利用多层卷积神经网络(CNN)特征的互补优势 进行图像检索
利用多层卷积神经网络(CNN)特征的互补优势
进行图像检索
本文原网址为:http://www.sciencedirect.com/science/article/pii/S0925231216314734
翻译不当之处请多多指正
摘要:深度卷积神经网络已经证明了图像分类的突破精度。从CNN学到的一系列特征提取器已经用于其他计算机视觉任务。然而,CNN不同层次的特征旨在编码不同层次的信息。高层特征更关注语义信息,更少关注细节信息,而低层特征包含更多细节信息,但与背景混乱和语义歧义问题相关。我们建议以简单但有效的方式利用不同层次的互补优势。一个映射函数被设计来突出低层相似性的有效性,当在相似的语义下测量查询图像和它最近的邻居之间的细粒度的相似性时。大量的实验表明,我们的方法可以在流行的检索基准上获得有竞争力的表现。大量的实验表明,该方法优于单层提取的特征及其直接拼接。同时,我们的方法在流行的检索基准上达到了有竞争力的表现。
1.介绍
最近,深度卷积神经网络(CNN)在图像分类任务中取得了最先进的性能。随着CNN的重生,一系列从低级到高级的特征提取器可以从大规模的训练数据中以端到端的方式自动学习。一些作品表明,这些学习的特征提取器可以成功地转移到其他计算机视觉任务。作为一个热门的研究课题,基于内容的图像检索(CBIR)也可以利用CNN激活作为图像的通用表示。在本文中,我们试图根据不同层的CNN激活图的互补性来获得更好的检索性能。
CBIR总是依赖描述符表示图像的能力。强大的手工描述符可以捕捉对象的局部特征,如SIFT。大多数现有的方法对这些基于梯度的特征进行编码以克服语义上的差距,诸如词干(BoW),Fisher矢量(FV)或向量局部聚合描述符(VLAD)及其变体。但是,这些编码方法还远没有捕捉到高级语义信息。
当预先训练好的CNN应用于CBIR时,选择较高层的特征地图来呈现整个图像。在最近的研究结果中,下层的特征图可以在实例级图像检索中获得更好的结果。实际上,不同层次的特征地图从输入图像中提取不同层次的信息。图1说明了一些与CNN学习的一些滤波器的最高激活相对应的补丁。低层特征的维度倾向于以相似的简单模式响应补丁,并且具有更多的模糊性。较高层的特征图更关注语义信息,而较少关于图像的细节信息,因为较高层更接近具有分类标签的最后一层。下层的特征映射包含了更多的图像结构信息,但是背景杂乱和语义歧义的问题更为突出。尽管下层的特征映射与手工特征具有相似的语义差异,但下层的特征提取器可以捕获局部模式来描述实例级别的细节。

图1. CNN特征来自不同卷积层的采样维数最高的补丁。每行显示相应维度中具有最大激活的补丁。所有的补丁都是从oxford 5K数据集中采样的。
高层特征用于度量语义相似度,低层特征用于度量细粒度相似度。给出一个简单易懂的例子,当查询图像是一个建筑物时,高层相似性捕捉到的图像包含一个建筑物,而低层相似性则捕获同一个从属同类实体的建筑物。显然,低层和高层特征的互补性可以提高查询图像与其他候选图像之间的相似性度量。一些现有的方法试图利用多尺度无序汇集来进行CNN激活。例如,CNN特征分别从不同层次提取和编码,然后将这些不同层次的聚合特征进行连接以测量图像。但直接拼接不能充分利用高层和低层特征的互补性。高层特征可以搜索具有相似语义的候选图像的集合作为查询图像,但是它不足以描述细粒度的细节。因此,高层相似性会削弱低层相似性的有效性,当最近邻居之间的细粒度差别被区分时,语义相似。
在本文中,我们建议以一种简单而有效的方式利用不同层次的CNN特征的更多互补优势。我们的方法试图突出低层相似性的有效性,当查询图像和最近的邻居之间的细粒度的相似性与相似的语义。换句话说,低层特征用于细化高层特征的排序结果,而不是直接连接多个层。如图2所示,高层特征不足以描述细节信息,而低层特征则来自背景混乱和语义歧义。以直接拼接的方式,由于高层相似度的影响,低层相似度在区分细粒度差异方面不起重要作用。使用映射函数,我们的方法利用低层特征来测量查询图像与具有相同语义的最近邻居之间的细粒度相似性。在实验中,我们证明了我们的方法比单层功能,多层连接以及其他基于手工特征的方法更好。

图2.不同CNN特征搜索的排名结果。从上到下,各行显示了高层特征,低层特征,直接拼接和我们的方法的排序结果。从fc1层提取高层特征,从conv4层提取低层特征,直接拼接,我们的方法使用这两个层。绿色边框表示正面候选图像,而红色边框表示错误候选图像。查询图像和候选图像均从Oxford 5K数据集中采样。(对于这个图例中对颜色的引用的解释,读者可以参考这篇文章的web版本。)
2.相关工作
传统的CBIR方法依靠强大的手工功能和有效的编码方法。在过去的几十年里,基于Bag-of-Words(BoW)的方法[9,18]被认为是最先进的。基于SIFT [8]等强大的局部不变特征,BoW可以很好地表示图像的缩放,平移,旋转等变化。作为BoW的替代,矢量局部聚合描述符(VLAD)[11]被提出来捕获一个紧凑的图像表示,取得了很好的结果。后来,可以使用一些额外的技术来进一步提高VLAD的性能,如内部归一化[13],幂律归一化[14],单调平方根[19]等等。 Multi-VLAD [13]构建了多级VLAD描述符,并将其匹配以提高定位精度,其中利用RootSIFT提高检索任务的性能。Covariant-VLAD(CVLAD)[14]也使用RootSIFT,并应用幂律归一化来更新VLAD描述符的各个组件。
其他整体特征编码更多的全球空间信息,其中费舍尔矢量(FV)是这类最知名的描述符。FV也有很多变种。例如,由于FV的密度,采用了一些立式二进制编码技术,并引入了一个简单的规范化过程来提高检索的准确性。考虑到FV的维数降低,利用ImageNet来发现有辨识性的低维子空间,其中一个隐含单元层和一个分类器输出层被添加到FV之上。尽管隐藏层的低维激活被用作图像检索的描述符,但是表示仍然基于手工特征(SIFT和局部颜色直方图),而不是从CNN中的输入图像中学习的特征映射。
受到图像分类成功的启发,CNN的特征提取器也被应用于其他识别任务。 DeCAF [21]首先发布了这样的特征提取器以及所有相关的网络参数。由于低层不太可能包含丰富的语义信息,因此只评估来自最后卷积层和前两个完全连接层的特征提取器。一些像素标记任务试图通过连接来自不同层的特征提取器(例如对象分割[22,23]和边界检测[24])来利用语义信息来丰富像素表示。这些任务结合了高层和低层的特点,取得了很好的效果。
OverFeat [25]首先研究了CNN特征在图像检索任务中的应用,其中最后一层的特征没有超越基于SIFT的BoW和VLAD编码方法。神经编码[15]检查高层的神经元激活的图像检索,其中前两个完全连接层和最后一个池层分别用于评估。虽然再培训CNN的特征要素可以取得很好的表现,但是收集培训样本和再培训阶段需要大量的人力和计算资源。 MOP-CNN [17]从VLAD的不同层面提取聚合特征,其中一个完全连接层和两个合并层被预先选择。低层特征提取器可以在实例级图像检索上表现更好。这一观察结果得到了许多鼓舞人心的实验结果的进一步证实和扩展[16],其中分别从OxordNet [2]和GoogLeNet [3]提取的所有卷积层被评估。显然,不同层面的重点是从图像中提取不同的信息,低层和高层的互补性可以进一步改善图像检索任务。
3方法
为了描述图像,需要将卷积图层的激活图聚合成一个特征向量。本文中,完全连接层的特征是对应层的输出,卷积层的特征是聚合特征。特别的是,相似度是用余弦距离来度量的,因此单层相似度的范围是[0,1]。
3.1 使用多层特征的相似性
在现有的方法中,特征拼接S的相似性是作为不同层的总和而得到的: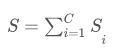
其中C层被选择来测量相似度,并且Si是两个图像之间的第i个选择层的相似度。
为了突出低层特征,我们设计了一个映射函数fi,我们的方法的相似性可以概括为:
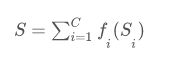
映射函数fi被设计为:
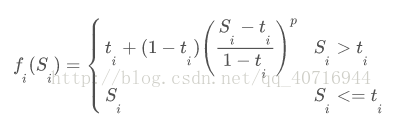
其中ti是第i个选定图层的相似度阈值,p的范围是(0,1)。
有了这个设计的功能,我们的目标是削弱范围[ti,1]之间的相似性之间的差异。考虑到两层相结合,区域[ti,1]的高层相似度的有效性将会减弱,低层相似度可以更好地区分细粒度的区分。在实际实验中,较高层使用较低的阈值,即t1≤...≤ti≤...≤tC,最低层的阈值tC设置为1。
3.2 分析映射函数
fi的图可以解释这个看似复杂的函数,如图3(a)所示。映射函数被设计用于减少大于阈值ti的相似度之间的差异。指数p控制弱化的程度。特别是,当p设置为0时,我们的方法将转化为使用低层相似度对高层次排名结果进行重新排序。当p被设置为1或者ti被设置为1时,直接使用第i层的相似性,并且将我们的方法直接转换为连接不同层。
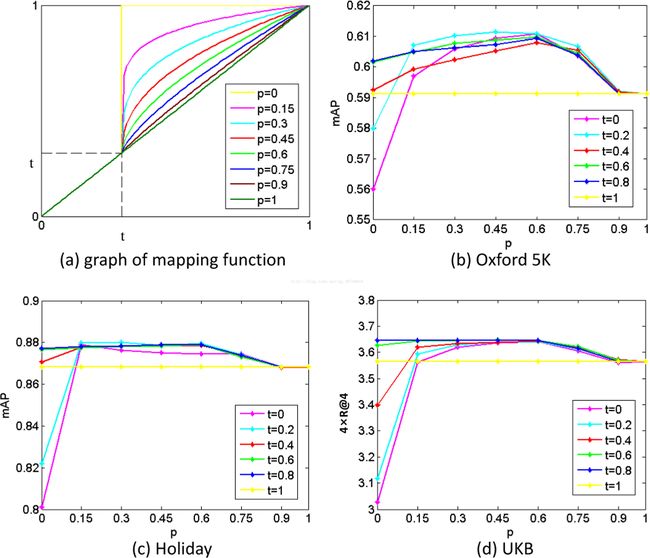
图3(a)示出了具有固定t和不同p的映射函数的图。(b)-(d)分别显示Oxford 5K,Holiday和UKB不同场合的表演。(更好地看颜色)。(对于本图中对颜色的引用的解释,读者可参考本文的网页版本。)
显然,方程(3)是挖掘不同层次互补优势的关键。为了避免一个特别的问题,我们试图设置固定的阈值t和p。为了便于解释,我们使用两层(fc2和conv4)来分析fc2层的阈值t和指数p的影响。如前所述,最低层的阈值t被设置为1,因此conv4的相似性被直接使用。在这种情况下,映射函数只适用于fc2层的相似性。特别地,曲线显示当fc2层的t被设置为1时直接级联的性能。
图3(b)-(d)显示了不同设置的结果,这说明映射函数可以利用更多的互补优势。尽管不同的设置会导致改进差异,但大多数设置都会改善三个数据集。同时,各种数据集的参数t和p达到最好的改善是相似的。其中t被设置为0.2并且p被设置为0.45。所提出的方法不会导致临时问题。参数设置的细节将在下面的实验中介绍。
4 初步
4.1 单层功能
我们以ImageNet ILSVRC 2012为例,对CNN进行了训练。该网络的结构由Krizhevsky等人提出,其中包含5个卷积层和3个全连通层。所有图层的设置与[1]相同,除非不使用局部对比度归一化图层,因为它们已被证明对ImageNet分类没有帮助。在下面的章节中,fci表示第i个完全连接层,convi表示第i个卷积层。在实验中,我们选择了三个卷积层(conv3,conv4和conv5)和两个完全连接层(fc1和fc2)来测量图像之间的相似度。
如前所述,完全连接层的输出直接被提取为特征。我们将卷积层的输出作为一组局部特征提取出来,并用超过4 M个特征的近似k-means(AKM)[27]对视觉词进行训练。然后采用BoW对卷积图的输出进行编码,作为图像的通用表示。
4.2 基准的细节
我们在三个众所周知的图像检索基准上展示了我们的方法:Oxford 5K[27],Holiday[28]和UKB[29]。
Oxford 5K是牛津大厦的数据集,包含5062张对应于牛津大地标的照片。对应于11个地标的图像被手动注释。提供了平均分布在这11个地标上的55个保留查询。
Holiday是INRIA假期数据集,其包括基于相同场景或对象的对应于500个组的1491个假期照片。来自每个组的一个图像用作查询。
UKB是肯塔基大学的基准数据集,其中包括10,200个2550个物体的室内照片(每个物体4张照片)。每个图像用于查询数据集的其余部分。按照常规设置,将Oxford 5 K和Holiday的表现报告为所提供查询的平均平均精度(mAP)。UKB的性能被报告为在前4个结果中的同一对象图像的平均数量,并且是在0和4之间的数字。特别地,所有图像的较短边被调整为256。
5实验
5.1 使用单层功能的结果
为了便于比较,我们报告了从CNN提取的单层特征的性能。表1显示了三个基准的结果比较。对于Oxford 5 K,Holiday和UKB,视觉词的数量分别设置为50K,100K和100K。
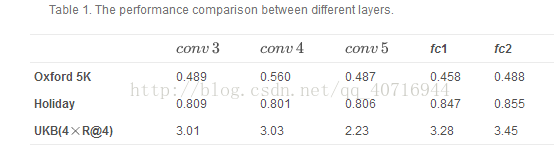
由于查询图像是类别级别类似的,并且fc特征不足以描述精细信息,因此conv图层可以胜过Oxford 5K上的fc图层。尽管Holiday和UKB数据集也旨在解决实例级图像检索的任务,但查询图像属于各种类别。因此,具有语义信息的fc特征可以在这两个数据集上获得更好的性能。
5.2 比较两层的不同组合
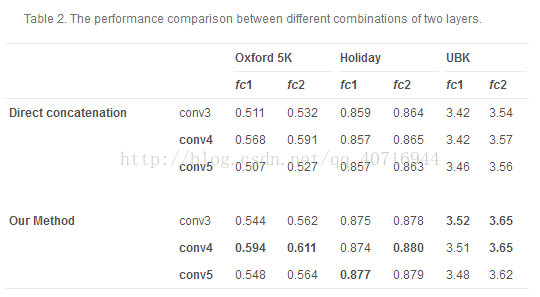
我们从测试两层的组合开始验证映射函数的有效性。我们的方法旨在利用不同层次之间的互补性,即高层和低层细粒度相似度的语义相似度,从而提取来自fc层的高层特征和来自conv层的低层特征。为了公平的比较,对于两层的所有组合,我们设置t1=0.2,p1=0.45和t2=1。
表2报告了在三个基准测试中的fc层和conv层之间的组合的性能,其中我们的方法优于直接级联方法。在某种程度上,组合的性能是由单层决定的。例如,fc2层一般优于fc1层,与fc2层的组合可以达到更好的性能。在Oxford 5K中,conv4达到竞争表现,与它的组合可以胜过其他组合。
5.3 比较不同的三层组合
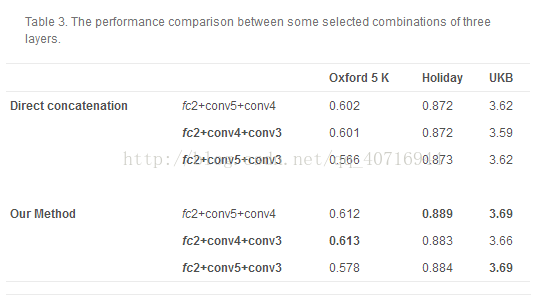
在这个实验中,图像相似度是通过三层来测量的,因此我们需要为最上面两层设置两组参数。对于第一层,我们设置t1 = 0.2,p1 = 0.45,设置两层组合。对于第二层,我们设置t2=0.4和p2=0.45。同样,我们设置t3=1为底层。
基于上述分析和结果,层组合的性能是由单层决定的。我们选择fc2层作为高层,因为与fc2的双层组合优于fc1的组合。因此,我们测试与fc2层的三层组合。表3报告了性能,其中我们的方法也优于直接级联方法。
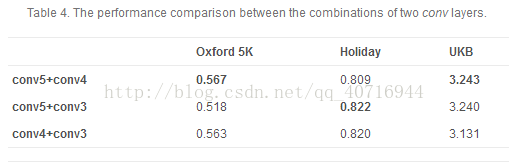
显然,三层结合可以达到更好的性能。但从三层结合到两层结合的改进,比单层到两层结合的改进少。为了分析这个问题,我们测试了两个conv层的组合。性能报告见表4,其中参数设置在第5.2节。比较表2和表4可以看出,从单层到双层的组合改进效果不如从单层到高层和低层组合的改进。例如,fc2和conv3的层次组合在Oxford 5K数据集中从0.488(fc2)提高到0.562,而conv4和conv3的层组合达到0.560(conv4)到0.563的改进。从单一的转换层到两个转换层的改进是很小的,这也导致从两层组合到三层组合的小改进。如前所述,conv层提取本地信息,而fc层代表全局信息。虽然不同的层次往往对不同层次的信息进行编码,但是各个层次之间的信息差异要比conv层次和fc层次之间的信息差异要小。fc层与conv层的互补性较强,fc层与conv层的双层组合可以得到显着的改善。
5.4 最先进的预训练模型的融合策略
在这一部分,我们尝试引入最先进的CNN模型来展示我们方法的推广。为此,我们在多层融合策略中采用了预先训练的VGG-16模型[2],以使结果更具说服力。测试VGG-16的所有层组合是非常耗时的,因为有13个卷积层和3个完全连接的层。因此,我们还选择两个完全连接的层(fc1和fc2)和三个卷积层(c3_1,c4_1和c5_1)来测量图像之间的相似度。
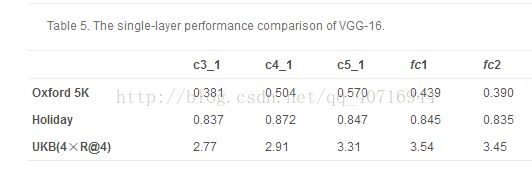
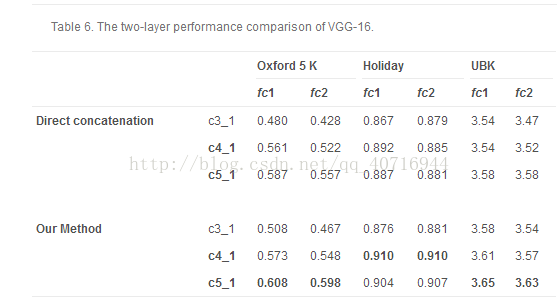
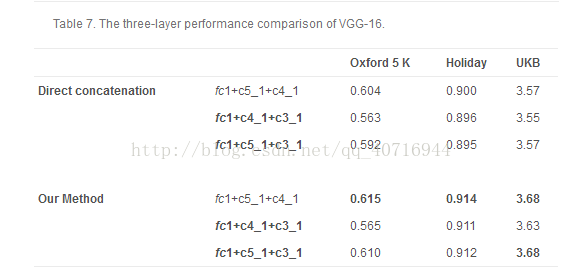
表5报告了三个基准的VGG-16的单层结果。 表6报告了fc层和conv层之间的组合的性能。对于VGG-16的三层组合,我们选择fc1层作为高层,因为与fc1的两层组合优于与emphfc2的组合。因此,我们用fc1层测试三层组合,表7报告了fc1层和两个conv层之间的组合的性能。考虑表5-7,当采用预先训练的VGG-16模型时,所提出的方法也得出类似的结论。
5.5 比较最先进的方法
作为我们实验的最后部分,我们将我们的方法与在图像检索任务上执行的最新方法进行比较。为了验证我们的方法,我们使用两个CNN模型:我们训练的AlexNet和预先训练的VGG-16。对于我们训练的AlexNet,我们利用fc2和conv4的两层结合以及fc2,conv5和conv4的三层结合,其中参数设置遵循5.2和5.3。对于预训练的VGG-16,我们利用两个fcl和c5_1的三层组合以及fcl,c5_1和c4_1的三层组合。表8报告了三个数据集上图像检索的性能,其中上半部分显示了基于手工特征的方法(从Sparse-编码特征到费舍尔+颜色)和底部显示了基于CNN特征的方法(从神经编码到我们的方法)的结果。
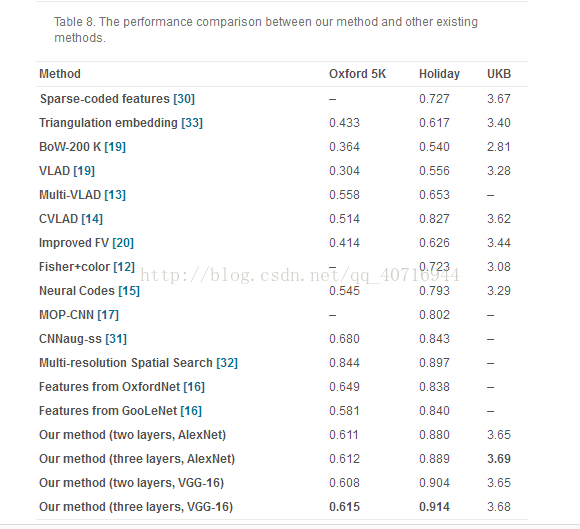
毫无疑问,我们的方法胜过了所有以前使用手工特征的方法,这证实了CNN特征在CBIR任务上可以更好地工作。我们的方法也明显优于使用预选的单层CNN特征(表示为神经编码)的方法和使用三层(表示为MOP-CNN)的直接级联的方法。特别是从不同尺度上提取特征,并选取性能最好的图层。我们的方法从单一尺度提取特征,并在牛津5K数据集上获得有竞争力的表现。需要指出的是,一些基于CNN特征的方法引入了空间信息并取得了很大的改善,如空间搜索。我们的方法展示了高层和低层之间的互补性,并提出了映射函数来提升性能。 同样,我们相信我们的方法的性能将进一步改善使用空间信息。
6.结论
受到CNN成功启发,我们提出进一步提高不同层次互补信息的图像检索性能。初步结果证明了我们的方法在测量CBIR相似性方面的有效性。 我们今后的工作包含两部分。一方面,我们会进一步改进我们的方法。如前所述,组合的性能是由单层性能决定的。其他方法可以用来编码卷积层的特征,例如VLAD。同时,我们的方法可以应用于更强大的网络,如VGGNet和GooLeNet。另一方面,我们将探索检索性能和存储空间之间的权衡,并试图改进我们的方法的一般性。例如,卷积层的聚合特征需要被压缩成低维表示。