20 Transfer Learning

本身的数据比较少,但是我们却有其他的数据。例如我们做个猫狗识别器,我们会有下面的数据,这些数据没有和任务直接相关。例如共同的领域,但是是不同的任务目标,例如左下的实体的大象和老虎。又例如不同的领域,但是是相同的任务目标,右下的虚体的狗和猫。
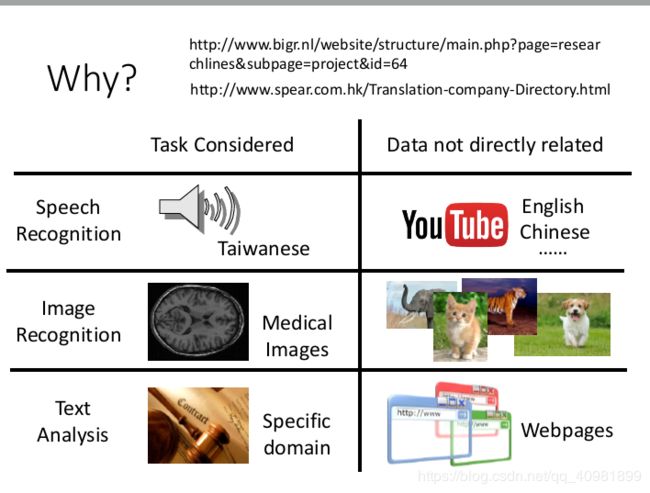
还有很多这方面的例子,如图上面的。

迁移学习就例如上面的,把漫画家和研究生的全身做了对比。这样我们可以看漫画家来大概了解研究生。
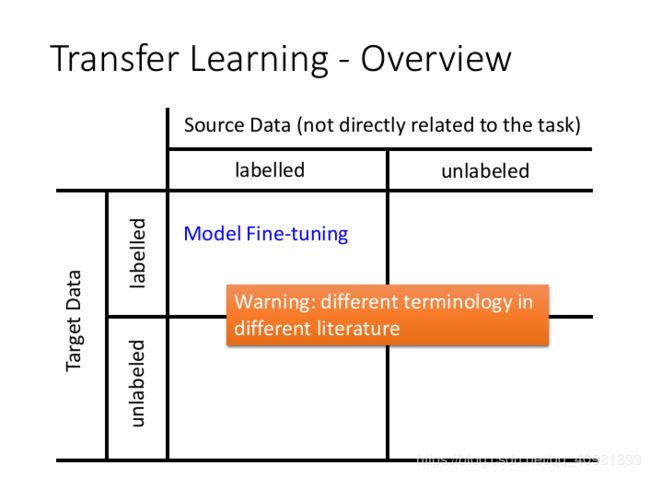
现在我们把各个情况做个总结。Source Data表示和我们的任务需求不是很相关的数据,Target Data和我们的任务需求一样的数据

我们先说第一个情况,两种data都是有label。现在描述这么一个情况,taeget data的数据非常少,但是我们却有大量不相关的source data,这种就叫做One-shot learning。
例如,上面的一个例子。
这些source data有没有用呢,怎么解决呢。方法是这样,我们先通过source data来训练一个模型,然后通过target data来进行finetune这个模型。由于太少的target data,很容易让模型overfitting。
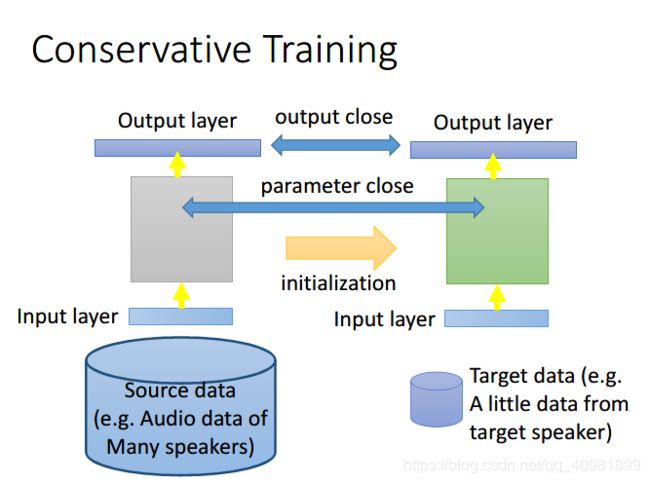
例如conservative training,就算我们用Source data来训练好了一个模型,然后我们用target data也来训练也不行,我们可以用target data来训练的时候加上一些constrain,就是加上regularization,让新的模型和旧的模型不是差的很远,例如训练的时候我们是加上L1 L2的 regularization 。但是在conservative training那里,我们加上另外一种的regularization,我们是希望一个相同的data,新的模型和旧的模型的输出越接近越好,或者新的模型和旧的模型,他们的L2 norm的差距越小越好。总之就是让新的模型和旧的模型的差距不要太大,防止overditting
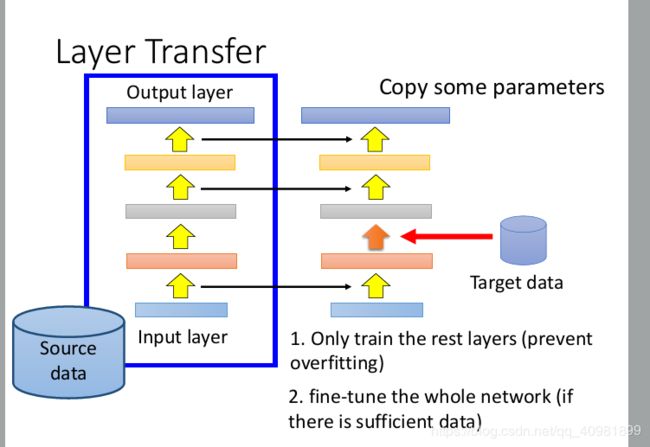
这是另外一个做法-Layer Transfer。把source data 训练出来的模型的某几个layer直接copy到新的model里面去,然后用target data只去train没有copy layer。这样的好处是source data只需要考虑非常少的参数。如果数据足够,可以直接fine-tune整个model

layer transfer是比较常见的做法。问题是哪些层需要是要transferred,整个需要根据任务来定。语音的是后面几层,图像是前面几层。
在语音上,每个人都是用同样的发音方式,但是却因为口腔结构略有差异等,同样的发音却得到不同的声音。神经网络的前面几层是通过声音讯号来得到说话人的发音方式,然后根据发音方式就可以得到哪一个词汇,来得到辨识的结果。 所以根据这个来看,神经网络的后面几层和说话人是没有关系的,所以是可以被copy的。 前面是从声音讯号到发音方式,每个人都不一样,所以做语音辨识的时候,常见都是copy后面几层。
而图像上,前面几层是提取出一些比较共用的特征、pattern,后面是抽取抽象的特征。所以哪些需要层可以迁移,就看具体的例子。
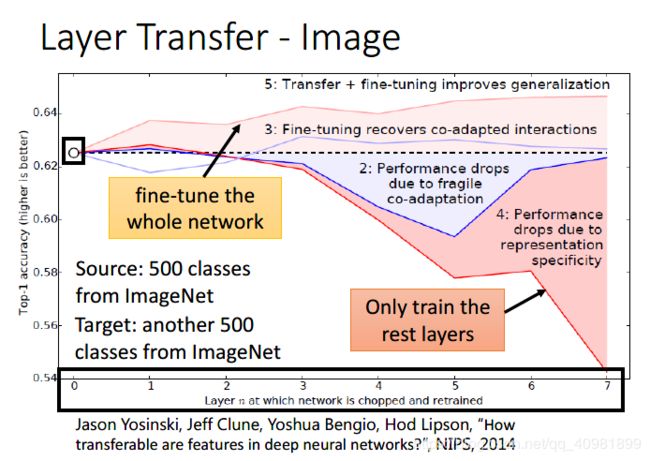
这个是使用imageNet的数据集,分类如上图的左下。折线图是对应的layer transfer的效果。
横坐标代表top-1的准确率,纵坐标代表了transfer了几层,那个虚线是没有任何transfer ,就是一个baseline
4: Performance drops due to representation specificity. 这是fix transfer的层,然后进行train后面的层数。可以看到后面都是烂掉了,说明越后面,特征提取的越抽象
5:Transfer+fine-tuning improves generalization。这个是迁移了,再来fine-tuning所有的层数,这个都是提高了泛化能力的
还有两条就是不关transfer learning的了,这个是用target data来训练模型
2:Performance drops due to fragile co-adaptation ,一个是训练了,然后固定前面的层数继续训练后面的层数,这个有些时候就会出现很差的结果,reference的作者认为前后的训练层是有着呼应的,如果这样训练就不是写作了
3:fine-tuning recovers co-adapted interactions ,一个是训练了,在fine-tune整个模型。这个结果就差不多
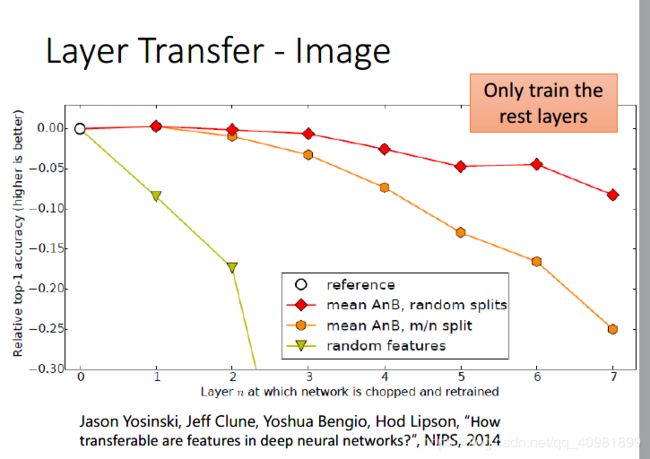
右下的坐标不是很能理解。最下面那条线的权重是随机初始化的。
在这个情况,除了fine-tuning,还有Multitask Learning
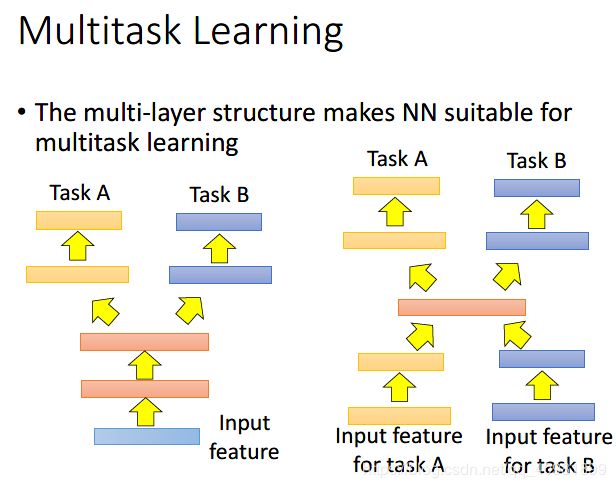
可以根据具体的任务来设置共享的权重层
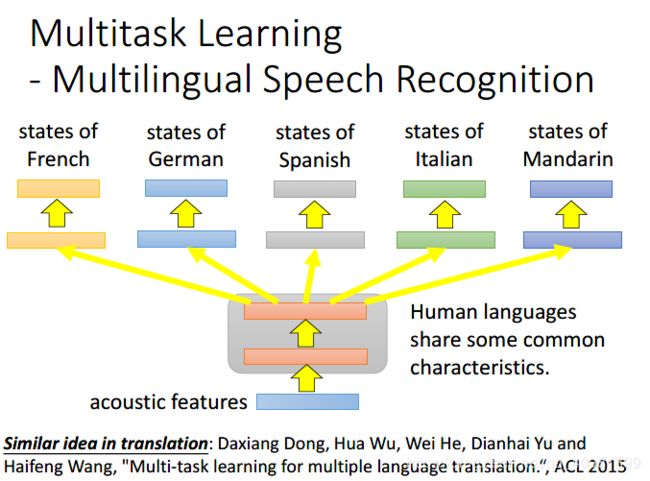 这个多语音识别的就是一个例子。
这个多语音识别的就是一个例子。

多语音识别的任务的效果是挺明显的。如果只是用mandarin来训练,这个效果是蓝色那条线,如果用European Language来作为基础,然后再拿mandarin训练模型,效果是橙色那条线。很明显,看那条红色的线,相同的效果却使蓝色那条线会需要更多的mandarin data
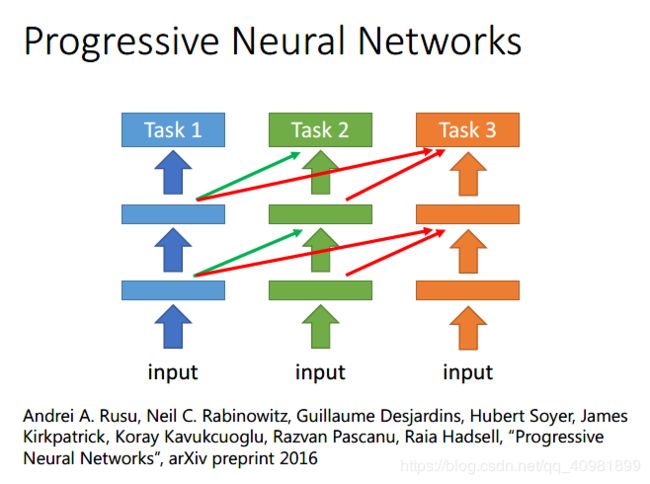
还有这个方式的迁移
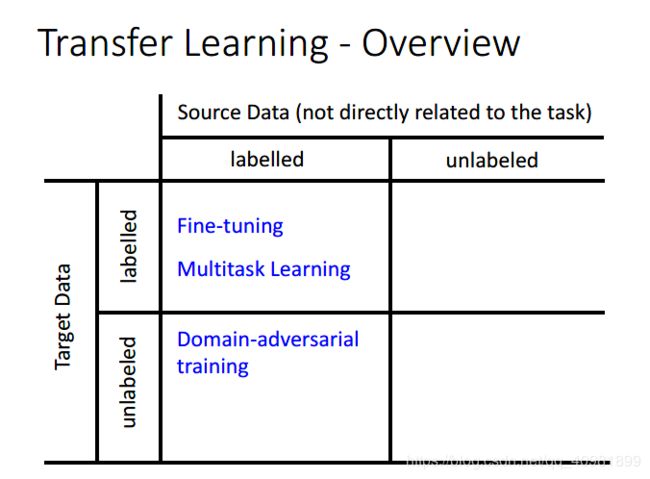
这个source data是labelled,target data是unlabeled data,称为Domain-adversarial training
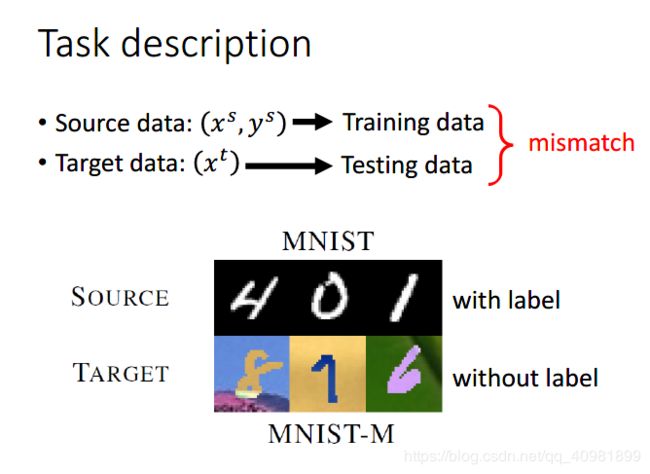
这两个数据是不同的领域的,是mismatch的
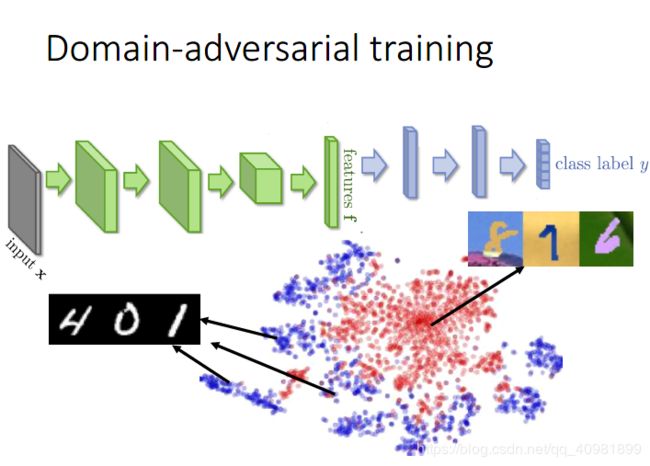
如果这样直接训练是没有办法分辨的,因为这个数据都mismatch。
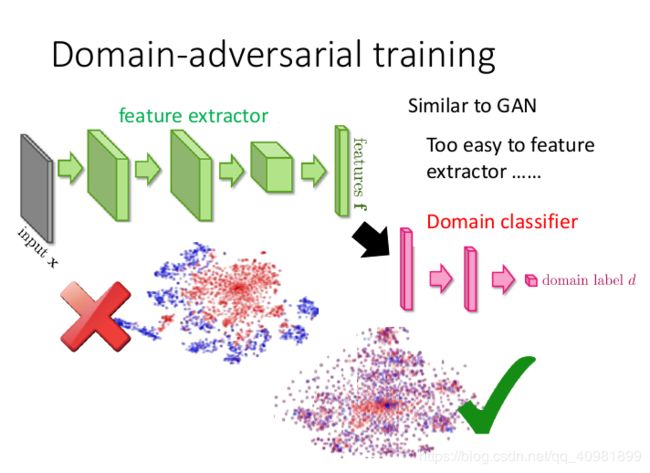
所以我们会建造一个新的分支作为domain的分类器来把domain去掉,就是不是红色和蓝色的点分成两群,而是让这两组点合成一簇。根据feature extractor提取出来的feature来分别是属于哪个corpus。这个就有点像GAN,我们就是就做让feature extractor提取出来的feature让这个domain classifier分辨不出来。这个时候会有一个solution,就是全部都是0就可以了。所以需要给feature extractor增加任务的难度。
我们不仅要让feature extractor输出的feature不仅要骗过domain classifier,还要同时让label predictor做的好。 就是要让feature extractor提取出来的feature不仅要消掉原来domain的特性消掉,还要保持digit的特性
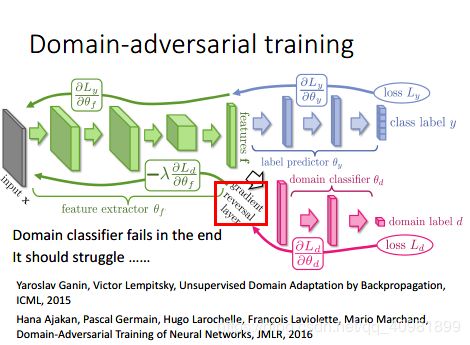
做法就是gradient reversal layer,具体在backpropragation中,domain classifer反馈的参数的调整要相反,例如是让feature extractor这个参数增加的,但是却让feature extractor这个参数减少。以此慢慢来骗过domain classifier。这个就会比较难训练,要很小心训练。
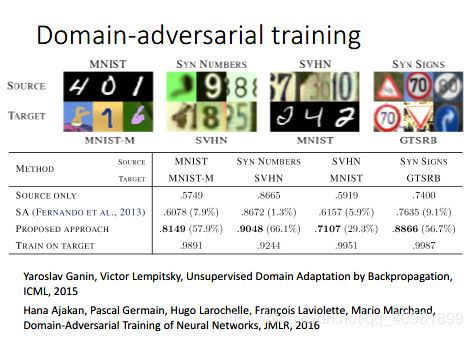
这个就是refer paper的结果。
第三行就是提出的方法的结果
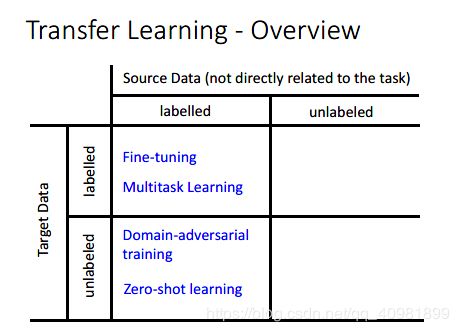

还有zero-shot learning,这个定义会更加苛刻。就是source data有着不同的种类,例如cat和dog,但是target data却有着一个source data没有的种类,例如草泥马,这样模型是很难一看到这个草泥马就知道这个是草泥马了。
在语音上这些例子就很多,你很容易碰上一些没有看到的语音。所以训练的时候,要让模型输出不是word,而是辨别出phoneme,之前要做一个phoneme和table之间对应关系的表,就是lexicon,就是辞典。根据人的知识建一个文字和phoneme对应关系的表。这样如果有一些word没有出现在training data里面的,但是只要出现在lexicon出现过,就可以了。(具体的还不是很懂)
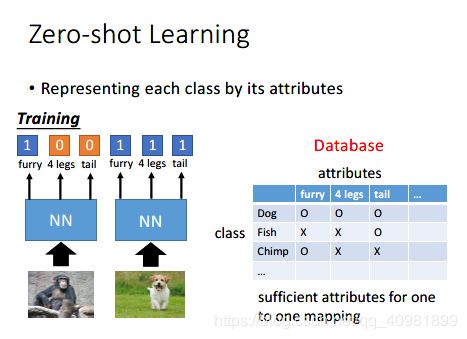
在影像就是把每一种动物用attributes来表示,attributes要定的够丰富,可以区别出每一种动物。这种属性可以用是否有毛皮、四个腿、是否有尾巴等。
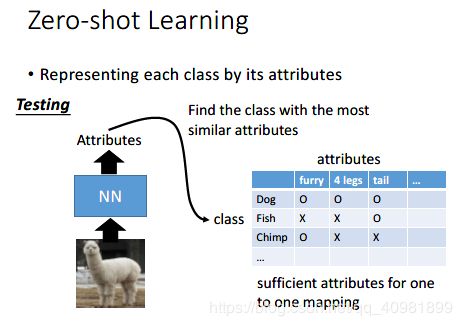
训练的这个模型就是要识别出这个对象的attribute是什么,然后对应起哪个是就输出哪个。就算没有任何的对应,我们就把最接近的输出
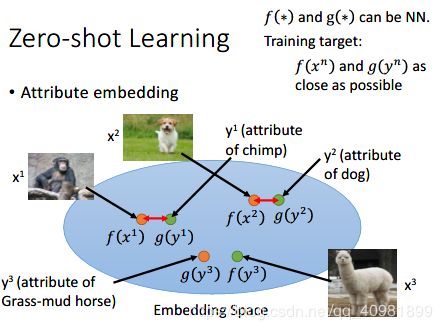
如果这个attribute比较复杂,我们可以attribute embedding,就是进行投射到attribute space上的点。就是把图像通过f投射到attribute space,然后把图像对应的attribute通过g投射到attribute space,然后这两个点需要越接近越好。这样有新的点通过f输出之后,我们就把最近的那个点的g给反应出哪些attribute。
如果我们没有这个database,我们根本不知道每一个动物对应的attribute是什么,我们可以借用word vector,我们可以用一个很大的corpus例如Wikipedia来train,来把attribute来直接换成word vector。然后剩下的做法一样。

可以看第一个式子,就是想让f和g对应的点越接近越好。但是这个式子会让所有的点都是同一个点就好。所以我们需要改进,就是下面的式子。我们不仅要让相同的点越接近越好,我们还有不同的点都不上相同的点,而且之间的差距要有一个margin,这个margin是自己定的。这样可以让模型训练的更好。
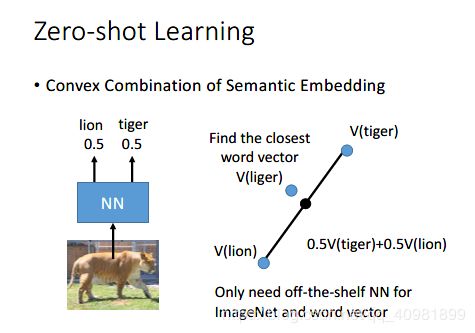
(这个不是很能理解) 就是通过off-the-shelf word vector和off-the-shelf 一个语音辨识系统。把一张图片丢进NN里面,里面只能识别0.5是狮子,0.5是老虎。然后我们把这个老虎和狮子的vector映射好,然后连接起来,各取0.5来得到一个点。把这个点最近的word vector的哪个word表示出来。
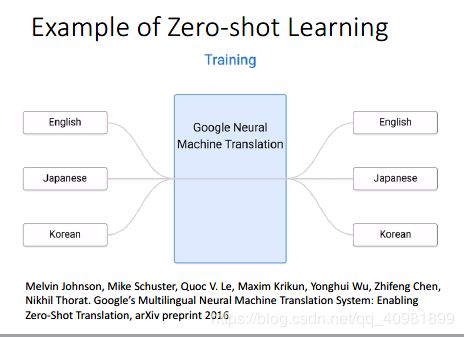
之前都是影像的例子,这个是另外的NLP的例子。例如里面有English转换成Japanese的data,Japanese转换成Korean的data,还有korean转换成Japanese的data。
这样如果直接输入korean,还可以翻译成English。这种之前没有直接训练的data。

这个就是machine通过把input的词汇通过encoder转换成embedding space的vector,然后再通过decoder把embedding space的vector转换成对应output的词汇。例如那个例子,右上都是一样的意思,但是里面却是不同的语言构成的,看右下。

这个是参考文献
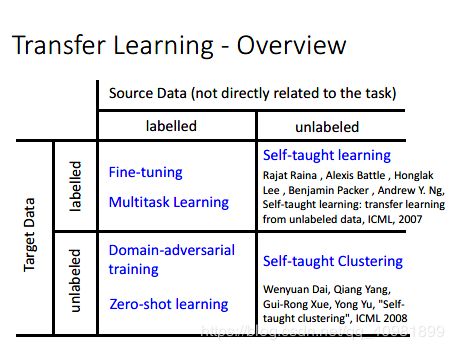
这个是transfer learning的另外的例子
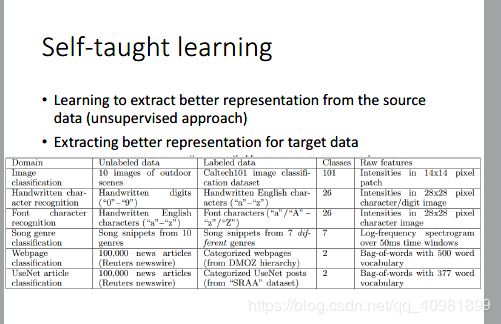
这个是self-taught learning