Python基础教程(第3版)中文版 第20章 项目1: 自动添加标签(纯文本转HTML格式) (笔记2)
先上代码,
主模块markup.py
import sys, re
from handlers import *
from util import *
from rules import *
class Parser:
"""
A Parser 读入文本, 使用 rules and 控制 a handler.
"""
#初始化成员,handler,rules(),filters()
def __init__(self, handler):
self.handler = handler
self.rules = []
self.filters = []
#添加rule,方便扩展
def addRule(self, rule):
self.rules.append(rule)
#添加过滤器, 方便扩展
def addFilter(self, pattern, name):
def filter(block, handler):
return re.sub(pattern, handler.sub(name), block)
self.filters.append(filter)
#方法parse,读取文本(调用util.py的blocks(file))并分成block,
#使用循环用规则(rule)和过滤器(filter(block, handler)处理block,
def parse(self, file):
self.handler.start('document')
for block in blocks(file):
for filter in self.filters:
block = filter(block, self.handler)
for rule in self.rules:
if rule.condition(block):
if rule.action(block,
self.handler): break
self.handler.end('document')
#Parser派生出的具体的类(通过添加具体的规则和过滤器):用于添加HTML标记
class BasicTextParser(Parser):
def __init__(self, handler):
Parser.__init__(self, handler)
self.addRule(ListRule())
self.addRule(ListItemRule())
self.addRule(TitleRule())
self.addRule(HeadingRule())
self.addRule(ParagraphRule())
self.addFilter(r'\*(.+?)\*', 'emphasis')
self.addFilter(r'(http://[\.a-zA-Z/]+)', 'url')
self.addFilter(r'([\.a-zA-Z]+@[\.a-zA-Z]+[a-zA-Z]+)', 'mail')
#主程序:构造handler实例,构造parser(使用对应的handler)实例,调用parser的方法parser进行对文本的处理
handler = HTMLRenderer()
parser = BasicTextParser(handler)
parser.parse(sys.stdin)
控制模块
handlers.py
class Handler:
"""
Handler类是所有处理程序的基类。
"""
#方法callback根据指定的 前缀 和 名称 查找相应的方法。
def callback(self, prefix, name, *args):
method = getattr(self, prefix + name, None)
if callable(method): return method(*args)
#辅助方法start,调用callback
def start(self, name):
self.callback('start_', name)
#辅助方法end,调用callback
def end(self, name):
self.callback('end_', name)
#方法sub,不调用callback,而是返回一个函数
def sub(self, name):
def substitution(match):
result = self.callback('sub_', name, match)
if result is None: match.group(0)
return result
return substitution
class HTMLRenderer(Handler):
"""
用于渲染HTML的具体处理程序
"""
def start_document(self):
print('... ')
def end_document(self):
print('')
def start_paragraph(self):
print('')
def end_paragraph(self):
print('
')
def start_heading(self):
print('')
def end_heading(self):
print('
')
def start_list(self):
print('')
def end_list(self):
print('
')
def start_listitem(self):
print('')
def end_listitem(self):
print(' ')
def start_title(self):
print('')
def end_title(self):
print('
')
def sub_emphasis(self, match):
return '{}'.format(match.group(1))
def sub_url(self, match):
return '{}'.format(match.group(1), match.group(1))
def sub_mail(self, match):
return '{}'.format(match.group(1), match.group(1))
def feed(self, data):
print(data)
规则模块rules.py
class Rule:
"""
所有规则的基类
"""
def action(self, block, handler):
handler.start(self.type)
handler.feed(block)
handler.end(self.type)
return True
class HeadingRule(Rule):
"""
A heading is a single line that is at most 70 characters and
that doesn't end with a colon.
"""
type = 'heading'
def condition(self, block):
return not '\n' in block and len(block) <= 70 and not block[-1] == ':'
class TitleRule(HeadingRule):
"""
The title is the first block in the document, provided that
it is a heading.
"""
type = 'title'
first = True
def condition(self, block):
if not self.first: return False
self.first = False
return HeadingRule.condition(self, block)
class ListItemRule(Rule):
"""
A list item is a paragraph that begins with a hyphen. As part of the
formatting, the hyphen is removed.
"""
type = 'listitem'
def condition(self, block):
return block[0] == '-'
def action(self, block, handler):
handler.start(self.type)
handler.feed(block[1:].strip())
handler.end(self.type)
return True
class ListRule(ListItemRule):
"""
A list begins between a block that is not a list item and a
subsequent list item. It ends after the last consecutive list item.
"""
type = 'list'
inside = False
def condition(self, block):
return True
def action(self, block, handler):
if not self.inside and ListItemRule.condition(self, block):
handler.start(self.type)
self.inside = True
elif self.inside and not ListItemRule.condition(self, block):
handler.end(self.type)
self.inside = False
return False
class ParagraphRule(Rule):
"""
A paragraph is simply a block that isn't covered by any of the other rules.
"""
type = 'paragraph'
def condition(self, block):
return True
还有一个用于将文本转换成块(block)的模块util.py
def lines(file):
for line in file: yield line
yield '\n'
def blocks(file):
block = []
for line in lines(file):
if line.strip():
block.append(line)
elif block:
yield ''.join(block).strip()
block = []
用于测试的文本test_input.txt
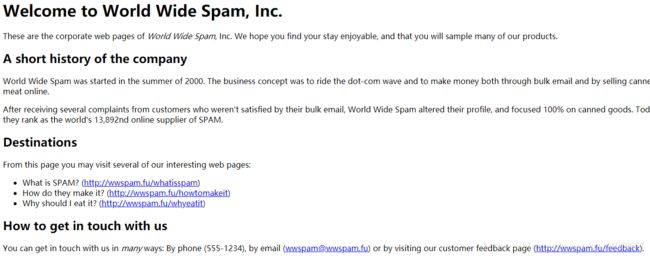
Welcome to World Wide Spam, Inc.
These are the corporate web pages of *World Wide Spam*, Inc. We hope
you find your stay enjoyable, and that you will sample many of our
products.
A short history of the company
World Wide Spam was started in the summer of 2000. The business
concept was to ride the dot-com wave and to make money both through
bulk email and by selling canned meat online.
After receiving several complaints from customers who weren't
satisfied by their bulk email, World Wide Spam altered their profile,
and focused 100% on canned goods. Today, they rank as the world's
13,892nd online supplier of SPAM.
Destinations
From this page you may visit several of our interesting web pages:
- What is SPAM? (http://wwspam.fu/whatisspam)
- How do they make it? (http://wwspam.fu/howtomakeit)
- Why should I eat it? (http://wwspam.fu/whyeatit)
How to get in touch with us
You can get in touch with us in *many* ways: By phone (555-1234), by
email (wwspam@wwspam.fu) or by visiting our customer feedback page
(http://wwspam.fu/feedback).
cmd中运行命令(进入文件所在目录),执行标记程序:python markup.py < test_input.txt > test_output.html
输出文件
test_output.html
打开效果(浏览器打开,(如果用文本编辑器(如记事本)打开就会看到添加了HTML标签的文本))