论文解读: | (CVPR2019)《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels》
论文解读:《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels》
首先,奉上论文和代码:
论文链接: Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels
代码链接: https://github.com/cszn/DPSR
研究方向:Image Super-Resolution
发表会议:CVPR 2019

[如有任何错误,还请大家指正,以免误人子弟!]
在正式开始前,让我们先看下论文最终实现的视觉效果:
Result Show
LR image |

Recovered/Ground-truth |
\quad 我们可以看到,LR(low pixel) and blurry(又小又模糊)的图像,经过处理后,竟然能得到复原度非常高的又大又清晰的SR(super resolver)的图像;
\quad 论文效果还是非常不错的!这也是我选择细读这篇论文的原因之一!
好,下面咱们进入正题:
\quad "能够应对任意模糊核的深度即插即用超分辨"是哈尔滨工业大学在CVPR2019上发表的关于超分辨(Super Resolver)方向的论文。
\quad 下面会按照论文的行文结构,分别进行阐述:
Abstract
\quad 首先,在摘要中,作者介绍了当前超分辨(SR)领域中出现的根本性问题,并简要概述了自己的解决方案。
首先看一下存在的问题:
Existing Problem
\quad 目前主流的单个图像超分辨(SISR)方法都是基于双三次退化(bicubic degradation)而设计的,并且,超分任意模糊核(blur kernel)的低分辨率图像(LR image)存在着根本性的问题。(对于双三次退化、模糊核等概念,后文会给出)。
说了半天,那么这个问题,到底是个什么样的问题呢?下面图示说明:
 LR image
LR image
|
 RCAN(SOTA)
RCAN(SOTA)
|
 Ground-truth
Ground-truth
|
\quad 最左侧为模糊的LR图像,中间为LR图像经过目前最高水平(state-of-the-art)的模型RCAN进行处理后得到结果,最右侧为真实场景图像。
\quad 大家可以看到,经SOTA模型处理后的LR图像,反而变得更加的模糊和不清晰,这是什么原因造成的呢?
\quad 这就是论文摘要中提到的,目前主要的SISR模型都是基于双三次退化模型(bicubic degradation model)而设计的,但若将输入到这些SOTA模型中的图像改为,比如说,我们日常生活中由于相机抖动、焦距问题导致的模糊的LR图像,那么得到的SR图像的效果可能就不那么好了,还有可能会恶化!譬如上图中展现的结果。
那说了这么半天,
\quad Q1: 到底什么是退化模型(Degradation Model)呢?
\quad ans:
退化模型(Degradation Model):
\quad 定义LR图像是如何从SR图像退化而来的数学模型,即表征LR图像与SR图像之间的关系。
在冈萨雷斯所著的《数字图像处理》一书中,对退化模型有明确的定义,有兴趣的同学可以看下:

《数字图像处理》 |

图像退化 / 复原过程模型 |
\quad 由于上述的模型表示较为抽象且不够具体,所以,下面给出较为清晰明了的Degradation Model的定义公式:
B = I ⊗ K + N B = I \otimes K + N B=I⊗K+N
\quad 其中,B为模糊图像(blurry image),I为待估计的清晰图像(latent image),K为模糊核(blur kernel),N为附加的噪声, ⊗ \otimes ⊗为卷积操作。
\quad 即,HR(high pixel)图像I与一种特定排列的矩阵(blur kernel)做卷积操作,得到模糊(blurry)图像,再对模糊图像附加噪声N,最终即得到LR图像B。
这时,你可能会问:那什么是模糊核(blur kernel)呢?
我们首先从下面的实例感性的认识下:

上图展示了模糊核的作用效果。
模糊核(blur kernel):
\quad 模糊核实际上就是一个矩阵,是卷积核的一种,清晰图像与模糊核进行卷积操作后会变模糊,所以称这一种卷积核为模糊核(blur kernel)。
\quad 模糊核的种类有很多,包括高斯(Gaussian)模糊核,运动(motion)模糊核,散焦(disk)模糊核等,其实就是能够给清晰图像造成一些特定效果的,特定排列的矩阵(卷积核)。
\quad 现在,咱们再来看一下论文的题目:“Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels”;
至此,各位读者应该能理解题目一半的意思了。
那,题目的另一半是什么呢?即, Plug-and-Play,直译过来就是即插即用,下面简要介绍下,这里所述的即插即用的概念:
\quad 即插即用框架(plug-and-play framework)最早应用于图像恢复(image restoration)领域,它可以实现模块化(modular structure) 的网络结构,DNN中的每个部分各司其职,并且可以在整体结构改动很小的情况下,实现各个模块的装卸和更替。
\quad 总的来说,你可以认为Plug-and-Play framework是把设计模式引入到了深度学习的神经网络架构设计当中,实现了很高层次的封装。
\quad 嗯,现在大家应该能够明白这篇论文题目的具体含义了。
那让我们进入下一部分,
1. Introduction
首先,介绍一下,目前广泛使用的两种退化模型(Degradation Model):

这里给出了两个退化模型,其中各个符号的含义已给出,下面对两个公式做简要分析:
\quad Eqn.(1)是公认的SISR的通用退化模型,但公式(1)并没有被广泛使用,原因是它必须要事先知道LR图像是由怎样的模糊核(blur kernel)经退化模型得到的,但,实际上对于任意图像的模糊核是很难评估的;
\quad Eqn.(2)则是在SISR领域最广泛使用的退化模型,因为其非常简单,只对原始的HR图像做了一次缩放因子为S的双三次采样,即可得到LR图像。(ps: 关于双三次下采样(bicubic sampling),大家可以认为是一种插值方法,类似于牛顿插值,可以以很平滑的曲线拟合数据集,用在CV领域中,效果类似,大家如果想深究,可以自行百度)。
\quad 这里强调一点,就像Abstract开头说的,目前SISR领域,针对的超分是,只有对经双三次退化(公式(2))得到的LR图像进行超分时,才能得到比较好的结果。而当对一个不是仅仅依照双三次退化(bicubic degradation),这样简单的退化模型得到的LR图像进行超分时,目前的SOTA模型表现的都很差!
\quad 同时这也是一个实际问题,因为SISR的最终目的是实现盲超分(Blind Super Resolver),即无需事先知道模糊核,只通过LR图像即可得到SR图像,甚至是超越Ground Truth图像!
\quad 所以,实际上,目前的SISR还局限于人们自己为自己划定的一个很小很理想的角落里,默默的挣扎♂️…
\quad 有点跑题了(给各位普及下超分领域的现状)。
所以,
\quad Q2: 目前面对的具体问题(issues)是什么呢?
\quad ans:
Issues

即,一个简单的退化模型在实际场景中,不可避免地会给出一些很差的结果。
那如何解决呢?目前来看,有两个主要途径:

\quad 由于提出贴合实际问题的,能够解决盲超分(Blind Super Resolver)的退化模型是一件非常困难的事。
\quad 原因如下:
- 模糊核的解空间太大,导致模糊核的采样非常困难,而且,即使采集了足够的模糊核,那么也会需要非常长的时间来训练一个实用的模型。
- 暂撇开模糊核不说,制定一个泛化能力足够强的可以应对实际问题的退化模型,这本身就是一件很困难的事,如果退化模型都没做好,那么,评估模糊核就无从谈起了。
现在,咱们来看看,作者针对存在的问题的解决方案,
Solution
作者的解决方案(Solution):
\quad 1. 由于上面提出的原因, 所以作者选择了扩展存在的基于DNN方法的双三次退化,提出基于公式(2)进行扩展的退化模型(Degradation Model)。
\quad 2. 为了优化新提出的退化模型(degradation model)引发的能量函数(energy function),故他们用一些数学方法(i.e. variable splitting technique)导出了即插即用算法(plug-and-play algorithm)以优化引发的能量函数,同时,即插即用算法(plug-and-play algorithm)可以把超分先验(super-resolver prior)而非去噪先验(denoiser prior)作为算法的一个独立的模块,从而,实现了他论文题目中提到的即插即用(Plug-and-Play),故而,只需要很少的修改就可将Super-Resolver应用到作者搭建好的整体程序框架当中。(ps: 此处的Super-Resolver指的就是目前表现最好的模型)。
\quad 这里需要强调的一点就是,本篇论文主要是为解决“non-blind SISR for arbitrary uniform blur kernels”,即应对均匀模糊核的非盲超分,而不是“blind SISR for arbitrary non-uniform blur kernels”,即应对非均匀模糊核的盲超分。
\quad 简单的说就是,对LR图像进行超分之前,必须提供相应的模糊核,而且这篇论文只能处理均匀的模糊核♂️。。。所以,实际来说,限制还是比较大的!
2. Related Work,本篇解读略过第二部分,大家有问题可在讨论区提问。
---------------------------------------------- 分界线 ----------------------------------------------
下面着重讲下第三部分,
3. Methods
3.1. New Degradation Model
首先,作者基于公式(2)提出了全新的退化模型,目的是利用已有的盲去模糊(blind deblurring)方法更好的评估模糊核。
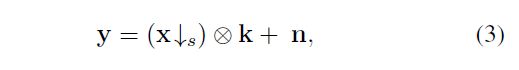
\quad 从Eqn.(3),我们可以得到,y是经高清图像X经过双三次下采样,之后又与模糊核进行卷积操作加上模糊,然后再加噪声的噪声模糊LR图像。论文中,对X↓形容,用了clean image一词,实际上,clean image就是未经过模糊核处理的无模糊的LR图像。
\quad 根据Eqn.(3)的退化模型,如果我们想要通过LR图像y,还原出HR图像X,首先需要去模糊(deblurring),然后再进行超分(SR)。
\quad 所以,实际上Eqn.(3)的退化模型,实际上对应于一个去模糊问题,然后是超分辨问题。
这样,就能用已有的盲去模糊(blind blurring)方法对模糊核进行评估了。
\quad Q3: 盲去模糊(blind blurring)的概念?
\quad ans:盲去模糊(blind deblurring)就是,在没有关于模糊核信息的前提下,给定模糊图像 I b I_{b} Ib,复原清晰图像 I s I_{s} Is。
这里说下,为什么作者说他提出的Eqn.(3)更好,先看下这三个退化模型各自的操作的顺序,

先说简单的,
Eqn.(2),只有一个双三次下采样操作;
Eqn.(1),首先对HR图像进行,加模糊,然后再进行一系列下采样,得到模糊且不清晰的图像,最后加AWGN,得到LR图像y。
Eqn.(3),首先对HR图像进行双三次下采样,然后加模糊,最后加AWGN,得到LR图像y。
那为什么Eqn.(3)要更好呢?
\quad 大家可以想下,如果我们对经Eqn.(1)对应的退化模型得到的LR图像进行超分(SR)复原HR图像,那么应该是这样进行的,首先对LR图像进行超分,再对超分后得到的结果进行去模糊(即生成LR图像的逆过程),但是,实际上,这样做的效果并不会很好,因为,你首先进行超分(SR)的图像本身就不是清楚的图像,所以,DNN并不能学习到足够有用的信息,而且,在没去模糊的情况下,进行超分(SR),实际上会扩大perturbation error(后面会介绍),甚至使图像变得更差!
\quad 而对经Eqn.(3)对应的退化模型得到的LR图像进行超分(SR)复原HR图像,则是先去模糊,再进行超分(SR),这样,进行超分(SR)时神经网络就可以学到足够多的信息,也会减轻perturbation error。所以,基于Eqn.(3)对应的退化模型进行超分(SR),效果会更好!
\quad 一旦退化模型确定了,接下来就要公式化能量函数(Energy Function),根据最大后验概率(MAP),得到Eqn.(4),
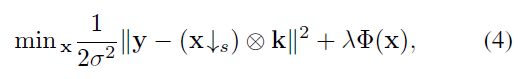
这里,先说下,什么是能量函数(Energy Function),

\quad 所以,实际上,能量函数(Energy Function)的作用类似于代价函数,最小化能量函数(Energy Function),即可得到全局最优解。
\quad Q4: 这时,有人可能会问,那为什么一定要用能量函数(Energy Function)而非代价函数呢?
\quad ans:因为,只有使用能量函数,才能将新提出的退化模型融入到整个网络结构中去,而代价函数则不具备这一能力。
大家对比Eqn.(3)和Eqn.(4),可以发现,且公式符号解释中明确指出Eqn.(4)中的数据保真度(data fidelity),实际上是Eqn.(3)中公式左侧y - 公式右侧第一项;因而,就退化模型(Degadation Model)引入到能量函数(Energy Function)中。
|
Eqn.(3) |
|
Eqn.(4) |

公式中各符号的含义 |
值得指出的是,对于判别学习(discriminative learning)而言,他们的推理模型实际上对应于一个能量函数(Energy Function),并且,实际上,
\quad 退化模型(Degradation Model)是被用于训练的LR图像和HR图像隐式定义(implicitly defined)的。
\quad 这也解释了为什么基于双三次下采样(bicubic sampling)的DNN方法会在很多真实世界图像上,表现得很差!(Because the degradation mismatch!)
接下来,咱们进入Methods的第二部分,
3.2. Deep plug-and-play SISR
\quad 首先,如下图所示,为了解决Eqn. (4)的最小化问题,作者采用variable splitting technique(变量拆分技术)引入辅助变量z,导出了等效约束优化公式,Eqn.(5)。
\quad 接着,为了解决Eqn.(5),又引入了半二次拆分算法(HQS,half quadratic splitting algorithm),得到了Eqn.(6), \quad (ps:其他方法,像ADMM,交替方向乘子法(Alternating Direction Method of Multipliers)也是可以的,此处为了简便,采用了HQS)。
\quad 然后,HQS通过最小化引入了惩罚项μ的Eqn.(6)来处理Eqn.(5),惩罚项μ的作用,途中已给出。

\quad 接下来,到了本文最核心的两个式子,即,Eqn.(7)、Eqn.(8),如文中所述,Eqn.(7)、Eqn.(8)是Eqn.(6)的交替执行的迭代solution(~ ̄▽ ̄)~。
\quad 为了清晰明了的解释三个公式之间的逻辑关系,博主特意绘制了下图( ̄▽ ̄)*,通常,在Eqn.(7)、Eqn.(8)的交替最小化问题的迭代解决方案中,惩罚项μ是非降序变化的。
此处说明下Eqn.(7)、Eqn.(8)的具体含义:
\quad Eqn.(7):解决了模糊失真的问题,也就是把当前的模糊图像拉到一个不那么模糊的位置(deblurring)。
\quad Eqn.(8):映射 Eqn.(7)得到的不那么模糊的图像 ----> 一个更clean的HR图像(SR)。

\quad 这时,有人可能会问,
\quad Q5: “为什么必须要交替执行呢?先一次性去完模糊再进行超分不行吗?”
\quad ans:先埋个伏笔,后文揭晓。
咱们先顺着思路继续往下看,若假定卷积操作是在圆形边界条件(circular boundary conditions)下执行的,那么Eqn. (7)有一个快速的闭合式的写法,即,Eqn.(9),如下图所示,其中F表示快速傅里叶变换(其他参数,诸位详见论文!)
\quad 这里,为什么要引入快速傅里叶变换(Fast Fourier Transform(FFT))呢?
\quad ans:计算机专业上过《通信原理》选修课的同学,可能知道,傅里叶变换主要是用来干什么的;那在本文中,将Eqn. (7)---->Eqn. (9)的原因是什么呢?引用文中的一段话:"the distortion of blur can be effectively handled in Fourier domain."
即,傅里叶变换可以非常有效的处理图像的模糊失真,现在再看上张图中,Eqn. (7)的作用,大家应该明白了吧!

至于由Eqn.(8) —>Eqn.(10),作者说,是要从贝叶斯(Bayesian)的角度来看待Eqn.(8),实际上也是为了方便后文的论述 (详情大家可以参阅论文中的脚标或其他资料)。
各位同学,注意下,接下来的部分,可能就不是那么好理解了,
\quad 实际上,Eqn.(10)通过假定 Z k + 1 Z_{k+1} Zk+1 是对HR图像X经双三次下采样 (bicubicly downsampli1ng),然后再加上噪声水平为 1 / μ \sqrt[]{1/μ } 1/μ 的加性高斯白噪声(AGWN)得到的。 那么我们可以认为,Eqn.(10)对应的这个SR的步骤着对应如下图,Eqn.(11)所表示的退化模型。
大家看下,下图中,Eqn.(4)中范数内的部分和Eqn.(3)表示的退化模型,再对比Eqn.(10)与Eqn.(11),应该能明白Eqn.(10)为什么能对应Eqn.(11)表示的退化模型了吧!
|
Eqn.(4) |
Eqn.(3) |

Eqn.(10) |
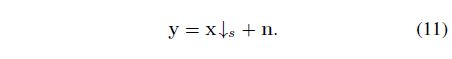
Eqn.(11) |
最后,再对Eqn.(10)进行封装,就可以得到Eqn.(12),

Eqn.(12)即可以实现即插即用,如何实现呢?
只需要给定输入LR图像 Z k + 1 Z_{k+1} Zk+1 、缩放因子S,
至此,便实现了Methods中第二部分的即插即用(Plug-and-Play),噪声水平为 1 / μ \sqrt[]{1/μ } 1/μ ,即可!
诸位可能会问,
\quad Q6:我怎么把训练好的模型插到他的框架中去呢?
\quad ans:实际上,这点作者已经在前文提到了,Eqn.(10)中的Ф(x)先验项就是Deep Super Resolver,也即是可插入的DNN模型。
至此,可以长吁一口气,终于结束了Methods第二部分了!
3.3. Deep Super-Resolver Prior
为了插入应用于SISR的SOTA的DNN模型,需要对原模型进行简单的修改:
- 增加噪声水平图(noise level map)作为输入项。
- 将特征图(feature map)从64增加至96。
- 移除批量正则化(BN)层。
具体的训练方法和参数,此处不再赘述。
3.4. Comparison with related methods
这里先回答下Q4,
\quad Q5:“为什么必须要交替执行去模糊(Deblurring)和超分(SR)呢?先一次性去完模糊再进行超分不行吗?”
\quad ans: 如果一次性去完模糊再进行超分的话,往往会得不到很好的结果,原因就是,step1不可能一次性就将模糊完全去除,会有残留;那么在step2进行SR的时候,就会扩大第一步残留的扰动误差(perturbation error),从而导致最终的效果不好,而交替执行去模糊和超分可以将perturbation error降到最低!
Q4的ans即是3.4中提到的Cascaded deblurring and SISR;关于像素平均问题(the pixel-wise average problem)和3.4的其他部分,详情请诸位参见论文。
4. Experiments
4.1. Synthetic LR images
\quad 首先,给出作者用于合成HR图像的模糊核,这里,由于模糊核的解空间太大,没有办法全部覆盖,所以,取三种有代表性的模糊核,如下图所示,1. 高斯模糊核(Gaussian);2. 运动模糊核(Motion);3. 散焦模糊核(Disk)。

Synthetic LR images: 左上角为合成LR图像所采用的模糊核。

接下来,看下作者都用了哪些模型做对比,
Compared Models
- VDSR:第一个应用于SISR的DNN。
- RCAN:针对双三次退化的SOTA。
- IRCNN:即插即用的处理非盲图像去模糊的深度去噪先验。
- DeblurGAN:基于GAN的深度盲去模糊。
- GFN:联合处理去模糊和超分辨。
- ZSSR:无监督超分模糊噪声LR图像。
\quad 由于作者提出的是能够应对任意模糊核的SISR模型,所以,公平起见,对比实验的模型要么是既可去模糊又可进行超分(SR),要么就要将去模糊的模型和超分(SR)模型联合起来使用,从而进行对比实验。
现在看下实验结果1,如下图,

下面逐个分析,
( c ): 双三次下采样得到的图像,没什么好说的;
(d)、(e):VDSR、RCAN, 效果都不好,原因就是,他们都是基于Eqn. (2)对应的简单的退化模型做的,而LR图像(b)是经Eqn. (3)退化莫i选哪个得到的。退化模型不匹配(Degradation mismactch),是导致其效果差的根本原因。
(f): IRCNN + RCAN,效果还可以。
(g): DeblurGAN + RCAN,这个组合效果差的原因即是Q4,RCAN扩大了DeblurGAN产生的扰动误差。
(h): GFN效果不好的原因,作者分析是,连续的卷积层在处理复杂的模糊核时,能力有限。
(i): ZSSR,meta-learning中的zero-shot,效果不好的原因是缺乏对模糊LR图像的重现性(第一次都没看清楚,第二次想复现HR图像,怎么可能实现,人都不能,更别说原学习了)。
再看实验结果5,值得一提的是,这三张图像,作者都没有原始HR图像。
 \quad 对于第一幅图像,在无原始HR图像的情况下,使用已有的盲去模糊(blind dlurring)方法,评估了它的模糊核,并且得到了相对而言比较好的效果。
\quad 对于第一幅图像,在无原始HR图像的情况下,使用已有的盲去模糊(blind dlurring)方法,评估了它的模糊核,并且得到了相对而言比较好的效果。
\quad 对于第二幅LR图像,作者选择直接对其进行超分,跳过了去模糊的步骤。
\quad 第三幅图像是经一个复杂的模糊核经退化模型变换得到的,只有作者使用的DPSR可以很好的还原!
实验部分的分析到此结束,如果问题,欢迎评论区讨论。
结语
最后,让我们看下这篇论文的改进点:
- 提出比双三次退化更实用的退化模型。
- 提出一种利用新提出的退化模型的深度即插即用的超分辨框架来解决SISR问题。
- DPSR是原理明确的, 迭代方案旨在解决全新的包含能量函数的退化。
- DPSR扩展了现存的即插即用框架,表明了应用于SISR的即插即用先验(prior)不仅限于"高斯去噪器(Gaussian Denoiser)",还可以是Deep Super Relover。
说来说去,这篇论文最大的贡献是什么呢?
原文是这样写的:our work makes a valuable intermediate step from existing bicubic degradation based SISR to ultimate blind SISR.(≧∇≦)ノ
最后奉上中外名人名言:
阿姆斯特朗说:“这是我迈出的一小步,却是人类迈出的一大步!”
荀子《劝学》中有言:“不积跬步无以至千里,不积小流无以成江海!”
好,最后,祝大家学有所成,每天迈出一小步!成就最终的一大步!
.
推荐
由于这篇博客需要的数学知识很多,可以想见,Computer Vision / DeepLearning若要做到深入,那一定是要深厚的数学知识的,那数学学到什么程度才可以应对AI中的大部分数学问题呢?
这里抛出最后一个问题,
\quad Q7: 需要学习多少数学知识才可以应对DeepLearning中的大多数数学问题呢?
\quad ans: 推荐大家阅读由Ian Goodfellow所著的"花书"——《深度学习》,开篇第一章即是介绍学习DeepLearning所需要的数学知识,相信各位同学读完之后,再看paper中的数学公式,会觉得有如神助!

博主也在看的说( ̄︶ ̄)↗ (ps: 图源自某宝)
参考资料
https://blog.csdn.net/Terrenceyuu/article/details/65936410
https://blog.csdn.net/zssyu0416/article/details/80407870
https://blog.csdn.net/xueruhongchen/article/details/52783119?locationNum=4
https://blog.csdn.net/zseqsc_asd/article/details/88837332
此处,鸣谢以上所有博客的博主 and 度娘!
CSDN资源
- 博主制作的关于讲解本篇论文的ppt
- 博主阅读本篇论文时标记注释的论文pdf文件