvideo.com/upgcxcode/03/88/98958803/98958803-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=ks3u&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=669eccff96c56f5586d174870a496b12&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151",
"backupUrl": [
"http://upos-sz-mirrorks3.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=ks3bv&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=b6d7b3957f5dbcbf686f267851ec42dd&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151"
],
"backup_url": [
"http://upos-sz-mirrorks3.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579449043&gen=playurl&os=ks3bv&oi=1971869914&trid=9412dee30c4640c6907ef910ea2cb04cu&platform=pc&upsig=b6d7b3957f5dbcbf686f267851ec42dd&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151"
],
"bandwidth": 67100,
"mimeType": "audio/mp4",
"mime_type": "audio/mp4",
"codecs": "mp4a.40.2",
"width": 0,
"height": 0,
"frameRate": "",
"frame_rate": "",
"sar": "",
"startWithSap": 0,
"start_with_sap": 0,
"SegmentBase": {
"Initialization": "0-907",
"indexRange": "908-4551"
},
"segment_base": {
"initialization": "0-907",
"index_range": "908-4551"
},
"codecid": 0
}
]
}
},
"session": "da9c24388db43b3dfe81ebd676d5e41b",
"videoFrame": { }
}
}
2、下载测试
(1) 既然确定了上述链接就是我们要请求的视频链接,那么尝试直接发送获取请求看看。
结果。。。。403错误,服务器拒绝访问。

(2) 继续回到Fiddler检查抓包数据发现,同一链接反复出现。仔细观察返回码发现:返回码为200时无数据、请求方式为OPTIONS,返回码为206时有数据、请求方式为GET。查阅资料后猜测,在获取b站视频之前需要用OPTION方式向请求服务器分配资源,然后再用GET方式获取视频分片。

(3) 下面进行获取一个视频分片的测试,考虑到不管是这个OPTIONS请求还是GET请求,其connect属性皆是kepp-alive,考虑使用requests.session()来保持会话。
import requests
# url1 为视频链接、url2为音频链接
url='https://cn-hbwh2-cmcc-bcache-07.bilivideo.com/upgcxcode/03/88/98958803/98958803-1-30064.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579518843&gen=playurl&os=bcache&oi=1971869869&trid=0cfd59d728114a54bd4747a01f87c9bbu&platform=pc&upsig=2a9e83f3258a7e2694bc83a5fbab8664&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151&origin_cdn=ks3'
url2='http://upos-hz-mirrorks3u.acgvideo.com/upgcxcode/03/88/98958803/98958803-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1579519469&gen=playurl&os=ks3u&oi=1971869869&trid=99ee525d6c7f4bc8a414a537797e31f3u&platform=pc&upsig=ce817a7120709c60ac43cf095de05c8d&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=352741151'
headers1={
'Host': 'cn-hbwh2-cmcc-bcache-04.bilivideo.com',
'Connection': 'keep-alive',
'Access-Control-Request-Method': 'GET',
'Origin': 'https://www.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Access-Control-Request-Headers': 'range',
'Accept': '*/*',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'cors',
'Referer': 'https://www.bilibili.com/video/av56643958?t=262',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
headers2={
'Host': 'cn-hbwh2-cmcc-bcache-04.bilivideo.com',
'Connection': 'keep-alive',
'Origin': 'https://www.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Accept': '*/*',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'cors',
'Referer': 'https://www.bilibili.com/video/av56643958?t=262',
'Accept-Encoding': 'identity',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Range': 'bytes=0-907'
}
session=requests.session()
session.options(url=url1,headers=headers1)
res=session.get(url=url1,headers=headers2)
print(res)
with open('test1.mp4','wb') as fp:
fp.write(res.content)
fp.flush()
fp.close()
发现是能够成功下载视频的,但是该视频不能打开。
(4) 重新设置Range的范围为’Range’: ‘bytes=0-4639000’ 后,视频大小为4.42MB,能够正常观看时长为59秒(视频无声音)。猜测:之前下载的908字节不足以构成一个(该视频分辨率为960*534,故猜测应该是62.57kb构成一个画面),另外视频无声音,查找资料后得知,B站的视频和音频是分离的(此时联想到json解析最后一组数据没有分辨率,猜测可能是音频的链接)。
验证成功,最后一个链接为音频的链接
3、下载视频和音频(两种方法)
方法1:取消range参数直接一次下载整个视频或音频
方法2:利用416报错码进行分片下载,每次下载1MB的资源,最后一次将range设置为,‘Range’: ‘bytes=上一次末尾-’。从而实现分片下载。

代码如下:
import requests
import json
from lxml import etree
# 防止因https证书问题报错
requests.packages.urllib3.disable_warnings()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Referer': 'https://www.bilibili.com/'
}
def GetBiliVideo(homeurl,session=requests.session()):
res = session.get(url=homeurl, headers=headers, verify=False)
html = etree.HTML(res.content)
videoinforms = str(html.xpath('//head/script[3]/text()')[0])[20:]
videojson = json.loads(videoinforms)
# 获取视频链接和音频链接
VideoURL = videojson['data']['dash']['video'][0]['baseUrl']
AudioURl = videojson['data']['dash']['audio'][0]['baseUrl']
print(videojson)
#获取视频资源的名称
name = str(html.xpath("//h1/@title")[0].encode('ISO-8859-1').decode('utf-8'))
# 下载视频和音频
BiliBiliDownload(url=VideoURL, name=name + '_Video', session=session)
BiliBiliDownload(homeurl,url=AudioURl, name=name + '_Audio', session=session)
def BiliBiliDownload(homeurl,url, name, session=requests.session()):
headers.update({'Referer': homeurl})
session.options(url=url, headers=headers,verify=False)
# 每次下载1M的数据
begin = 0
end = 1024*512-1
flag=0
while True:
headers.update({'Range': 'bytes='+str(begin) + '-' + str(end)})
res = session.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
begin = end + 1
end = end + 1024*512
else:
headers.update({'Range': str(end + 1) + '-'})
res = session.get(url=url, headers=headers,verify=False)
flag=1
with open(name + '.mp4', 'ab') as fp:
fp.write(res.content)
fp.flush()
# data=data+res.content
if flag==1:
fp.close()
break
4、合并视频和音频
合并视频和音频我查阅了很多资料,最终决定使用ffmpeg来完成这一操作。z在用合并之前,需要先去安装ffmpeg,详情请参考这篇文章 ffmpeg安装。若是运行过程中出现ffmpeg+一堆乱码,可以参考这篇文章。
下面是合并音频代码:
- 需要先在ffmpeg库的video方法中添加如下代码:
# 组合音频和视频 (自己加的)
def combine_audio(video_file, audiio_file, out_file):
try:
cmd ='D:/python/ffmpeg-20200115-0dc0837-win64-static/bin/ffmpeg -i '+video_file+' -i '+audiio_file+' -acodec copy '+out_file
print(cmd)
subprocess.call(cmd, shell=True) # "Muxing Done
print('Muxing Done')
if res != 0:
return False
return True
except Exception:
return False
- 随后在自己的BiliBiliVideo.py中调用如下代码即可
# 一下path都需要使用全路径
def CombineVideoAudio(videopath,audiopath,outpath):
ffmpeg.video.combine_audio(videopath,audiopath,outpath)
5、BiliBiliVideo.py
以下是完整代码:
import requests
import json
from lxml import etree
import ffmpeg.video
import os
requests.packages.urllib3.disable_warnings()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36',
'Referer': 'https://www.bilibili.com/'
}
def GetBiliVideo(homeurl,num,session=requests.session()):
res = session.get(url=homeurl, headers=headers, verify=False)
html = etree.HTML(res.content)
videoinforms = str(html.xpath('//head/script[3]/text()')[0])[20:]
videojson = json.loads(videoinforms)
# 获取详情信息列表
#listinform = str(html.xpath('//head/script[4]/text()')[0])
listinform = str(html.xpath('//head/script[4]/text()')[0].encode('ISO-8859-1').decode('utf-8'))[25:-122]
listjson=json.loads(listinform)
# 获取视频链接和音频链接
try:
# 2018年以后的b站视频,音频和视频分离
VideoURL = videojson['data']['dash']['video'][0]['baseUrl']
AudioURl = videojson['data']['dash']['audio'][0]['baseUrl']
flag=0
except Exception:
# 2018年以前的b站视频,格式为flv
VideoURL = videojson['data']['durl'][0]['url']
flag=1
# 获取文件夹的名称
dirname = str(html.xpath("//h1/@title")[0].encode('ISO-8859-1').decode('utf-8'))
if not os.path.exists(dirname):
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(dirname)
print('目录文件创建成功!')
# 获取每一集的名称
name=listjson['videoData']['pages'][num]['part']
print(name)
# 下载视频和音频
print('正在下载 "'+name+'" 的视频····')
BiliBiliDownload(homeurl=homeurl,url=VideoURL, name=os.getcwd()+'/'+dirname+'/'+name + '_Video.mp4', session=session)
if flag==0:
print('正在下载 "'+name+'" 的音频····')
BiliBiliDownload(homeurl=homeurl,url=AudioURl, name=os.getcwd()+'/'+dirname+'/'+name+ '_Audio.mp3', session=session)
print('正在组合 "'+name+'" 的视频和音频····')
# CombineVideoAudio(name + '_Video.mp4',name + '_Audio.mp3',name + '_output.mp4')
print(' "'+name+'" 下载完成!')
def BiliBiliDownload(homeurl,url, name, session=requests.session()):
headers.update({'Referer': homeurl})
session.options(url=url, headers=headers,verify=False)
# 每次下载1M的数据
begin = 0
end = 1024*512-1
flag=0
while True:
headers.update({'Range': 'bytes='+str(begin) + '-' + str(end)})
res = session.get(url=url, headers=headers,verify=False)
if res.status_code != 416:
begin = end + 1
end = end + 1024*512
else:
headers.update({'Range': str(end + 1) + '-'})
res = session.get(url=url, headers=headers,verify=False)
flag=1
with open(name, 'ab') as fp:
fp.write(res.content)
fp.flush()
# data=data+res.content
if flag==1:
fp.close()
break
def CombineVideoAudio(videopath,audiopath,outpath):
ffmpeg.video.combine_audio(videopath,audiopath,outpath)
os.remove(videopath)
os.remove(audiopath)
if __name__ == '__main__':
# av44518113
av = input('请输入视频号:')
url='https://www.bilibili.com/video/'+av
# 视频选集
range_start=input('从第几集开始?')
range_end = input('到第几集结束?')
if int(range_start)<=int(range_end):
for i in range(int(range_start),int(range_end)+1):
GetBiliVideo(url+'?p='+str(i),i-1)
else:
print('选集不合法!')
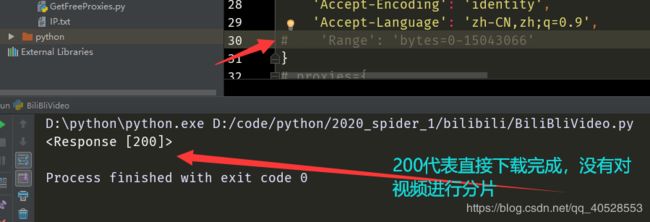
6、运行结果截图:

微信公众号:
