日常面试总结+1(杭州某某公司)
今日面试:
- 日常总结
ps:原本是昨天晚上9点多打来的电话面试,因为自己在外面不方便,所以就推迟到了今天下午7点钟,面试虽然不是很理想,也不知道会不会第二面,小菜鸡有点小期待,不过算是这几次面试以来算看的过去的一面。
博客目的:
<第一> : 面临面试的童鞋们可以偶尔瞅瞅我的笔记,若能从这里收获到一点,开心万分<第二> : 作为学习的一种record,时常翻一翻,慢慢成长~~~~
让我来理一理今天所问到的一些问题昂~
1. 没有自我介绍
(不知道是忘了还是什么原因,电话那头有小孩子的声音,可能在家中)
2. 介绍项目:一如既往,遇到的难点:
还是会问高并发的问题怎么解决,平台付款问题要怎么解决,是否要借助第三方平台,面试官提示的提了下可以用redis处理多人抢单的问题,redis处理是单线程还是多线程,我回答了单线程,,巴拉巴拉一堆(但其实对redis只是了解过,不怎么会用,痛!!)
3. 常用的线程池有哪些?
Java通过Executors提供四种线程池,分别为:
(1) newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。 可能导致内存溢出,一般使用newFixedThreadPool代替
(2) newFixedThreadPool 创建一个固定大小的线程池,可控制线程最大并发数,超出的线程会在队列中等待。
(3) newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
(4) newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
(5)newSingleThreadScheduledExecutor
创建只有一条线程的线程池,他可以在指定延迟后执行线程任务
(6)newWorkStealingPool(这个是在jdk1.8出来的)会更加所需的并行层次来动态创建和关闭线程。它同样会试图减少任务队列的大小,所以比较适于高负载的环境。同样也比较适用于当执行的任务会创建更多任务,如递归任务。适合使用在很耗时的操作,但是newWorkStealingPool不是ThreadPoolExecutor的扩展,它是新的线程池类ForkJoinPool的扩展,但是都是在统一的一个Executors类中实现,由于能够合理的使用CPU进行对任务操作(并行操作),所以适合使用在很耗时的任务中。
4. Hashmap和Hashtable的区别?
共性:都实现了Map接口。
区别:
(1)继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。
(2)线程安全性不同
Hashtable的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。
(3)提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
(4)key和value是否允许null值
Hashtable中,key和value都不允许出现null值。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
(5)两个遍历方式的内部实现上不同
HashMap使用了 Iterator;Hashtable使用 Iterator,Enumeration两种方式 。
(6)hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
(7)内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,增加的方式是 old*2+1;而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
5.Hashmap底层实现原理,Hashmap是怎么判断键值为空的?怎么处理?Hashmap是怎么扩容的?
如何判断键植为空:
containsKey2oolean containsKey(Object key)如果此映射包含指定键的映射关系,则返回 true。更确切地讲,当且仅当此映射包含针对满足 (k为空则k等于空,否则进行key.equals(k)) 的键 k 的映射关系时,返回 true。(最多只能有一个这样的映射关系)。
若抛出:
ClassCastException - 如果该键对于此映射是不合适的类型(可选)
NullPointerException - 如果指定键为 null 并且此映射不允许 null 键(可选)
package demo;
import java.util.HashMap;
import java.util.Map;
public class fordemo
{
public static void main(String[] args)
{
Map<String, String> paramMap=new HashMap<String, String>();
paramMap.put("bc", "aa");
paramMap.put("a", "bb");
System.out.println(paramMap.containsKey("b"));--返回false
System.out.println(paramMap.containsKey("a"));--返回true
}
}
containsValue:
package demo;
import java.util.HashMap;
import java.util.Map;
public class fordemo
{
public static void main(String[] args)
{
Map<String, String> paramMap=new HashMap<String, String>();
paramMap.put("1", "b");
paramMap.put("2", "b");
paramMap.put("3", "ab");
paramMap.put("4", "cc");
System.out.println(paramMap.containsValue("b"));--返回true
System.out.println(paramMap.containsValue("a"));--返回false
System.out.println(paramMap.containsValue("cc"));--返回true
}
}
Hash原理就不做多赘述了,扩容是:当链表数组的容量超过初始容量的(负载因子)0.75时,再散列rehash将链表数组扩大2倍,把原链表数组的搬移到新的数组中(此时要重新计算键的hashcode)
6. JVM中垃圾回收算法都有哪些,都做下介绍以及优缺点,用在哪些区域?
先做可达性分析: 从根(GC Roots)的对象作为起始点,开始向下搜索,搜索所走过的路径称为“引用链”,当一个对象到GC Roots没有任何引用链相连(用图论的概念来讲,就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。
JVM虚拟机不采用引用计数法,只通过可达性分析进行垃圾回收
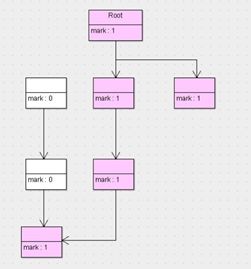
(1)、标记——清除算法
遍历所有的GC Root,分别标记处可达的对象和不可达的对象,然后将不可达的对象回收。
JVM将会停止应用程序的运行并开启GC线程,然后开始进行标记工作
缺点是:效率低、回收得到的空间不连续
(2)、复制算法(年轻代)
将内存分为两块,每次只使用一块。当这一块内存满了,就将还存活的对象复制到另一块上,并且严格按照内存地址排列,然后把已使用的那块内存统一回收。适合做新生代的GC
优点是:能够得到连续的内存空间
缺点是:浪费了一半内存
(3)标记-整理算法:(老年代的GC)
它在标记-清除算法的基础上做了一些优化。和标记-清除算法一样,标记-压缩算法也首先需要从根节点开始,对所有可达对象做一次标记;但之后,它并不简单的清理未标记的对象,而是将所有的存活对象压缩到内存的一端;之后,清理边界外所有的空间
• 标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
• 整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
标记/整理算法不仅可以弥补标记/清除算法当中,内存区域分散的缺点,也消除了复制算法当中,内存减半的高额代价。
缺点:标记/整理算法唯一的缺点就是效率也不高。
不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记/整理算法要低于复制算法。
7. 什么情况导致Young区的内存会一直满?怎么解决这种现象?
这个问题我回答了内存泄漏,导致对象内存无法释放,但面试官的意思好像不是这个答案,我有点蒙~~我就先提了怎么解决这个问题,就说了可以配置年轻代和老年代的内存比例大小,让年轻代的比重适当增大,面试官:嗯,那怎样会导致新生代会有对象持续增多呢?你其实刚刚有提到一点,我:懵逼中,,,,然后一直在想问题的标准答案,如果大牛看得到我这个问题,还请评论解答下,感激不尽!!
8. 你知道的排序算法都有哪些?都是怎么实现的?(大致原理)+ 哪一种时间复杂度最小?哪一种空间复杂度最小?
我的回答:冒泡,归并,快排~~~大致讲了一下实现,快排时间复杂度最小,归并(递归)空间复杂度最小O(1)(我记得好像是这样的)
9. 死锁产生的必要条件?
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则
就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
下面说说那个检测方法,其实方法挺简单的。
有两个容器,一个用于保存线程正在请求的锁,一个用于保存线程已经持有的锁。每次加锁之前都会做如下检测:
检测当前正在请求的锁是否已经被其它线程持有,如果有,则把那些线程找出来;遍历第一步中返回的线程,检查自己持有的锁是否正被其中任何一个线程请求;如果第二步返回真,表示出现了死锁
死锁的解除与预防:
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划
10. 了解分布式锁吗?
(不了解哟)还没学到~~~
11. 了解数据库事务吗?
事物的四个特性(ACID)
(1)原子性(Atomicity):操作这些指令时,要么全部执行成功,要么全部不执行。只要其中一个指令执行失败,所有的指令都执行失败,数据进行回滚,回到执行指令前的数据状态。
ex:拿转账来说,假设用户A和用户B两者的钱加起来一共是20000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是20000,这就是事务的一致性。
(2)一致性(Consistency):事务的执行使数据从一个状态转换为另一个状态,但是对于整个数据的完整性保持稳定。
(3)隔离性(Isolation):隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
(4)持久性(Durability):当事务正确完成后,它对于数据的改变是永久性的。
ex:例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
11,当发生事务错误时,数据库会进行什么操作?
并发事务导致的问题:
在许多事务处理同一个数据时,如果没有采取有效的隔离机制,那么并发处理数据时,会带来一些的问题。
● 第一类丢失更新:
<撤销一个事务时,把其他事务已提交的更新数据覆盖>
ex:小明去银行柜台存钱,他的账户里原来的余额为100元,现在打算存入100元。在他存钱的过程中,银行年费扣了5元,余额只剩95元。突然他又想着这100元要用来请女朋友看电影吃饭,不打算存了。在他撤回存钱操作后,余额依然为他存钱之前的100元。所以那5块钱到底扣了谁的?
● 脏读:
<脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。>
ex:小明的银行卡余额里有100元。现在他打算用手机点一个外卖饮料,需要付款10元。但是这个时候,他的女朋友看中了一件衣服95元,她正在使用小明的银行卡付款。于是小明在付款的时候,程序后台读取到他的余额只有5块钱了,根本不够10元,所以系统拒绝了他的交易,告诉余额不足。但是小明的女朋友最后因为密码错误,无法进行交易。小明非常郁闷,明明银行卡里还有100元,怎么会余额不足呢?(他女朋友更郁闷。。。)
● 幻读也叫虚读:
<一个事务执行两次查询,第二次结果集包含第一次中没有或某些行已经被删除的数据,造成两次结果不一致,只是另一个事务在这两次查询中间插入或删除了数据造成的。>幻读是事务非独立执行时发生的一种现象。
eg:例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
● 不可重复读:
<一个事务两次读取同一行的数据,结果得到不同状态的结果,中间正好另一个事务更新了该数据,两次结果相异,不可被信任。>
eg:例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
Tips:不可重复读和脏读的区别:脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
Tips:幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
● 第二类丢失更新:
是不可重复读的特殊情况。如果两个事物都读取同一行,然后两个都进行写操作,并提交,第一个事物所做的改变就会丢失。
eg:小明和女朋友一起去逛街。女朋友看中了一支口红,(对,女朋友就是用来表现买买买的)小明大方的掏出了自己的银行卡,告诉女朋友:亲爱的,随便刷,随便买,我坐着等你。然后小明就坐在商城座椅上玩手机,等着女朋友。这个时候,程序员的聊天群里有人推荐了一本书,小明一看,哎呀,真是本好书,还是限量发行呢,我一定更要买到。于是小明赶紧找到购买渠道,进行付款操作。而同时,小明的女朋友也在不亦乐乎的买买买,他们同时进行了一笔交易操作,但是这个时候银行系统出了问题,当他们都付款成功后,却发现,银行只扣了小明的买书钱,却没有扣去女朋友此时交易的钱。哈哈哈,小明真是太开心了!
数据库事务的隔离级别
事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed 、Repeatable read 、Serializable 。而且,在事务的并发操作中可能会出现脏读,不可重复读,幻读。下面通过事例一一阐述它们的概念与联系。
Read uncommitted(最低级别,任何情况都无法保证。)
----->读未提交,顾名思义,就是一个事务可以读取另一个未提交事务的数据。
eg:老板要给程序员发工资,程序员的工资是3.6万/月。但是发工资时老板不小心按错了数字,按成3.9万/月,该钱已经打到程序员的户口,但是事务还没有提交,就在这时,程序员去查看自己这个月的工资,发现比往常多了3千元,以为涨工资了非常高兴。但是老板及时发现了不对,马上回滚差点就提交了的事务,将数字改成3.6万再提交。
Analyse:实际程序员这个月的工资还是3.6万,但是程序员看到的是3.9万。他看到的是老板还没提交事务时的数据。这就是脏读。
那怎么解决脏读呢?Read committed!读提交,能解决脏读问题。
Read committed(可避免脏读的发生。)
----->读提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。
eg:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(程序员事务开启),收费系统事先检测到他的卡里有3.6万,就在这个时候!!程序员的妻子要把钱全部转出充当家用,并提交。当收费系统准备扣款时,再检测卡里的金额,发现已经没钱了(第二次检测金额当然要等待妻子转出金额事务提交完)。程序员就会很郁闷,明明卡里是有钱的…
Analyse:这就是读提交,若有事务对数据进行更新(UPDATE)操作时,读操作事务要等待这个更新操作事务提交后才能读取数据,可以解决脏读问题。但在这个事例中,出现了一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读。
那怎么解决可能的不可重复读问题?Repeatable read !
Repeatable read(可避免脏读、不可重复读的发生。)
----->重复读,就是在开始读取数据(事务开启)时,不再允许修改操作
eg:程序员拿着信用卡去享受生活(卡里当然是只有3.6万),当他埋单时(事务开启,不允许其他事务的UPDATE修改操作),收费系统事先检测到他的卡里有3.6万。这个时候他的妻子不能转出金额了。接下来收费系统就可以扣款了。
Analyse:重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
什么时候会出现幻读?
eg:程序员某一天去消费,花了2千元,然后他的妻子去查看他今天的消费记录(全表扫描FTS,妻子事务开启),看到确实是花了2千元,就在这个时候,程序员花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子事务提交),发现花了1.2万元,似乎出现了幻觉,这就是幻读。
那怎么解决幻读问题?Serializable!
Serializable(可避免脏读、不可重复读、幻读的发生。) 序列化
----->Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
Tips:大多数数据库默认的事务隔离级别是Read committed,比如Sql Server , Oracle。
Mysql的默认隔离级别是Repeatable read。
Tips:隔离级别的设置只对当前链接有效。对于使用MySQL命令窗口而言,一个窗口就相当于一个链接,当前窗口设置的隔离级别只对当前窗口中的事务有效;对于JDBC操作数据库来说,一个Connection对象相当于一个链接,而对于Connection对象设置的隔离级别只对该Connection对象有效,与其他链接Connection对象无关。
Tips:设置数据库的隔离级别一定要是在开启事务之前。