MyQR代码阅读
文章目录
- MyQR 代码地址
- QR二维码编码原理
- QR码的特点
- QR码结构
- 简要的编码过程
- 数据内容编码
- 1、数字模式下的编码
- 2、混合字符模式下的编码
- 3、8bit字节数据不经编码转换直接保存。
- 4、编码终止符(Terminator)
- 5、编成8bit码字
- 文件代码解析
- 文件结构
- myqr.py
- terminal.py
- MyQR.myqr
- theqrmodule.py
- constant.py
- data.py
- ECC.py
- structure.py
- matrix.py
- draw.py
- 参考文章
看了一下MyQR的源代码,查了一些资料有些原理还是没看懂,把看懂的部分记录一下。
MyQR 代码地址
github链接
QR二维码编码原理
QR码的特点
- 高速读取
- 高容量、高密度
- 支持纠错处理
- 结构化
- 扩展能力(一个QR码可以分解成多个QR码,反之,也可以将多个QR码的数据组合到一个QR码中来。)
QR码结构

- 位置探测图形、位置探测图形分隔符、定位图形:用于对二维码的定位,对每个QR码来说,位置都是固定存在的,只是大小规格会有所差异。
- 校正图形:规格确定,校正图形的数量和位置也就确定了。
- 格式信息:表示改二维码的纠错级别,分为L、M、Q、H
- 版本信息:即二维码的规格,QR码符号共有40种规格的矩阵(一般为黑白色),从21x21(版本1),到177x177(版本40),每一版本符号比前一版本 每边增加4个模块。
- 数据和纠错码字:实际保存的二维码信息,和纠错码字(用于修正二维码损坏带来的错误)。
简要的编码过程
- 数据分析
确定编码的字符类型,按相应的字符集转换成符号字符; 选择纠错等级,在规格一定的条件下,纠错等级越高其真实数据的容量越小。 - 数据编码
将数据字符转换为位流,每8位一个码字,整体构成一个数据的码字序列。其实知道这个数据码字序列就知道了二维码的数据内容。
容量:
| 格式 | 容量 |
|---|---|
| 数字 | 最多7089字符 |
| 字母 | 最多4296字符 |
| 二进制数(8 bit) | 最多2953字节 |
| 日文汉字/片假名 | 最多1817字符(采用Shift JIS) |
| 中文汉字 | 最多984字符(采用UTF-8) |
| 中文汉字 | 最多1800字符(采用BIG5) |
模式编码:
| 模式 | 指示符 |
|---|---|
| ECI | 0111 |
| 数字 | 0001 |
| 字母数字 | 0010 |
| 8位字节 | 0100 |
| 日本汉字 | 1000 |
| 中文汉字 | 1101 |
| 结构链接 | 0011 |
| FNCI | 0101(第一位置)1001(第二位置) |
| 终止符(信息结尾) | 0000 |
- 纠错编码
按需要将上面的码字序列分块,并根据纠错等级和分块的码字,产生纠错码字,并把纠错码字加入到数据码字序列后面,成为一个新的序列。 - 构造最终数据信息
按规定把数据分块,然后对每一块进行计算,得出相应的纠错码字区块,把纠错码字区块 按顺序构成一个序列,添加到原先的数据码字序列后面。 - 构造矩阵
将探测图形、分隔符、定位图形、校正图形和码字模块放入矩阵中。
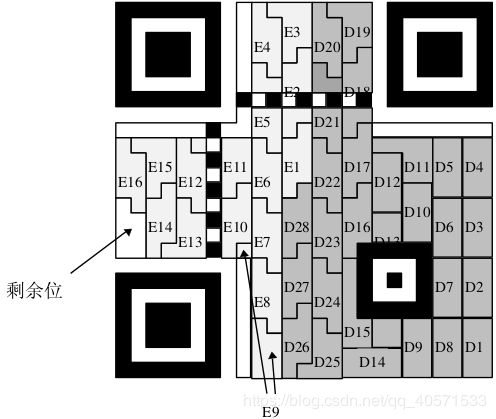
- 掩摸
将掩摸图形用于符号的编码区域,使得二维码图形中的深色和浅色(黑色和白色)区域能够比率最优的分布。 - 格式和版本信息
生成格式和版本信息放入相应区域内。
数据内容编码
1、数字模式下的编码
数据被限制为3个数字一段,分成若干段。如:“123456” 将分成"123" 和 “456”,分别被编码成10bit的二进制数。“123”的10bit二进制表示法为:0001111011,实际上就是二进制的123。
当数据的长度不足3个数字时,如果只有1个数字则用4bit,如果有2个数字就用7个bit来表示。
如:“9876"被分成"987"和"6"两段,因此被表示为"1111011011 0110”。
2、混合字符模式下的编码
字符对照表:
| 0 | 0 | A | 10 | K | 20 | U | 30 | + | 40 | ||||
| 1 | 1 | B | 11 | L | 21 | V | 31 | - | 41 | ||||
| 2 | 2 | C | 12 | M | 22 | W | 32 | . | 42 | ||||
| 3 | 3 | D | 13 | N | 23 | X | 33 | / | 43 | ||||
| 4 | 4 | E | 14 | O | 24 | Y | 34 | : | 44 | ||||
| 5 | 5 | F | 15 | P | 25 | Z | 35 | ||||||
| 6 | 6 | G | 16 | Q | 26 | [sp] | 36 | ||||||
| 7 | 7 | H | 17 | R | 27 | $ | 37 | ||||||
| 8 | 8 | I | 18 | S | 28 | % | 38 | ||||||
| 9 | 9 | j | 19 | T | 29 | * | 39 |
源码被分成两个字符一段,如下所示,每段的第一个字符乘上45,再用第二个数字相加。因此每段变成了11bit的2进制码,如果字符个数只有1个,则用6bit表示。
示例:
| “AB” | “CD” | “E1” | “23” | ||
| 45*10+11 | 45*12+13 | 45*14+1 | 45*2+3 | ||
| 461 | 553 | 631 | 93 | ||
| 0010 | 000001000 | 00111001101 | 01000101001 | 01001110111 | 00001011101 |
3、8bit字节数据不经编码转换直接保存。
4、编码终止符(Terminator)
如果编码后的字符长度不足当前版本和纠错级别所存储的容量,则在后续补"0000",如果容量已满则无需添加终止符。
5、编成8bit码字
按8bit一组,形成码字(code words)。
如果编码后的数据不足版本及纠错级别的最大容量,则在尾部补充 “11101100” 和 “00010001”,直到全部填满。
文件代码解析
文件结构
│ myqr.py
│
└─MyQR
│ myqr.py # 使用接口
│ terminal.py # 参数设置(命令行、代码)
│ __init__.py
│
└─mylibs
constant.py # 数据
data.py # 数据编码
draw.py # 生成二维码
ECC.py # 纠错编码
matrix.py # QR矩阵
structure.py # 构造最终数据信息
theqrmodule.py # 逻辑函数
__init__.py
myqr.py
# -*- coding: utf-8 -*-
# To be used just when MyQR is not installed
from MyQR.terminal import main
main()
导入MyQR模块 运行terminal.main
terminal.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from MyQR.myqr import run
import os
def main():
import argparse # 命令行参数模块
argparser = argparse.ArgumentParser()
argparser.add_argument('Words', help = 'The words to produce you QR-code picture, like a URL or a sentence. Please read the README file for the supported characters.')
argparser.add_argument('-v', '--version', type = int, choices = range(1,41), default = 1, help = 'The version means the length of a side of the QR-Code picture. From little size to large is 1 to 40.')
argparser.add_argument('-l', '--level', choices = list('LMQH'), default = 'H', help = 'Use this argument to choose an Error-Correction-Level: L(Low), M(Medium) or Q(Quartile), H(High). Otherwise, just use the default one: H')
argparser.add_argument('-p', '--picture', help = 'the picture e.g. example.jpg')
argparser.add_argument('-c', '--colorized', action = 'store_true', help = "Produce a colorized QR-Code with your picture. Just works when there is a correct '-p' or '--picture'.")
argparser.add_argument('-con', '--contrast', type = float, default = 1.0, help = 'A floating point value controlling the enhancement of contrast. Factor 1.0 always returns a copy of the original image, lower factors mean less color (brightness, contrast, etc), and higher values more. There are no restrictions on this value. Default: 1.0')
argparser.add_argument('-bri', '--brightness', type = float, default = 1.0, help = 'A floating point value controlling the enhancement of brightness. Factor 1.0 always returns a copy of the original image, lower factors mean less color (brightness, contrast, etc), and higher values more. There are no restrictions on this value. Default: 1.0')
argparser.add_argument('-n', '--name', help = "The filename of output tailed with one of {'.jpg', '.png', '.bmp', '.gif'}. eg. exampl.png")
argparser.add_argument('-d', '--directory', default = os.getcwd(), help = 'The directory of output.')
args = argparser.parse_args()
if args.picture and args.picture[-4:]=='.gif': # 如果是gif图片则解析的时间较多让用户稍作等待
print('It may take a while, please wait for minutes...')
try:
ver, ecl, qr_name = run(
args.Words,
args.version,
args.level,
args.picture,
args.colorized,
args.contrast,
args.brightness,
args.name,
args.directory
)
print('Succeed! \nCheck out your', str(ver) + '-' + str(ecl), 'QR-code:', qr_name)
except:
raise # 引起异常
可以看出MyQR运行的主要函数就是MyQR.myqr.run,可以使用命令行的形式,也可以直接调用函数。具体参数意义在二维码生成的文章里面已经说过了。
MyQR.myqr
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
from MyQR.mylibs import theqrmodule
from PIL import Image
# 必填参数
# words: str
#
# 可选参数
# version: int, from 1 to 40
# level: str, just one of ('L','M','Q','H')
# picutre: str, a filename of a image
# colorized: bool
# constrast: float
# brightness: float
# save_name: str, the output filename like 'example.png'
# save_dir: str, the output directory
#
# See [https://github.com/sylnsfar/qrcode] for more details!
def run(words, version=1, level='H', picture=None, colorized=False, contrast=1.0, brightness=1.0, save_name=None, save_dir=os.getcwd()):
# 支持的字符
supported_chars = r"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz ··,.:;+-*/\~!@#$%^&`'=<>[]()?_{}|"
# 检查参数是否正确
# 看样子这好像不支持输入中文啊
if not isinstance(words, str) or any(i not in supported_chars for i in words):
raise ValueError('Wrong words! Make sure the characters are supported!')
# QR码的最大容量取决于选择的版本、纠错级别和编码模式。这里支持40个版本。
if not isinstance(version, int) or version not in range(1, 41):
raise ValueError('Wrong version! Please choose a int-type value from 1 to 40!')
# 纠错能力 L:约%7 M:约%15 Q:约%25 H:约%30
if not isinstance(level, str) or len(level)>1 or level not in 'LMQH':
raise ValueError("Wrong level! Please choose a str-type level from {'L','M','Q','H'}!")
# 背景图片只支持jpg, png, bmp, gif
if picture:
if not isinstance(picture, str) or not os.path.isfile(picture) or picture[-4:] not in ('.jpg','.png','.bmp','.gif'):
raise ValueError("Wrong picture! Input a filename that exists and be tailed with one of {'.jpg', '.png', '.bmp', '.gif'}!")
# gif图片只能导出gif图片
if picture[-4:] == '.gif' and save_name and save_name[-4:] != '.gif':
raise ValueError('Wrong save_name! If the picuter is .gif format, the output filename should be .gif format, too!')
if not isinstance(colorized, bool):
raise ValueError('Wrong colorized! Input a bool-type value!')
if not isinstance(contrast, float):
raise ValueError('Wrong contrast! Input a float-type value!')
if not isinstance(brightness, float):
raise ValueError('Wrong brightness! Input a float-type value!')
# 导出文件格式只支持jpg, png, bmp, gif
if save_name and (not isinstance(save_name, str) or save_name[-4:] not in ('.jpg','.png','.bmp','.gif')):
raise ValueError("Wrong save_name! Input a filename tailed with one of {'.jpg', '.png', '.bmp', '.gif'}!")
# 保存文件夹一定要存在(感觉不存在也可以创建一下啊)
if not os.path.isdir(save_dir):
raise ValueError('Wrong save_dir! Input a existing-directory!')
# 合并图片(背景和二维码)
def combine(ver, qr_name, bg_name, colorized, contrast, brightness, save_dir, save_name=None):
from MyQR.mylibs.constant import alig_location
from PIL import ImageEnhance, ImageFilter
qr = Image.open(qr_name) # 二维码
qr = qr.convert('RGBA') if colorized else qr # 二维码是否着色
bg0 = Image.open(bg_name).convert('RGBA') # 背景图片(4x8位像素,带透明度掩模的真彩色)
bg0 = ImageEnhance.Contrast(bg0).enhance(contrast) # 调节对比度
bg0 = ImageEnhance.Brightness(bg0).enhance(brightness) # 调节亮度
# 调整背景图片大小
if bg0.size[0] < bg0.size[1]:
bg0 = bg0.resize((qr.size[0]-24, (qr.size[0]-24)*int(bg0.size[1]/bg0.size[0])))
else:
bg0 = bg0.resize(((qr.size[1]-24)*int(bg0.size[0]/bg0.size[1]), qr.size[1]-24))
# convert('1')(1位像素,黑白,每字节一个像素存储)
bg = bg0 if colorized else bg0.convert('1')
# 校准模式
aligs = []
if ver > 1:
aloc = alig_location[ver-2]
for a in range(len(aloc)):
for b in range(len(aloc)):
if not ((a==b==0) or (a==len(aloc)-1 and b==0) or (a==0 and b==len(aloc)-1)):
for i in range(3*(aloc[a]-2), 3*(aloc[a]+3)):
for j in range(3*(aloc[b]-2), 3*(aloc[b]+3)):
aligs.append((i,j))
# 将新加的图片覆盖原有的二维码图片,生成新的图片并保存。
for i in range(qr.size[0]-24):
for j in range(qr.size[1]-24):
if not ((i in (18,19,20)) or (j in (18,19,20)) or (i<24 and j<24) or (i<24 and j>qr.size[1]-49) or (i>qr.size[0]-49 and j<24) or ((i,j) in aligs) or (i%3==1 and j%3==1) or (bg0.getpixel((i,j))[3]==0)):
qr.putpixel((i+12,j+12), bg.getpixel((i,j)))
qr_name = os.path.join(save_dir, os.path.splitext(os.path.basename(bg_name))[0] + '_qrcode.png') if not save_name else os.path.join(save_dir, save_name)
qr.resize((qr.size[0]*3, qr.size[1]*3)).save(qr_name)
return qr_name
# 临时文件夹暂存图片
tempdir = os.path.join(os.path.expanduser('~'), '.myqr')
try:
# 创建临时文件夹
if not os.path.exists(tempdir):
os.makedirs(tempdir)
# 得到一个qrcode图片(每个模块3*3 pixels)
ver, qr_name = theqrmodule.get_qrcode(version, level, words, tempdir)
if picture and picture[-4:]=='.gif':
import imageio
im = Image.open(picture)
duration = im.info.get('duration', 0) # 获得gif持续时间
# 获得gif的所有帧0.png 1.png 2.png...
im.save(os.path.join(tempdir, '0.png'))
while True:
try:
seq = im.tell()
im.seek(seq + 1)
im.save(os.path.join(tempdir, '%s.png' %(seq+1)))
except EOFError:
break
# 组合每帧图片和二维码
imsname = []
for s in range(seq + 1):
bg_name = os.path.join(tempdir, '%s.png' % s)
imsname.append(combine(ver, qr_name, bg_name, colorized, contrast, brightness, tempdir))
# 把合成的帧组合成gif
ims = [imageio.imread(pic) for pic in imsname]
qr_name = os.path.join(save_dir, os.path.splitext(os.path.basename(picture))[0] + '_qrcode.gif') if not save_name else os.path.join(save_dir, save_name)
imageio.mimwrite(qr_name, ims, '.gif', **{ 'duration': duration/1000 })
elif picture: # 有背景图片就需要合并背景和二维码
qr_name = combine(ver, qr_name, picture, colorized, contrast, brightness, save_dir, save_name)
elif qr_name:
qr = Image.open(qr_name)
# 没有输入保存名字就使用默认名字qr_name变量(qrcode)
qr_name = os.path.join(save_dir, os.path.basename(qr_name)) if not save_name else os.path.join(save_dir, save_name)
qr.resize((qr.size[0]*3, qr.size[1]*3)).save(qr_name)
# 返回QR码版本 纠错能力 导出文件名字
return ver, level, qr_name
except:
raise
finally:
# 销毁临时文件夹
import shutil
if os.path.exists(tempdir):
shutil.rmtree(tempdir)
其中最重要的就是theqrmodule.get_qrcode得到原始二维码。
其他内容主要就是把背景图片加入二维码里面(qr.putpixel((i+12,j+12), bg.getpixel((i,j))))
theqrmodule.py
# -*- coding: utf-8 -*-
from MyQR.mylibs import data, ECC, structure, matrix, draw
# ver: Version from 1 to 40
# ecl: Error Correction Level (L,M,Q,H)
# get a qrcode picture of 3*3 pixels per module
def get_qrcode(ver, ecl, str, save_place):
# Data Coding
# 将数据字符转换为位流,每8位一个码字,整体构成一个数据的码字序列。
ver, data_codewords = data.encode(ver, ecl, str)
# Error Correction Coding
# 按需要将上面的码字序列分块,并根据纠错等级和分块的码字,产生纠错码字,并把纠错码字加入到数据码字序列后面,成为一个新的序列。
ecc = ECC.encode(ver, ecl, data_codewords)
# Structure final bits
# 构造最终数据信息
final_bits = structure.structure_final_bits(ver, ecl, data_codewords, ecc)
# Get the QR Matrix
# 得到二维码的矩阵
qrmatrix = matrix.get_qrmatrix(ver, ecl, final_bits)
# Draw the picture and Save it, then return the real ver and the absolute name
# 生成二维码
return ver, draw.draw_qrcode(save_place, qrmatrix)
这是一个二维码生成的逻辑
constant.py
# -*- coding: utf-8 -*-
"""
***** for data.py *******
"""
# character capacities
# {level1: [version1(mode1,mode2,mode3,mode4), version2(..,..,..,..), ...],
# level2: [version1(mode1,mode2,mode3,mode4), version2(..,..,..,..),...],
# ...}
# mode1:纯数字(每三个为一组压缩成10bit)
# mode2:字母数字混合字符(每两个为一组,压缩成11bit)
# mode3:8bit字节数据(无压缩直接保存)
# mode4:多字节字符(每一个字符被压缩成13bit)
char_cap = {
'L': [(41, 25, 17, 10), (77, 47, 32, 20), (127, 77, 53, 32), (187, 114, 78, 48), (255, 154, 106, 65), (322, 195, 134, 82), (370, 224, 154, 95), (461, 279, 192, 118), (552, 335, 230, 141), (652, 395, 271, 167), (772, 468, 321, 198), (883, 535, 367, 226), (1022, 619, 425, 262), (1101, 667, 458, 282), (1250, 758, 520, 320), (1408, 854, 586, 361), (1548, 938, 644, 397), (1725, 1046, 718, 442), (1903, 1153, 792, 488), (2061, 1249, 858, 528), (2232, 1352, 929, 572), (2409, 1460, 1003, 618), (2620, 1588, 1091, 672), (2812, 1704, 1171, 721), (3057, 1853, 1273, 784), (3283, 1990, 1367, 842), (3517, 2132, 1465, 902), (3669, 2223, 1528, 940), (3909, 2369, 1628, 1002), (4158, 2520, 1732, 1066), (4417, 2677, 1840, 1132), (4686, 2840, 1952, 1201), (4965, 3009, 2068, 1273), (5253, 3183, 2188, 1347), (5529, 3351, 2303, 1417), (5836, 3537, 2431, 1496), (6153, 3729, 2563, 1577), (6479, 3927, 2699, 1661), (6743, 4087, 2809, 1729), (7089, 4296, 2953, 1817)],
'M': [(34, 20, 14, 8), (63, 38, 26, 16), (101, 61, 42, 26), (149, 90, 62, 38), (202, 122, 84, 52), (255, 154, 106, 65), (293, 178, 122, 75), (365, 221, 152, 93), (432, 262, 180, 111), (513, 311, 213, 131), (604, 366, 251, 155), (691, 419, 287, 177), (796, 483, 331, 204), (871, 528, 362, 223), (991, 600, 412, 254), (1082, 656, 450, 277), (1212, 734, 504, 310), (1346, 816, 560, 345), (1500, 909, 624, 384), (1600, 970, 666, 410), (1708, 1035, 711, 438), (1872, 1134, 779, 480), (2059, 1248, 857, 528), (2188, 1326, 911, 561), (2395, 1451, 997, 614), (2544, 1542, 1059, 652), (2701, 1637, 1125, 692), (2857, 1732, 1190, 732), (3035, 1839, 1264, 778), (3289, 1994, 1370, 843), (3486, 2113, 1452, 894), (3693, 2238, 1538, 947), (3909, 2369, 1628, 1002), (4134, 2506, 1722, 1060), (4343, 2632, 1809, 1113), (4588, 2780, 1911, 1176), (4775, 2894, 1989, 1224), (5039, 3054, 2099, 1292), (5313, 3220, 2213, 1362), (5596, 3391, 2331, 1435)],
'Q': [(27, 16, 11, 7), (48, 29, 20, 12), (77, 47, 32, 20), (111, 67, 46, 28), (144, 87, 60, 37), (178, 108, 74, 45), (207, 125, 86, 53), (259, 157, 108, 66), (312, 189, 130, 80), (364, 221, 151, 93), (427, 259, 177, 109), (489, 296, 203, 125), (580, 352, 241, 149), (621, 376, 258, 159), (703, 426, 292, 180), (775, 470, 322, 198), (876, 531, 364, 224), (948, 574, 394, 243), (1063, 644, 442, 272), (1159, 702, 482, 297), (1224, 742, 509, 314), (1358, 823, 565, 348), (1468, 890, 611, 376), (1588, 963, 661, 407), (1718, 1041, 715, 440), (1804, 1094, 751, 462), (1933, 1172, 805, 496), (2085, 1263, 868, 534), (2181, 1322, 908, 559), (2358, 1429, 982, 604), (2473, 1499, 1030, 634), (2670, 1618, 1112, 684), (2805, 1700, 1168, 719), (2949, 1787, 1228, 756), (3081, 1867, 1283, 790), (3244, 1966, 1351, 832), (3417, 2071, 1423, 876), (3599, 2181, 1499, 923), (3791, 2298, 1579, 972), (3993, 2420, 1663, 1024)],
'H': [(17, 10, 7, 4), (34, 20, 14, 8), (58, 35, 24, 15), (82, 50, 34, 21), (106, 64, 44, 27), (139, 84, 58, 36), (154, 93, 64, 39), (202, 122, 84, 52), (235, 143, 98, 60), (288, 174, 119, 74), (331, 200, 137, 85), (374, 227, 155, 96), (427, 259, 177, 109), (468, 283, 194, 120), (530, 321, 220, 136), (602, 365, 250, 154), (674, 408, 280, 173), (746, 452, 310, 191), (813, 493, 338, 208), (919, 557, 382, 235), (969, 587, 403, 248), (1056, 640, 439, 270), (1108, 672, 461, 284), (1228, 744, 511, 315), (1286, 779, 535, 330), (1425, 864, 593, 365), (1501, 910, 625, 385), (1581, 958, 658, 405), (1677, 1016, 698, 430), (1782, 1080, 742, 457), (1897, 1150, 790, 486), (2022, 1226, 842, 518), (2157, 1307, 898, 553), (2301, 1394, 958, 590), (2361, 1431, 983, 605), (2524, 1530, 1051, 647), (2625, 1591, 1093, 673), (2735, 1658, 1139, 701), (2927, 1774, 1219, 750), (3057, 1852, 1273, 784)]
}
# numeric:数字 alphanumeric:字母数字 byte:字节 kanji:汉字
mindex = {'numeric':0, 'alphanumeric':1, 'byte':2, 'kanji':3}
# [
# version1[level1,level2,level3,level4],
# version2[..,..,..,..],
# ...
# ]
# 数据码字计数(count of data code words)
required_bytes = [
[19, 16, 13, 9], [34, 28, 22, 16], [55, 44, 34, 26], [80, 64, 48, 36], [108, 86, 62, 46], [136, 108, 76, 60], [156, 124, 88, 66], [194, 154, 110, 86], [232, 182, 132, 100], [274, 216, 154, 122], [324, 254, 180, 140], [370, 290, 206, 158], [428, 334, 244, 180], [461, 365, 261, 197], [523, 415, 295, 223], [589, 453, 325, 253], [647, 507, 367, 283], [721, 563, 397, 313], [795, 627, 445, 341], [861, 669, 485, 385], [932, 714, 512, 406], [1006, 782, 568, 442], [1094, 860, 614, 464], [1174, 914, 664, 514], [1276, 1000, 718, 538], [1370, 1062, 754, 596], [1468, 1128, 808, 628], [1531, 1193, 871, 661], [1631, 1267, 911, 701], [1735, 1373, 985, 745], [1843, 1455, 1033, 793], [1955, 1541, 1115, 845], [2071, 1631, 1171, 901], [2191, 1725, 1231, 961], [2306, 1812, 1286, 986], [2434, 1914, 1354, 1054], [2566, 1992, 1426, 1096], [2702, 2102, 1502, 1142], [2812, 2216, 1582, 1222], [2956, 2334, 1666, 1276]
]
# 支持的数字
num_list = '0123456789'
# 支持的字母字符
alphanum_list = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ $%*+-./:'
# [
# version1[
# level1(num_of_group_1_blocks, DC_per_group_1_block, num_of_group_2_blocks, DC_per_group_2_block),
# level2(..,..,..,..),
# level3(..,..,..,..),
# level4(..,..,..,..)
# ],
# version2[level1(..), level2(..), level3(..), level4(..)],
# ...
# ]
# 码元分组
grouping_list = [
[(1, 19, 0, 0), (1, 16, 0, 0), (1, 13, 0, 0), (1, 9, 0, 0)], [(1, 34, 0, 0), (1, 28, 0, 0), (1, 22, 0, 0), (1, 16, 0, 0)], [(1, 55, 0, 0), (1, 44, 0, 0), (2, 17, 0, 0), (2, 13, 0, 0)], [(1, 80, 0, 0), (2, 32, 0, 0), (2, 24, 0, 0), (4, 9, 0, 0)], [(1, 108, 0, 0), (2, 43, 0, 0), (2, 15, 2, 16), (2, 11, 2, 12)], [(2, 68, 0, 0), (4, 27, 0, 0), (4, 19, 0, 0), (4, 15, 0, 0)], [(2, 78, 0, 0), (4, 31, 0, 0), (2, 14, 4, 15), (4, 13, 1, 14)], [(2, 97, 0, 0), (2, 38, 2, 39), (4, 18, 2, 19), (4, 14, 2, 15)], [(2, 116, 0, 0), (3, 36, 2, 37), (4, 16, 4, 17), (4, 12, 4, 13)], [(2, 68, 2, 69), (4, 43, 1, 44), (6, 19, 2, 20), (6, 15, 2, 16)], [(4, 81, 0, 0), (1, 50, 4, 51), (4, 22, 4, 23), (3, 12, 8, 13)], [(2, 92, 2, 93), (6, 36, 2, 37), (4, 20, 6, 21), (7, 14, 4, 15)], [(4, 107, 0, 0), (8, 37, 1, 38), (8, 20, 4, 21), (12, 11, 4, 12)], [(3, 115, 1, 116), (4, 40, 5, 41), (11, 16, 5, 17), (11, 12, 5, 13)], [(5, 87, 1, 88), (5, 41, 5, 42), (5, 24, 7, 25), (11, 12, 7, 13)], [(5, 98, 1, 99), (7, 45, 3, 46), (15, 19, 2, 20), (3, 15, 13, 16)], [(1, 107, 5, 108), (10, 46, 1, 47), (1, 22, 15, 23), (2, 14, 17, 15)], [(5, 120, 1, 121), (9, 43, 4, 44), (17, 22, 1, 23), (2, 14, 19, 15)], [(3, 113, 4, 114), (3, 44, 11, 45), (17, 21, 4, 22), (9, 13, 16, 14)], [(3, 107, 5, 108), (3, 41, 13, 42), (15, 24, 5, 25), (15, 15, 10, 16)], [(4, 116, 4, 117), (17, 42, 0, 0), (17, 22, 6, 23), (19, 16, 6, 17)], [(2, 111, 7, 112), (17, 46, 0, 0), (7, 24, 16, 25), (34, 13, 0, 0)], [(4, 121, 5, 122), (4, 47, 14, 48), (11, 24, 14, 25), (16, 15, 14, 16)], [(6, 117, 4, 118), (6, 45, 14, 46), (11, 24, 16, 25), (30, 16, 2, 17)], [(8, 106, 4, 107), (8, 47, 13, 48), (7, 24, 22, 25), (22, 15, 13, 16)], [(10, 114, 2, 115), (19, 46, 4, 47), (28, 22, 6, 23), (33, 16, 4, 17)], [(8, 122, 4, 123), (22, 45, 3, 46), (8, 23, 26, 24), (12, 15, 28, 16)], [(3, 117, 10, 118), (3, 45, 23, 46), (4, 24, 31, 25), (11, 15, 31, 16)], [(7, 116, 7, 117), (21, 45, 7, 46), (1, 23, 37, 24), (19, 15, 26, 16)], [(5, 115, 10, 116), (19, 47, 10, 48), (15, 24, 25, 25), (23, 15, 25, 16)], [(13, 115, 3, 116), (2, 46, 29, 47), (42, 24, 1, 25), (23, 15, 28, 16)], [(17, 115, 0, 0), (10, 46, 23, 47), (10, 24, 35, 25), (19, 15, 35, 16)], [(17, 115, 1, 116), (14, 46, 21, 47), (29, 24, 19, 25), (11, 15, 46, 16)], [(13, 115, 6, 116), (14, 46, 23, 47), (44, 24, 7, 25), (59, 16, 1, 17)], [(12, 121, 7, 122), (12, 47, 26, 48), (39, 24, 14, 25), (22, 15, 41, 16)], [(6, 121, 14, 122), (6, 47, 34, 48), (46, 24, 10, 25), (2, 15, 64, 16)], [(17, 122, 4, 123), (29, 46, 14, 47), (49, 24, 10, 25), (24, 15, 46, 16)], [(4, 122, 18, 123), (13, 46, 32, 47), (48, 24, 14, 25), (42, 15, 32, 16)], [(20, 117, 4, 118), (40, 47, 7, 48), (43, 24, 22, 25), (10, 15, 67, 16)], [(19, 118, 6, 119), (18, 47, 31, 48), (34, 24, 34, 25), (20, 15, 61, 16)]
]
# 模式标识符:对于不同的模式,都有对应的模式标识符来帮助解码程序进行匹配
mode_indicator = {'numeric': '0001', 'alphanumeric': '0010', 'byte': '0100', 'kanji': '1000'}
"""
****** for ECC.py *******
"""
#GP: Generator Polynomial, MP: Message Polynomial
# GP:生成多项式 MP:消息多项式
GP_list = {
7: [0, 87, 229, 146, 149, 238, 102, 21],
10: [0, 251, 67, 46, 61, 118, 70, 64, 94, 32, 45],
13: [0, 74, 152, 176, 100, 86, 100, 106, 104, 130, 218, 206, 140, 78],
15: [0, 8, 183, 61, 91, 202, 37, 51, 58, 58, 237, 140, 124, 5, 99, 105],
16: [0, 120, 104, 107, 109, 102, 161, 76, 3, 91, 191, 147, 169, 182, 194, 225, 120],
17: [0, 43, 139, 206, 78, 43, 239, 123, 206, 214, 147, 24, 99, 150, 39, 243, 163, 136],
18: [0, 215, 234, 158, 94, 184, 97, 118, 170, 79, 187, 152, 148, 252, 179, 5, 98, 96, 153],
20: [0, 17, 60, 79, 50, 61, 163, 26, 187, 202, 180, 221, 225, 83, 239, 156, 164, 212, 212, 188, 190],
22: [0, 210, 171, 247, 242, 93, 230, 14, 109, 221, 53, 200, 74, 8, 172, 98, 80, 219, 134, 160, 105, 165, 231],
24: [0, 229, 121, 135, 48, 211, 117, 251, 126, 159, 180, 169, 152, 192, 226, 228, 218, 111, 0, 117, 232, 87, 96, 227, 21],
26: [0, 173, 125, 158, 2, 103, 182, 118, 17, 145, 201, 111, 28, 165, 53, 161, 21, 245, 142, 13, 102, 48, 227, 153, 145, 218, 70],
28: [0, 168, 223, 200, 104, 224, 234, 108, 180, 110, 190, 195, 147, 205, 27, 232, 201, 21, 43, 245, 87, 42, 195, 212, 119, 242, 37, 9, 123],
30: [0, 41, 173, 145, 152, 216, 31, 179, 182, 50, 48, 110, 86, 239, 96, 222, 125, 42, 173, 226, 193, 224, 130, 156, 37, 251, 216, 238, 40, 192, 180]
}
# Error Correction Codewords per block
# [version1(level1,level2,level3,level4),
# version2(..,..,..,..),
# ....]
# 每个块的错误纠正码字
ecc_num_per_block = [
(7, 10, 13, 17), (10, 16, 22, 28), (15, 26, 18, 22), (20, 18, 26, 16), (26, 24, 18, 22), (18, 16, 24, 28), (20, 18, 18, 26), (24, 22, 22, 26), (30, 22, 20, 24), (18, 26, 24, 28), (20, 30, 28, 24), (24, 22, 26, 28), (26, 22, 24, 22), (30, 24, 20, 24), (22, 24, 30, 24), (24, 28, 24, 30), (28, 28, 28, 28), (30, 26, 28, 28), (28, 26, 26, 26), (28, 26, 30, 28), (28, 26, 28, 30), (28, 28, 30, 24), (30, 28, 30, 30), (30, 28, 30, 30), (26, 28, 30, 30), (28, 28, 28, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30)
]
# powers of 2 list
po2 = [
1, 2, 4, 8, 16, 32, 64, 128, 29, 58, 116, 232, 205, 135, 19, 38, 76, 152, 45, 90, 180, 117, 234, 201, 143, 3, 6, 12, 24, 48, 96, 192, 157, 39, 78, 156, 37, 74, 148, 53, 106, 212, 181, 119, 238, 193, 159, 35, 70, 140, 5, 10, 20, 40, 80, 160, 93, 186, 105, 210, 185, 111, 222, 161, 95, 190, 97, 194, 153, 47, 94, 188, 101, 202, 137, 15, 30, 60, 120, 240, 253, 231, 211, 187, 107, 214, 177, 127, 254, 225, 223, 163, 91, 182, 113, 226, 217, 175, 67, 134, 17, 34, 68, 136, 13, 26, 52, 104, 208, 189, 103, 206, 129, 31, 62, 124, 248, 237, 199, 147, 59, 118, 236, 197, 151, 51, 102, 204, 133, 23, 46, 92, 184, 109, 218, 169, 79, 158, 33, 66, 132, 21, 42, 84, 168, 77, 154, 41, 82, 164, 85, 170, 73, 146, 57, 114, 228, 213, 183, 115, 230, 209, 191, 99, 198, 145, 63, 126, 252, 229, 215, 179, 123, 246, 241, 255, 227, 219, 171, 75, 150, 49, 98, 196, 149, 55, 110, 220, 165, 87, 174, 65, 130, 25, 50, 100, 200, 141, 7, 14, 28, 56, 112, 224, 221, 167, 83, 166, 81, 162, 89, 178, 121, 242, 249, 239, 195, 155, 43, 86, 172, 69, 138, 9, 18, 36, 72, 144, 61, 122, 244, 245, 247, 243, 251, 235, 203, 139, 11, 22, 44, 88, 176, 125, 250, 233, 207, 131, 27, 54, 108, 216, 173, 71, 142, 1
]
# log list
log = [
None, 0, 1, 25, 2, 50, 26, 198, 3, 223, 51, 238, 27, 104, 199, 75, 4, 100, 224, 14, 52, 141, 239, 129, 28, 193, 105, 248, 200, 8, 76, 113, 5, 138, 101, 47, 225, 36, 15, 33, 53, 147, 142, 218, 240, 18, 130, 69, 29, 181, 194, 125, 106, 39, 249, 185, 201, 154, 9, 120, 77, 228, 114, 166, 6, 191, 139, 98, 102, 221, 48, 253, 226, 152, 37, 179, 16, 145, 34, 136, 54, 208, 148, 206, 143, 150, 219, 189, 241, 210, 19, 92, 131, 56, 70, 64, 30, 66, 182, 163, 195, 72, 126, 110, 107, 58, 40, 84, 250, 133, 186, 61, 202, 94, 155, 159, 10, 21, 121, 43, 78, 212, 229, 172, 115, 243, 167, 87, 7, 112, 192, 247, 140, 128, 99, 13, 103, 74, 222, 237, 49, 197, 254, 24, 227, 165, 153, 119, 38, 184, 180, 124, 17, 68, 146, 217, 35, 32, 137, 46, 55, 63, 209, 91, 149, 188, 207, 205, 144, 135, 151, 178, 220, 252, 190, 97, 242, 86, 211, 171, 20, 42, 93, 158, 132, 60, 57, 83, 71, 109, 65, 162, 31, 45, 67, 216, 183, 123, 164, 118, 196, 23, 73, 236, 127, 12, 111, 246, 108, 161, 59, 82, 41, 157, 85, 170, 251, 96, 134, 177, 187, 204, 62, 90, 203, 89, 95, 176, 156, 169, 160, 81, 11, 245, 22, 235, 122, 117, 44, 215, 79, 174, 213, 233, 230, 231, 173, 232, 116, 214, 244, 234, 168, 80, 88, 175
]
"""
****** for data.py + ECC.py + structure.py + matrix.py *******
"""
# 模式标识符对应的简写
lindex = {'L':0, 'M':1, 'Q':2, 'H':3}
"""
****** for structure.py *******
"""
# 剩余部分需要的位数
required_remainder_bits = (0,7,7,7,7,7,0,0,0,0,0,0,0,3,3,3,3,3,3,3,4,4,4,4,4,4,4,3,3,3,3,3,3,3,0,0,0,0,0,0)
# [
# version1[
# level1(num_of_group_1_blocks, DC_per_group_1_block, num_of_group_2_blocks, DC_per_group_2_block),
# level2(..,..,..,..),
# level3(..,..,..,..),
# level4(..,..,..,..)
# ],
# version2[level1(..), level2(..), level3(..), level4(..)],
# ...
# ]
# 码元分组
grouping_list = [
[(1, 19, 0, 0), (1, 16, 0, 0), (1, 13, 0, 0), (1, 9, 0, 0)], [(1, 34, 0, 0), (1, 28, 0, 0), (1, 22, 0, 0), (1, 16, 0, 0)], [(1, 55, 0, 0), (1, 44, 0, 0), (2, 17, 0, 0), (2, 13, 0, 0)], [(1, 80, 0, 0), (2, 32, 0, 0), (2, 24, 0, 0), (4, 9, 0, 0)], [(1, 108, 0, 0), (2, 43, 0, 0), (2, 15, 2, 16), (2, 11, 2, 12)], [(2, 68, 0, 0), (4, 27, 0, 0), (4, 19, 0, 0), (4, 15, 0, 0)], [(2, 78, 0, 0), (4, 31, 0, 0), (2, 14, 4, 15), (4, 13, 1, 14)], [(2, 97, 0, 0), (2, 38, 2, 39), (4, 18, 2, 19), (4, 14, 2, 15)], [(2, 116, 0, 0), (3, 36, 2, 37), (4, 16, 4, 17), (4, 12, 4, 13)], [(2, 68, 2, 69), (4, 43, 1, 44), (6, 19, 2, 20), (6, 15, 2, 16)], [(4, 81, 0, 0), (1, 50, 4, 51), (4, 22, 4, 23), (3, 12, 8, 13)], [(2, 92, 2, 93), (6, 36, 2, 37), (4, 20, 6, 21), (7, 14, 4, 15)], [(4, 107, 0, 0), (8, 37, 1, 38), (8, 20, 4, 21), (12, 11, 4, 12)], [(3, 115, 1, 116), (4, 40, 5, 41), (11, 16, 5, 17), (11, 12, 5, 13)], [(5, 87, 1, 88), (5, 41, 5, 42), (5, 24, 7, 25), (11, 12, 7, 13)], [(5, 98, 1, 99), (7, 45, 3, 46), (15, 19, 2, 20), (3, 15, 13, 16)], [(1, 107, 5, 108), (10, 46, 1, 47), (1, 22, 15, 23), (2, 14, 17, 15)], [(5, 120, 1, 121), (9, 43, 4, 44), (17, 22, 1, 23), (2, 14, 19, 15)], [(3, 113, 4, 114), (3, 44, 11, 45), (17, 21, 4, 22), (9, 13, 16, 14)], [(3, 107, 5, 108), (3, 41, 13, 42), (15, 24, 5, 25), (15, 15, 10, 16)], [(4, 116, 4, 117), (17, 42, 0, 0), (17, 22, 6, 23), (19, 16, 6, 17)], [(2, 111, 7, 112), (17, 46, 0, 0), (7, 24, 16, 25), (34, 13, 0, 0)], [(4, 121, 5, 122), (4, 47, 14, 48), (11, 24, 14, 25), (16, 15, 14, 16)], [(6, 117, 4, 118), (6, 45, 14, 46), (11, 24, 16, 25), (30, 16, 2, 17)], [(8, 106, 4, 107), (8, 47, 13, 48), (7, 24, 22, 25), (22, 15, 13, 16)], [(10, 114, 2, 115), (19, 46, 4, 47), (28, 22, 6, 23), (33, 16, 4, 17)], [(8, 122, 4, 123), (22, 45, 3, 46), (8, 23, 26, 24), (12, 15, 28, 16)], [(3, 117, 10, 118), (3, 45, 23, 46), (4, 24, 31, 25), (11, 15, 31, 16)], [(7, 116, 7, 117), (21, 45, 7, 46), (1, 23, 37, 24), (19, 15, 26, 16)], [(5, 115, 10, 116), (19, 47, 10, 48), (15, 24, 25, 25), (23, 15, 25, 16)], [(13, 115, 3, 116), (2, 46, 29, 47), (42, 24, 1, 25), (23, 15, 28, 16)], [(17, 115, 0, 0), (10, 46, 23, 47), (10, 24, 35, 25), (19, 15, 35, 16)], [(17, 115, 1, 116), (14, 46, 21, 47), (29, 24, 19, 25), (11, 15, 46, 16)], [(13, 115, 6, 116), (14, 46, 23, 47), (44, 24, 7, 25), (59, 16, 1, 17)], [(12, 121, 7, 122), (12, 47, 26, 48), (39, 24, 14, 25), (22, 15, 41, 16)], [(6, 121, 14, 122), (6, 47, 34, 48), (46, 24, 10, 25), (2, 15, 64, 16)], [(17, 122, 4, 123), (29, 46, 14, 47), (49, 24, 10, 25), (24, 15, 46, 16)], [(4, 122, 18, 123), (13, 46, 32, 47), (48, 24, 14, 25), (42, 15, 32, 16)], [(20, 117, 4, 118), (40, 47, 7, 48), (43, 24, 22, 25), (10, 15, 67, 16)], [(19, 118, 6, 119), (18, 47, 31, 48), (34, 24, 34, 25), (20, 15, 61, 16)]
]
"""
****** for matrix.py *******
"""
# Alignment Pattern Locations
# 对齐模式位置
alig_location = [
(6, 18), (6, 22), (6, 26), (6, 30), (6, 34), (6, 22, 38), (6, 24, 42), (6, 26, 46), (6, 28, 50), (6, 30, 54), (6, 32, 58), (6, 34, 62), (6, 26, 46, 66), (6, 26, 48, 70), (6, 26, 50, 74), (6, 30, 54, 78), (6, 30, 56, 82), (6, 30, 58, 86), (6, 34, 62, 90), (6, 28, 50, 72, 94), (6, 26, 50, 74, 98), (6, 30, 54, 78, 102), (6, 28, 54, 80, 106), (6, 32, 58, 84, 110), (6, 30, 58, 86, 114), (6, 34, 62, 90, 118), (6, 26, 50, 74, 98, 122), (6, 30, 54, 78, 102, 126), (6, 26, 52, 78, 104, 130), (6, 30, 56, 82, 108, 134), (6, 34, 60, 86, 112, 138), (6, 30, 58, 86, 114, 142), (6, 34, 62, 90, 118, 146), (6, 30, 54, 78, 102, 126, 150), (6, 24, 50, 76, 102, 128, 154), (6, 28, 54, 80, 106, 132, 158), (6, 32, 58, 84, 110, 136, 162), (6, 26, 54, 82, 110, 138, 166), (6, 30, 58, 86, 114, 142, 170)
]
# List of all Format Information Strings
# [
# level1[mask_pattern0, mask_pattern1, mask_...3,...],
# level2[...],
# level3[...],
# level4[...]
# ]
# 所有格式信息字符串的列表
format_info_str = [
['111011111000100', '111001011110011', '111110110101010', '111100010011101', '110011000101111', '110001100011000', '110110001000001', '110100101110110'], ['101010000010010', '101000100100101', '101111001111100', '101101101001011', '100010111111001', '100000011001110', '100111110010111', '100101010100000'], ['011010101011111', '011000001101000', '011111100110001', '011101000000110', '010010010110100', '010000110000011', '010111011011010', '010101111101101'], ['001011010001001', '001001110111110', '001110011100111', '001100111010000', '000011101100010', '000001001010101', '000110100001100', '000100000111011']
]
# Version Information Strings
# 版本信息字符串
version_info_str = [
'000111110010010100', '001000010110111100', '001001101010011001', '001010010011010011', '001011101111110110', '001100011101100010', '001101100001000111', '001110011000001101', '001111100100101000', '010000101101111000', '010001010001011101', '010010101000010111', '010011010100110010', '010100100110100110', '010101011010000011', '010110100011001001', '010111011111101100', '011000111011000100', '011001000111100001', '011010111110101011', '011011000010001110', '011100110000011010', '011101001100111111', '011110110101110101', '011111001001010000', '100000100111010101', '100001011011110000', '100010100010111010', '100011011110011111', '100100101100001011', '100101010000101110', '100110101001100100', '100111010101000001', '101000110001101001'
]
用到的一些常量
data.py
# -*- coding: utf-8 -*-
from MyQR.mylibs.constant import char_cap, required_bytes, mindex, lindex, num_list, alphanum_list, grouping_list, mode_indicator
# ecl: Error Correction Level(L,M,Q,H)
def encode(ver, ecl, str):
# 模式编码
mode_encoding = {
'numeric': numeric_encoding,
'alphanumeric': alphanumeric_encoding,
'byte': byte_encoding,
'kanji': kanji_encoding
}
# 确定编码模式
ver, mode = analyse(ver, ecl, str)
print('line 16: mode:', mode)
# mode_indicator[mode]:模式标识符 'numeric': '0001', 'alphanumeric': '0010', 'byte': '0100', 'kanji': '1000'
# get_cci(ver, mode, str):计算字符数
# mode_encoding[mode](str):编码字符串(word)
code = mode_indicator[mode] + get_cci(ver, mode, str) + mode_encoding[mode](str)
# Add a Terminator
# 添加编码终止符
rqbits = 8 * required_bytes[ver-1][lindex[ecl]]
b = rqbits - len(code)
code += '0000' if b >= 4 else '0' * b
# 编成8bit码字
# Make the Length a Multiple of 8
# 长度不足补全
while len(code) % 8 != 0:
code += '0'
# Add Pad Bytes if the String is Still too Short
# 如果编码后的数据不足版本及纠错级别的最大容量,则在尾部补充 "11101100" 和 "00010001",直到全部填满。
while len(code) < rqbits:
code += '1110110000010001' if rqbits - len(code) >= 16 else '11101100'
# 分组编码
data_code = [code[i:i+8] for i in range(len(code)) if i%8 == 0]
data_code = [int(i,2) for i in data_code]
g = grouping_list[ver-1][lindex[ecl]]
data_codewords, i = [], 0
for n in range(g[0]):
data_codewords.append(data_code[i:i+g[1]])
i += g[1]
for n in range(g[2]):
data_codewords.append(data_code[i:i+g[3]])
i += g[3]
return ver, data_codewords
# 确定编码模式和版本
def analyse(ver, ecl, str):
if all(i in num_list for i in str):
mode = 'numeric'
elif all(i in alphanum_list for i in str):
mode = 'alphanumeric'
else:
mode = 'byte'
# 根据编码模式和纠错信息确定能容纳所有信息的最小版本
# 如果比输入的参数小则不修改
# 如果比输入的参数大则修改
m = mindex[mode]
l = len(str)
for i in range(40):
if char_cap[ecl][i][m] > l:
ver = i + 1 if i+1 > ver else ver
break
return ver, mode
# 数字编码
def numeric_encoding(str):
str_list = [str[i:i+3] for i in range(0,len(str),3)]
code = ''
for i in str_list:
rqbin_len = 10
if len(i) == 1:
rqbin_len = 4
elif len(i) == 2:
rqbin_len = 7
code_temp = bin(int(i))[2:]
code += ('0'*(rqbin_len - len(code_temp)) + code_temp)
return code
# 字母数字编码
def alphanumeric_encoding(str):
code_list = [alphanum_list.index(i) for i in str]
code = ''
for i in range(1, len(code_list), 2):
c = bin(code_list[i-1] * 45 + code_list[i])[2:]
c = '0'*(11-len(c)) + c
code += c
if i != len(code_list) - 1:
c = bin(code_list[-1])[2:]
c = '0'*(6-len(c)) + c
code += c
return code
# 字节编码
def byte_encoding(str):
code = ''
for i in str:
c = bin(ord(i.encode('iso-8859-1')))[2:]
c = '0'*(8-len(c)) + c
code += c
return code
# 中文字符编码不支持
def kanji_encoding(str):
pass
# cci: character count indicator
# 计算字符数
def get_cci(ver, mode, str):
if 1 <= ver <= 9:
cci_len = (10, 9, 8, 8)[mindex[mode]]
elif 10 <= ver <= 26:
cci_len = (12, 11, 16, 10)[mindex[mode]]
else:
cci_len = (14, 13, 16, 12)[mindex[mode]]
cci = bin(len(str))[2:]
cci = '0' * (cci_len - len(cci)) + cci
return cci
if __name__ == '__main__':
s = '123456789'
v, datacode = encode(1, 'H', s)
print(v, datacode)
按照字符内容确定版本和模式,然后编码字符串。
ECC.py
# -*- coding: utf-8 -*-
from MyQR.mylibs.constant import GP_list, ecc_num_per_block, lindex, po2, log
#ecc: Error Correction Codewords
# 得到纠错码字
def encode(ver, ecl, data_codewords):
en = ecc_num_per_block[ver-1][lindex[ecl]] # 错误纠正码字
ecc = []
for dc in data_codewords:
ecc.append(get_ecc(dc, en))
return ecc
def get_ecc(dc, ecc_num):
gp = GP_list[ecc_num] # 得到适当的项乘生成多项式
remainder = dc
for i in range(len(dc)):
remainder = divide(remainder, *gp) # 使用消息多项式(在第一个乘法步骤中)或余数(在所有后续乘法步骤中)对结果进行异或
return remainder
# 得到余数
def divide(MP, *GP):
if MP[0]:
GP = list(GP)
for i in range(len(GP)):
GP[i] += log[MP[0]]
if GP[i] > 255:
GP[i] %= 255
GP[i] = po2[GP[i]]
return XOR(GP, *MP)
else:
return XOR([0]*len(GP), *MP)
# 异或
def XOR(GP, *MP):
MP = list(MP)
a = len(MP) - len(GP)
if a < 0:
MP += [0] * (-a)
elif a > 0:
GP += [0] * a
remainder = []
for i in range(1, len(MP)):
remainder.append(MP[i]^GP[i])
return remainder
得到纠错码字步骤:
- 找到适当的项乘生成多项式,使得乘法的结果与消息多项式具有相同的第一项。
- 使用消息多项式(在第一个乘法步骤中)或余数(在所有后续乘法步骤中)对结果进行异或。
- 执行这些步骤n次,其中n是消息多项式中的系数。
structure.py
# -*- coding: utf-8 -*-
from MyQR.mylibs.constant import required_remainder_bits, lindex, grouping_list
def structure_final_bits(ver, ecl, data_codewords, ecc):
# 将产生的序列按次序放到分块中
final_message = interleave_dc(ver, ecl, data_codewords) + interleave_ecc(ecc)
# convert to binary & Add Remainder Bits if Necessary
# 转换为二进制 如果必要则添加余数位
final_bits = ''.join(['0'*(8-len(i))+i for i in [bin(i)[2:] for i in final_message]]) + '0' * required_remainder_bits[ver-1]
return final_bits
# 数据区块
def interleave_dc(ver, ecl, data_codewords):
id = []
for t in zip(*data_codewords):
id += list(t)
g = grouping_list[ver-1][lindex[ecl]]
if g[3]:
for i in range(g[2]):
id.append(data_codewords[i-g[2]][-1])
return id
# 纠错码字区块
def interleave_ecc(ecc):
ie = []
for t in zip(*ecc):
ie += list(t)
return ie
按规定把数据分块,然后对每一块进行计算,得出相应的纠错码字区块,把纠错码字区块 按顺序构成一个序列,添加到原先的数据码字序列后面。
matrix.py
# -*- coding: utf-8 -*-
from MyQR.mylibs.constant import alig_location, format_info_str, version_info_str, lindex
def get_qrmatrix(ver, ecl, bits):
num = (ver - 1) * 4 + 21
qrmatrix = [[None] * num for i in range(num)] # 构造矩阵
# [([None] * num * num)[i:i+num] for i in range(num * num) if i % num == 0]
# Add the Finder Patterns & Add the Separators
# 添加查找器模式和添加分隔符
add_finder_and_separator(qrmatrix)
# Add the Alignment Patterns
# 添加校准模式
add_alignment(ver, qrmatrix)
# Add the Timing Patterns
# 添加时间模式
add_timing(qrmatrix)
# Add the Dark Module and Reserved Areas
# 添加涂黑模块和保留区域
add_dark_and_reserving(ver, qrmatrix)
maskmatrix = [i[:] for i in qrmatrix]
# Place the Data Bits
# 放置数据位
place_bits(bits, qrmatrix)
# Data Masking
# 掩摸图形
mask_num, qrmatrix = mask(maskmatrix, qrmatrix)
# Format Information
# 格式信息
add_format_and_version_string(ver, ecl, mask_num, qrmatrix)
return qrmatrix
# 添加查找器模式和添加分隔符(左上角 右上角 左下角矩形和空白部分)
def add_finder_and_separator(m):
for i in range(8):
for j in range(8):
if i in (0, 6):
m[i][j] = m[-i-1][j] = m[i][-j-1] = 0 if j == 7 else 1
elif i in (1, 5):
m[i][j] = m[-i-1][j] = m[i][-j-1] = 1 if j in (0, 6) else 0
elif i == 7:
m[i][j] = m[-i-1][j] = m[i][-j-1] = 0
else:
m[i][j] = m[-i-1][j] = m[i][-j-1] = 0 if j in (1, 5, 7) else 1
# 添加校准模式(矩形校正图形)
def add_alignment(ver, m):
if ver > 1:
coordinates = alig_location[ver-2]
for i in coordinates:
for j in coordinates:
if m[i][j] is None:
add_an_alignment(i, j, m)
# 添加一个校正图形
def add_an_alignment(row, column, m):
for i in range(row-2, row+3):
for j in range(column-2, column+3):
m[i][j] = 1 if i in (row-2, row+2) or j in (column-2, column+2) else 0
m[row][column] = 1
# 添加时间模式
def add_timing(m):
for i in range(8, len(m)-8):
m[i][6] = m[6][i] = 1 if i % 2 ==0 else 0
# 添加涂黑模块和保留区域
def add_dark_and_reserving(ver, m):
for j in range(8):
m[8][j] = m[8][-j-1] = m[j][8] = m[-j-1][8] = 0
m[8][8] = 0
m[8][6] = m[6][8] = m[-8][8] = 1
if ver > 6:
for i in range(6):
for j in (-9, -10, -11):
m[i][j] = m[j][i] = 0
# 放置数据位
def place_bits(bits, m):
bit = (int(i) for i in bits)
up = True
for a in range(len(m)-1, 0, -2):
a = a-1 if a <= 6 else a
irange = range(len(m)-1, -1, -1) if up else range(len(m))
for i in irange:
for j in (a, a-1):
if m[i][j] is None:
m[i][j] = next(bit)
up = not up
# 将掩摸图形用于符号的编码区域,使得二维码图形中的深色和浅色(黑色和白色)区域能够比率最优的分布。
def mask(mm, m):
mps = get_mask_patterns(mm)
scores = []
for mp in mps:
for i in range(len(mp)):
for j in range(len(mp)):
mp[i][j] = mp[i][j] ^ m[i][j]
scores.append(compute_score(mp))
best = scores.index(min(scores))
return best, mps[best]
def get_mask_patterns(mm):
def formula(i, row, column):
if i == 0:
return (row + column) % 2 == 0
elif i == 1:
return row % 2 == 0
elif i == 2:
return column % 3 == 0
elif i == 3:
return (row + column) % 3 == 0
elif i == 4:
return (row // 2 + column // 3) % 2 == 0
elif i == 5:
return ((row * column) % 2) + ((row * column) % 3) == 0
elif i == 6:
return (((row * column) % 2) + ((row * column) % 3)) % 2 == 0
elif i == 7:
return (((row + column) % 2) + ((row * column) % 3)) % 2 == 0
mm[-8][8] = None
for i in range(len(mm)):
for j in range(len(mm)):
mm[i][j] = 0 if mm[i][j] is not None else mm[i][j]
mps = []
for i in range(8):
mp = [ii[:] for ii in mm]
for row in range(len(mp)):
for column in range(len(mp)):
mp[row][column] = 1 if mp[row][column] is None and formula(i, row, column) else 0
mps.append(mp)
return mps
def compute_score(m):
def evaluation1(m):
def ev1(ma):
sc = 0
for mi in ma:
j = 0
while j < len(mi)-4:
n = 4
while mi[j:j+n+1] in [[1]*(n+1), [0]*(n+1)]:
n += 1
(sc, j) = (sc+n-2, j+n) if n > 4 else (sc, j+1)
return sc
return ev1(m) + ev1(list(map(list, zip(*m))))
def evaluation2(m):
sc = 0
for i in range(len(m)-1):
for j in range(len(m)-1):
sc += 3 if m[i][j] == m[i+1][j] == m[i][j+1] == m[i+1][j+1] else 0
return sc
def evaluation3(m):
def ev3(ma):
sc = 0
for mi in ma:
j = 0
while j < len(mi)-10:
if mi[j:j+11] == [1,0,1,1,1,0,1,0,0,0,0]:
sc += 40
j += 7
elif mi[j:j+11] == [0,0,0,0,1,0,1,1,1,0,1]:
sc += 40
j += 4
else:
j += 1
return sc
return ev3(m) + ev3(list(map(list, zip(*m))))
def evaluation4(m):
darknum = 0
for i in m:
darknum += sum(i)
percent = darknum / (len(m)**2) * 100
s = int((50 - percent) / 5) * 5
return 2*s if s >=0 else -2*s
score = evaluation1(m) + evaluation2(m)+ evaluation3(m) + evaluation4(m)
return score
# 生成格式和版本信息放入相应区域内
def add_format_and_version_string(ver, ecl, mask_num, m):
fs = [int(i) for i in format_info_str[lindex[ecl]][mask_num]]
for j in range(6):
m[8][j] = m[-j-1][8] = fs[j]
m[8][-j-1] = m[j][8] = fs[-j-1]
m[8][7] = m[-7][8] = fs[6]
m[8][8] = m[8][-8] = fs[7]
m[7][8] = m[8][-7] = fs[8]
# 版本7-40都包含了版本信息,没有版本信息的全为0。
if ver > 6:
vs = (int(i) for i in version_info_str[ver-7])
for j in range(5, -1, -1):
for i in (-9, -10, -11):
m[i][j] = m[j][i] = next(vs)
构造矩阵:将探测图形、分隔符、定位图形、校正图形、格式和版本信息和码字模块放入矩阵中。
掩摸:将掩摸图形用于符号的编码区域,使得二维码图形中的深色和浅色(黑色和白色)区域能够比率最优的分布。
draw.py
# -*- coding: utf-8 -*-
from PIL import Image
import os
def draw_qrcode(abspath, qrmatrix):
unit_len = 3
x = y = 4*unit_len
pic = Image.new('1', [(len(qrmatrix)+8)*unit_len]*2, 'white') # 新建一张白色的底图
# 循环矩阵中的单位,在需要涂黑的单位启用dra_a_black_unit()函数涂黑。
for line in qrmatrix:
for module in line:
if module:
draw_a_black_unit(pic, x, y, unit_len)
x += unit_len
x, y = 4*unit_len, y+unit_len
saving = os.path.join(abspath, 'qrcode.png')
pic.save(saving) # 保存二维码图片
return saving
# 画出黑单位
def draw_a_black_unit(p, x, y, ul):
for i in range(ul):
for j in range(ul):
p.putpixel((x+i, y+j), 0)
根据构造出来的矩形画出二维码
参考文章
QR二维码编码原理
MyQR源码解读
二维码 编码原理简介