- 强大的ETL利器—DataFlow3.0
lixiang2114
数据分析etlflumesqoop数据库数据仓库
产品开发背景DataFlow是基于应用数据流程的一套分布式ETL系统服务组件,其前身是LogCollector2.0日志系统框架,自LogCollector3.0版本开始正式更名为DataFlow3.0。目前常用的ETL工具Flume、LogStash、Kettle、Sqoop等也可以完成数据的采集、传输、转换和存储;但这些工具都不具备事务一致性。比如Flume工具仅能应用到通信质量无障碍的局域网
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
m0_74823705
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- 数据仓库与数据挖掘记录 三
匆匆整棹还
数据挖掘
数据仓库的数据存储和处理数据的ETL过程数据ETL是用来实现异构数据源的数据集成,即完成数据的抓取/抽取、清洗、转换.加载与索引等数据调和工作,如图2.2所示。1)数据提取(Extract)从多个数据源中获取原始数据(如数据库、日志文件、API、云存储等)。数据源可能是结构化(如MySQL)、半结构化(如JSON)、非结构化(如文本)。关键技术:SQL查询、Web爬虫、日志采集工具(如Flume)
- 【大数据技术】搭建完全分布式高可用大数据集群(Flume)
Want595
Python大数据采集与分析大数据分布式flume
搭建完全分布式高可用大数据集群(Flume)apache-flume-1.11.0-bin.tar.gz注:请在阅读本篇文章前,将以上资源下载下来。写在前面本文主要介绍搭建完全分布式高可用集群Flume的详细步骤。注意:统一约定将软件安装包存放于虚拟机的/software目录下,软件安装至/opt目录下。安装Flume用finalshell将压缩包上传到虚拟机master的/software目录下
- 计算机毕业设计hadoop+spark+hive新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 大数据毕业设计 深度学习 知识图谱 人工智能
qq+593186283
hadoop大数据人工智能
(1)设计目的本次设计一个基于Hive的新能源汽车数据仓管理系统。企业管理员登录系统后可以在汽车保养时,根据这些汽车内置传感器传回的数据分析其故障原因,以便维修人员更加及时准确处理相关的故障问题。或者对这些数据分析之后向车主进行预警提示车主注意保养汽车,以提高汽车行驶的安全系数。(2)设计要求利用Flume进行分布式的日志数据采集,Kafka实现高吞吐量的数据传输,DateX进行数据清洗、转换和整
- python消费kafka数据nginx日志实时_基于nginx+flume+kafka+mongodb实现埋点数据采集
weixin_39534208
名词解释埋点其实就是用于记录用户在页面的一些操作行为。例如,用户访问页面(PV,PageViews)、访问页面用户数量(UV,UserViews)、页面停留、按钮点击、文件下载等,这些都属于用户的操作行为。开发背景我司之前在处理埋点数据采集时,模式很简单,当用户操作页面控件时,前端监听到操作事件,并根据上下文环境,将事件相关的数据通过接口调用发送至埋点数据采集服务(简称ets服务),ets服务对数
- 大数据-267 实时数仓 - ODS Lambda架构 Kappa架构 核心思想
m0_74823336
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!MyBatis更新完毕目前开始更新Spring,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)Cl
- nginx+flume网络流量日志实时数据分析实战_日志数据分析(1)
2401_84182578
程序员nginxflume数据分析
得到visits模型hadoopjar/export/data/mapreduce/web_log.jarcn.itcast.bigdata.weblog.clickstream.ClickStreamVisit网络日志数据分析-数据加载对于日志数据的分析,Hive也分为三层:ods层、dw层、app层创建数据库createdatabaseifnotexistsweb_log_ods;create
- 【大数据入门核心技术-Flume】(二)Flume安装部署
forest_long
大数据技术入门到21天通关bigdatahadoop大数据hbaseflume
目录一、准备工作1、基本Hadoop环境安装2、下载安装包二、安装1、解压2、修改环境变量3、修改并配置flume-env.sh文件4、验证是否安装成功一、准备工作1、基本Hadoop环境安装参考Hadoop安装【大数据入门核心技术-Hadoop】(五)Hadoop3.2.1非高可用集群搭建【大数据入门核心技术-Hadoop】(六)Hadoop3.2.1高可用集群搭建2、下载安装包官方网址:
- java.io.FileNotFoundException: /tmp/log/flume-ng/flume.log (Permission denied)
海洋 之心
Flume问题解决Hadoop问题解决javaflume开发语言zookeeper大数据
文章目录问题描述:原因分析:解决方案:问题描述:使用Flume将本地文件监控上传到HDFS上时出现log4j:ERRORsetFile(null,true)callfailed.java.io.FileNotFoundException:/tmp/log/flume-ng/flume.log(Permissiondenied)log4j:ERRORsetFile(null,true)callfai
- flume系列之:消费Kafka集群Topic报错java.io.IOException: Can‘t resolve address: data03:9092
快乐骑行^_^
flumeflume系列消费Kafka集群TopicOExceptionresolveaddress
flume系列之:消费Kafka集群Topic报错java.io.IOException:Can'tresolveaddress:data03:9092Causedby:java.nio.channels.UnresolvedAddressException一、flume消费Kafka集群Topic报错二、报错原因三、解决方法一、flume消费Kafka集群Topic报错21Sep202214:5
- 基于Spark的实时计算服务的流程架构
小小搬运工40
spark大数据
基于Spark的实时计算服务的流程架构通常涉及多个组件和步骤,从数据采集到数据处理,再到结果输出和监控。以下是一个典型的基于Spark的实时计算服务的流程架构:1.数据源数据源是实时计算服务的起点,常见的数据源包括:消息队列:如Kafka、RabbitMQ、AmazonKinesis等。日志系统:如Flume、Logstash等。传感器数据:物联网设备产生的数据流。数据库变更数据捕获(CDC):如
- 大数据开发的底层逻辑是什么?
瑰茵
大数据
大数据开发的底层逻辑主要围绕数据的生命周期进行,包括数据的采集、存储、处理、分析和可视化等环节。以下是大数据开发的一些关键底层逻辑:数据采集:目的:从不同的数据源(如日志文件、数据库、传感器等)收集数据。方法:使用数据采集工具(如ApacheFlume、ApacheKafka、ApacheSqoop)来捕获和传输数据。数据存储:目的:将收集到的数据存储在可靠且可扩展的存储系统中。方法:使用分布式文
- flume+ Elasticsearch +kibana环境搭建及讲解
pincharensheng
大数据flumekibanaelasticsearch分布式
1、软件介绍1.1、flume1.1.1、flume介绍1)flume概念1、flume是一个分布式的日志收集系统,具有高可靠、高可用、事务管理、失败重启等功能。数据处理速度快,完全可以用于生产环境;2、flume的核心是agent。agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,再发送到目的地;3、agent里面包含3个核心组件:source、channel
- Hive数据仓库中的数据导出到MySQL的数据表不成功
sin2201
出错问题数据仓库hivemysql
可能的原因:(1)没有下载flume和sqoop(2)权限问题:因为MySQL数据库拒绝了root用户从hadoop3主机的连接请求,root用户没有从hadoop3主机进行连接的权限解决:通过MySQL的授权命令来授予权限mysql>GRANTALLPRIVILEGESONsqoop_weblog.*TO'root'@'hadoop3'IDENTIFIEDBY'2020';QueryOK,0ro
- python消费kafka数据nginx日志实时_Openresty+Lua+Kafka实现日志实时采集
weixin_39997311
简介在很多数据采集场景下,Flume作为一个高性能采集日志的工具,相信大家都知道它。许多人想起Flume这个组件能联想到的大多数都是Flume跟Kafka相结合进行日志的采集,这种方案有很多他的优点,比如高性能、高吞吐、数据可靠性等。但是我们如果要求对日志进行实时的采集,这显然不是一个好的解决方案。原因如下:就目前来说,Flume能支持实时监控一个目录的数据文件,一旦对某个目录的文件采集完成,就会
- openresty+lua实现实时写kafka
sky@梦幻未来
大数据openrestynginxopenrestylua
一.背景在使用openresty+lua+nginx+flume,通过定时切分日志发送kafka的方式无法满足实时性的情况下,小编开始研究openresty+lua+nginx+kafka实时写kafka,从而达到数据实时性,和高性能保证。二.实现1.openresty安装nginx,以及lua的使用请看博主上一篇博客https://blog.csdn.net/qq_29497387/articl
- SeaTunnel 与 DataX 、Sqoop、Flume、Flink CDC 对比
不二人生
#数据集成工具SeaTunnel
文章目录SeaTunnel与DataX、Sqoop、Flume、FlinkCDC对比同类产品横向对比2.1、高可用、健壮的容错机制2.2、部署难度和运行模式2.3、支持的数据源丰富度2.4、内存资源占用2.5、数据库连接占用2.6、自动建表2.7、整库同步2.8、断点续传2.9、多引擎支持2.10、数据转换算子2.11、性能2.12、离线同步2.13、增量同步&实时同步2.14、CDC同步2.15
- flume系列之:flume落cos
快乐骑行^_^
日常分享专栏flume系列
flume系列之:flume落cos一、参考文章二、安装cosjar包三、添加hadoop-cos的相关配置四、flume环境添加hadoop类路径五、使用cos路径六、启动/重启flume一、参考文章Kafka数据通过Flume存储到HDFS或COSflumetocos使用指南二、安装cosjar包将对应hadoop版本的hadoop-cos的jar包(hadoop-cos-{hadoop.ve
- Flume 简介01 作用 核心概念 事务机制 安装 配置入门实战
湖中屋
Flumeflume
Flume1.业务系统为什么会产生用户行为日志,怎么产生的用户行文日志:每一次访问的行为(访问、搜索)产生的日志记录用户行为日志的目的:1.商家会精准的给你呈现符合你的个人界面2.商家会给你个人添加用户标签,更加精准的分析埋点等2.flume用来做什么的(采集传输数据的,分布式的,可靠的)ApacheFlume是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
武子康
大数据离线数仓大数据数据仓库java后端hadoophive
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- kafka直接对接nginx
Lu_Xiao_Yue
nginxkafka
很多时候我们要对nginx产生的日志进行分析都是通过flume监控nginx产生的日志,通过flume把日志文件发送该kafka,flume作为生产者,但是这种方式的缺点就是可能效率会比较慢,除此之外还可以使用kafka直接对接nginx,nginx作为生产者,把log日志直接对接到kafka的某些分区中,这种方法的效率比较高,但是缺点就是可能会出现数据丢失,可以通过把nginx的日志进行一份给k
- 大数据新视界 --大数据大厂之大数据实战指南:Apache Flume 数据采集的配置与优化秘籍
青云交
大数据新视界数据库ApacheFlume数据采集安装部署配置优化高级功能大数据工具集成
亲爱的朋友们,热烈欢迎你们来到青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。本博客的精华专栏:大数
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- Flume:大规模日志收集与数据传输的利器
傲雪凌霜,松柏长青
后端大数据flume大数据
Flume:大规模日志收集与数据传输的利器在大数据时代,随着各类应用的不断增长,产生了海量的日志和数据。这些数据不仅对业务的健康监控至关重要,还可以通过深入分析,帮助企业做出更好的决策。那么,如何高效地收集、传输和存储这些海量数据,成为了一项重要的挑战。今天我们将深入探讨ApacheFlume,它是如何帮助我们应对这些挑战的。一、Flume概述ApacheFlume是一个分布式、可靠、可扩展的日志
- 解决flume在抽取不断产生的日志文件时,hdfs上出现很多小文件的问题
lzhlizihang
flumehdfs大数据
问题在使用flume时,需要编写conf文件,然后执行,明明sinks已经指定了roll的三个参数:a1.sinks.k1.hdfs.rollInterval=0(根据写入时间来切割)a1.sinks.k1.hdfs.rollSize=0(根据写入的文件大小来切割)a1.sinks.k1.hdfs.rollCount=0(根据Event数量来切割)其中0代表不根据其属性来切割文件但是hdfs上还会
- pyspark kafka mysql_数据平台实践①——Flume+Kafka+SparkStreaming(pyspark)
weixin_39793638
pysparkkafkamysql
蜻蜓点水Flume——数据采集如果说,爬虫是采集外部数据的常用手段的话,那么,Flume就是采集内部数据的常用手段之一(logstash也是这方面的佼佼者)。下面介绍一下Flume的基本构造。Agent:包含Source、Channel和Sink的主体,它是这3个组件的载体,是组成Flume的数据节点。Event:Flume数据传输的基本单元。Source:用来接收Event,并将Event批量传
- 【大数据Big DATA】大数据解决方案,提供完整的大数据采集,大数据存储,大数据处理,具体业务应用解决方案
_晓夏_
JAVA大数据大数据解决方案大数据BIGDATA大数据采集大数据存储大数据处理大数据分析
大数据解决方案是指利用大数据技术,结合企业实际业务需求,为企业提供数据采集、存储、处理、分析和报告等一站式服务,以帮助企业更好地利用大数据提高运营效率、优化决策制定。以下是一些常见的大数据解决方案:一、数据采集数据采集是大数据解决方案的起点,涉及从各种数据源中抓取和收集数据。常见的大数据采集工具包括Flume、Scribd等,这些工具可以帮助企业快速、高效地采集各类数据。二、数据存储大数据存储解决
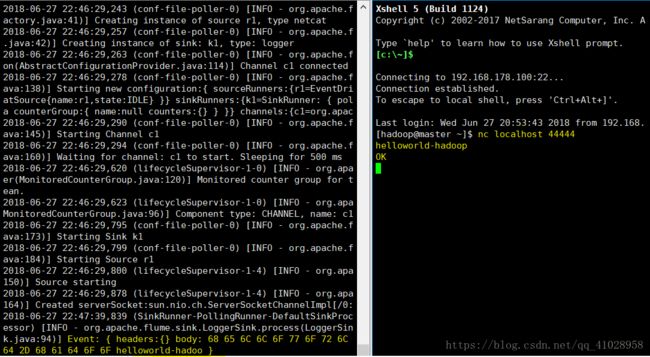
- 大数据技术之Flume 企业开发案例——自定义 Interceptor(8)
大数据深度洞察
Flumeflume大数据
目录自定义Interceptor1)案例需求2)需求分析3)实现步骤创建一个Maven项目,并引入以下依赖。定义CustomInterceptor类并实现Interceptor接口。编辑flume配置文件分别在hadoop12,hadoop13,hadoop14上启动flume进程,注意先后顺序。在hadoop12使用netcat向localhost:44444发送字母和数字。观察hadoop13
- 大数据基础之Flume——Flume基础及Flume agent配置以及自定义拦截器
Clozzz
Flume大数据flumehadoop
Flume简介Flume用于将多种来源的日志以流的方式传输至Hadoop或者其他目的地 -一种可靠、可用的高效分布式数据收集服务Flume拥有基于数据流上的简单灵活架构,支持容错、故障转移与恢复由Cloudera2009年捐赠给Apache,现为Apache顶级项目Flume架构Client:客户端,数据产生的地方,如Web服务器Event:事件,指通过Agent传输的单个数据包,如日志数据通常对
- 关于旗正规则引擎下载页面需要弹窗保存到本地目录的问题
何必如此
jsp超链接文件下载窗口
生成下载页面是需要选择“录入提交页面”,生成之后默认的下载页面<a>标签超链接为:<a href="<%=root_stimage%>stimage/image.jsp?filename=<%=strfile234%>&attachname=<%=java.net.URLEncoder.encode(file234filesourc
- 【Spark九十八】Standalone Cluster Mode下的资源调度源代码分析
bit1129
cluster
在分析源代码之前,首先对Standalone Cluster Mode的资源调度有一个基本的认识:
首先,运行一个Application需要Driver进程和一组Executor进程。在Standalone Cluster Mode下,Driver和Executor都是在Master的监护下给Worker发消息创建(Driver进程和Executor进程都需要分配内存和CPU,这就需要Maste
- linux上独立安装部署spark
daizj
linux安装spark1.4部署
下面讲一下linux上安装spark,以 Standalone Mode 安装
1)首先安装JDK
下载JDK:jdk-7u79-linux-x64.tar.gz ,版本是1.7以上都行,解压 tar -zxvf jdk-7u79-linux-x64.tar.gz
然后配置 ~/.bashrc&nb
- Java 字节码之解析一
周凡杨
java字节码javap
一: Java 字节代码的组织形式
类文件 {
OxCAFEBABE ,小版本号,大版本号,常量池大小,常量池数组,访问控制标记,当前类信息,父类信息,实现的接口个数,实现的接口信息数组,域个数,域信息数组,方法个数,方法信息数组,属性个数,属性信息数组
}
&nbs
- java各种小工具代码
g21121
java
1.数组转换成List
import java.util.Arrays;
Arrays.asList(Object[] obj); 2.判断一个String型是否有值
import org.springframework.util.StringUtils;
if (StringUtils.hasText(str)) 3.判断一个List是否有值
import org.spring
- 加快FineReport报表设计的几个心得体会
老A不折腾
finereport
一、从远程服务器大批量取数进行表样设计时,最好按“列顺序”取一个“空的SQL语句”,这样可提高设计速度。否则每次设计时模板均要从远程读取数据,速度相当慢!!
二、找一个富文本编辑软件(如NOTEPAD+)编辑SQL语句,这样会很好地检查语法。有时候带参数较多检查语法复杂时,结合FineReport中生成的日志,再找一个第三方数据库访问软件(如PL/SQL)进行数据检索,可以很快定位语法错误。
- mysql linux启动与停止
墙头上一根草
如何启动/停止/重启MySQL一、启动方式1、使用 service 启动:service mysqld start2、使用 mysqld 脚本启动:/etc/inint.d/mysqld start3、使用 safe_mysqld 启动:safe_mysqld&二、停止1、使用 service 启动:service mysqld stop2、使用 mysqld 脚本启动:/etc/inin
- Spring中事务管理浅谈
aijuans
spring事务管理
Spring中事务管理浅谈
By Tony Jiang@2012-1-20 Spring中对事务的声明式管理
拿一个XML举例
[html]
view plain
copy
print
?
<?xml version="1.0" encoding="UTF-8"?>&nb
- php中隐形字符65279(utf-8的BOM头)问题
alxw4616
php中隐形字符65279(utf-8的BOM头)问题
今天遇到一个问题. php输出JSON 前端在解析时发生问题:parsererror.
调试:
1.仔细对比字符串发现字符串拼写正确.怀疑是 非打印字符的问题.
2.逐一将字符串还原为unicode编码. 发现在字符串头的位置出现了一个 65279的非打印字符.
- 调用对象是否需要传递对象(初学者一定要注意这个问题)
百合不是茶
对象的传递与调用技巧
类和对象的简单的复习,在做项目的过程中有时候不知道怎样来调用类创建的对象,简单的几个类可以看清楚,一般在项目中创建十几个类往往就不知道怎么来看
为了以后能够看清楚,现在来回顾一下类和对象的创建,对象的调用和传递(前面写过一篇)
类和对象的基础概念:
JAVA中万事万物都是类 类有字段(属性),方法,嵌套类和嵌套接
- JDK1.5 AtomicLong实例
bijian1013
javathreadjava多线程AtomicLong
JDK1.5 AtomicLong实例
类 AtomicLong
可以用原子方式更新的 long 值。有关原子变量属性的描述,请参阅 java.util.concurrent.atomic 包规范。AtomicLong 可用在应用程序中(如以原子方式增加的序列号),并且不能用于替换 Long。但是,此类确实扩展了 Number,允许那些处理基于数字类的工具和实用工具进行统一访问。
- 自定义的RPC的Java实现
bijian1013
javarpc
网上看到纯java实现的RPC,很不错。
RPC的全名Remote Process Call,即远程过程调用。使用RPC,可以像使用本地的程序一样使用远程服务器上的程序。下面是一个简单的RPC 调用实例,从中可以看到RPC如何
- 【RPC框架Hessian一】Hessian RPC Hello World
bit1129
Hello world
什么是Hessian
The Hessian binary web service protocol makes web services usable without requiring a large framework, and without learning yet another alphabet soup of protocols. Because it is a binary p
- 【Spark九十五】Spark Shell操作Spark SQL
bit1129
shell
在Spark Shell上,通过创建HiveContext可以直接进行Hive操作
1. 操作Hive中已存在的表
[hadoop@hadoop bin]$ ./spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcom
- F5 往header加入客户端的ip
ronin47
when HTTP_RESPONSE {if {[HTTP::is_redirect]}{ HTTP::header replace Location [string map {:port/ /} [HTTP::header value Location]]HTTP::header replace Lo
- java-61-在数组中,数字减去它右边(注意是右边)的数字得到一个数对之差. 求所有数对之差的最大值。例如在数组{2, 4, 1, 16, 7, 5,
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/2541117420116135376632/
写了个java版的
public class GreatestLeftRightDiff {
/**
* Q61.在数组中,数字减去它右边(注意是右边)的数字得到一个数对之差。
* 求所有数对之差的最大值。例如在数组
- mongoDB 索引
开窍的石头
mongoDB索引
在这一节中我们讲讲在mongo中如何创建索引
得到当前查询的索引信息
db.user.find(_id:12).explain();
cursor: basicCoursor 指的是没有索引
&
- [硬件和系统]迎峰度夏
comsci
系统
从这几天的气温来看,今年夏天的高温天气可能会维持在一个比较长的时间内
所以,从现在开始准备渡过炎热的夏天。。。。
每间房屋要有一个落地电风扇,一个空调(空调的功率和房间的面积有密切的关系)
坐的,躺的地方要有凉垫,床上要有凉席
电脑的机箱
- 基于ThinkPHP开发的公司官网
cuiyadll
行业系统
后端基于ThinkPHP,前端基于jQuery和BootstrapCo.MZ 企业系统
轻量级企业网站管理系统
运行环境:PHP5.3+, MySQL5.0
系统预览
系统下载:http://www.tecmz.com
预览地址:http://co.tecmz.com
各种设备自适应
响应式的网站设计能够对用户产生友好度,并且对于
- Transaction and redelivery in JMS (JMS的事务和失败消息重发机制)
darrenzhu
jms事务承认MQacknowledge
JMS Message Delivery Reliability and Acknowledgement Patterns
http://wso2.com/library/articles/2013/01/jms-message-delivery-reliability-acknowledgement-patterns/
Transaction and redelivery in
- Centos添加硬盘完全教程
dcj3sjt126com
linuxcentoshardware
Linux的硬盘识别:
sda 表示第1块SCSI硬盘
hda 表示第1块IDE硬盘
scd0 表示第1个USB光驱
一般使用“fdisk -l”命
- yii2 restful web服务路由
dcj3sjt126com
PHPyii2
路由
随着资源和控制器类准备,您可以使用URL如 http://localhost/index.php?r=user/create访问资源,类似于你可以用正常的Web应用程序做法。
在实践中,你通常要用美观的URL并采取有优势的HTTP动词。 例如,请求POST /users意味着访问user/create动作。 这可以很容易地通过配置urlManager应用程序组件来完成 如下所示
- MongoDB查询(4)——游标和分页[八]
eksliang
mongodbMongoDB游标MongoDB深分页
转载请出自出处:http://eksliang.iteye.com/blog/2177567 一、游标
数据库使用游标返回find的执行结果。客户端对游标的实现通常能够对最终结果进行有效控制,从shell中定义一个游标非常简单,就是将查询结果分配给一个变量(用var声明的变量就是局部变量),便创建了一个游标,如下所示:
> var
- Activity的四种启动模式和onNewIntent()
gundumw100
android
Android中Activity启动模式详解
在Android中每个界面都是一个Activity,切换界面操作其实是多个不同Activity之间的实例化操作。在Android中Activity的启动模式决定了Activity的启动运行方式。
Android总Activity的启动模式分为四种:
Activity启动模式设置:
<acti
- 攻城狮送女友的CSS3生日蛋糕
ini
htmlWebhtml5csscss3
在线预览:http://keleyi.com/keleyi/phtml/html5/29.htm
代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>攻城狮送女友的CSS3生日蛋糕-柯乐义<
- 读源码学Servlet(1)GenericServlet 源码分析
jzinfo
tomcatWebservlet网络应用网络协议
Servlet API的核心就是javax.servlet.Servlet接口,所有的Servlet 类(抽象的或者自己写的)都必须实现这个接口。在Servlet接口中定义了5个方法,其中有3个方法是由Servlet 容器在Servlet的生命周期的不同阶段来调用的特定方法。
先看javax.servlet.servlet接口源码:
package
- JAVA进阶:VO(DTO)与PO(DAO)之间的转换
snoopy7713
javaVOHibernatepo
PO即 Persistence Object VO即 Value Object
VO和PO的主要区别在于: VO是独立的Java Object。 PO是由Hibernate纳入其实体容器(Entity Map)的对象,它代表了与数据库中某条记录对应的Hibernate实体,PO的变化在事务提交时将反应到实际数据库中。
实际上,这个VO被用作Data Transfer
- mongodb group by date 聚合查询日期 统计每天数据(信息量)
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
/* 1 */
{
"_id" : ObjectId("557ac1e2153c43c320393d9d"),
"msgType" : "text",
"sendTime" : ISODate("2015-06-12T11:26:26.000Z")
- java之18天 常用的类(一)
Luob.
MathDateSystemRuntimeRundom
System类
import java.util.Properties;
/**
* System:
* out:标准输出,默认是控制台
* in:标准输入,默认是键盘
*
* 描述系统的一些信息
* 获取系统的属性信息:Properties getProperties();
*
*
*
*/
public class Sy
- maven
wuai
maven
1、安装maven:解压缩、添加M2_HOME、添加环境变量path
2、创建maven_home文件夹,创建项目mvn_ch01,在其下面建立src、pom.xml,在src下面简历main、test、main下面建立java文件夹
3、编写类,在java文件夹下面依照类的包逐层创建文件夹,将此类放入最后一级文件夹
4、进入mvn_ch01
4.1、mvn compile ,执行后会在